Arijit Ray's Webpage
Selected publications (all):
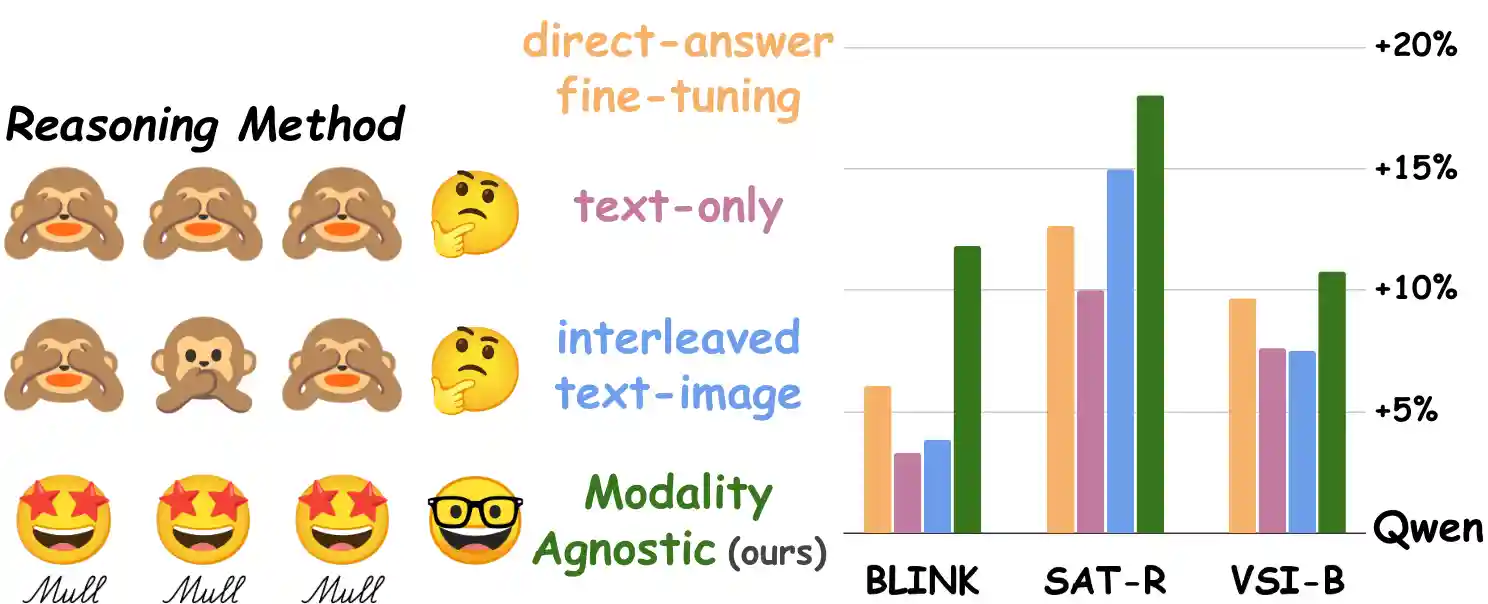
Mull-Tokens: Modality-Agnostic Latent Thinking
arXiv 2025
TL;DR: Instead of text reasoning or explicit image thoughts, using modality-agnostic thinking tokens pretrained using multimodal thoughts is more effective for visual reasoning tasks.

SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
arXiv 2025
TL;DR: Using simulators to create spatially-rich video training data for multimodal language models. Our 7B-parameter model fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on real-world spatial reasoning benchmarks.
GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
TL;DR: Use textual reasoning (e.g., one should grasp "handle" of cup to drink tea) and visual reasoning (e.g., in this image, the cup is grasped by the "handle") along with an object grasping dataset (data of 6 DOF arm positions to grasp objects) to generate high-level task description (e.g., how should I grasp cup to drink tea?) to precise 6DOF grasp data.

, Ellis Brown, Jiafei Duan, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A. Plummer, Ranjay Krishna*, Kuo-Hao Zeng*, Kate Saenko*
SAT: Dynamic Spatial Aptitude Training for Multimodal Language Models
TL;DR: Simulated spatial aptitude data (SAT) using 3D physics engines involving object and camera movements can improve spatial reasoning in real images and videos for MLMs while maintaining pretraining commonsense. When instruction-tuned on SAT, LLaVA-13B outperforms some larger MLMs like GPT4-V and Gemini-1.5-pro in spatial reasoning.
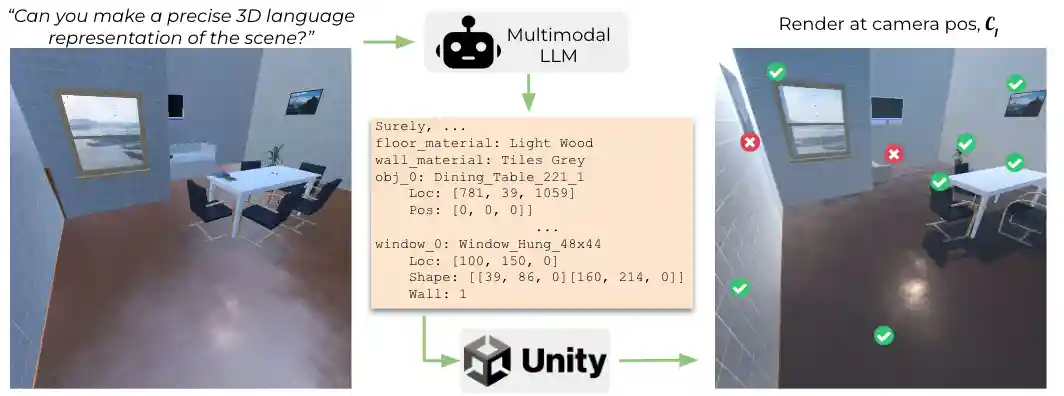
R2D3: Imparting Spatial Reasoning by Reconstructing 3D Scenes from 2D Images
Tech report 2024
TL;DR: A visual anchor with the corresponding 3D location in text helps multimodal language models perform more accurate 3D estimation.
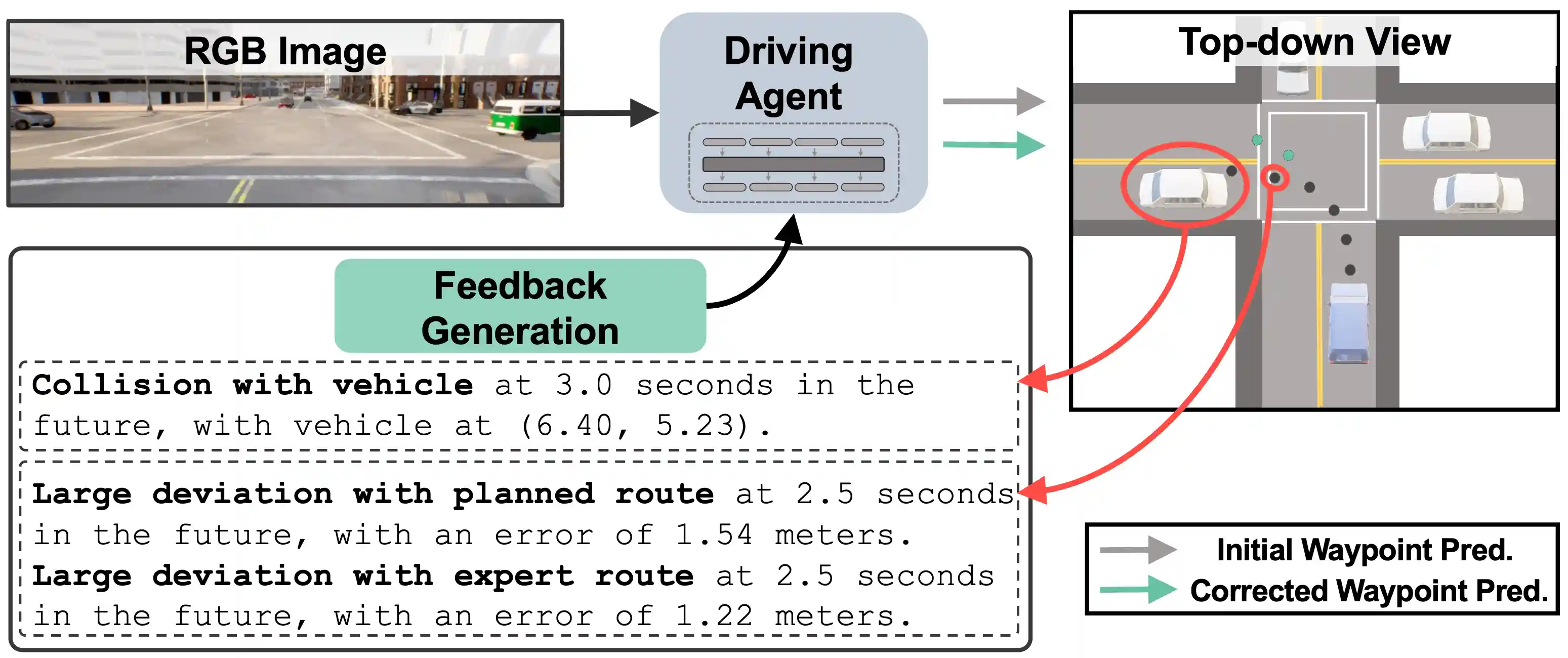
FED: Feedback-Guided Autonomous Driving
TL;DR: MLMs can benefit autonomous driving by understanding natural language feedback and refining the next waypoint prediction.
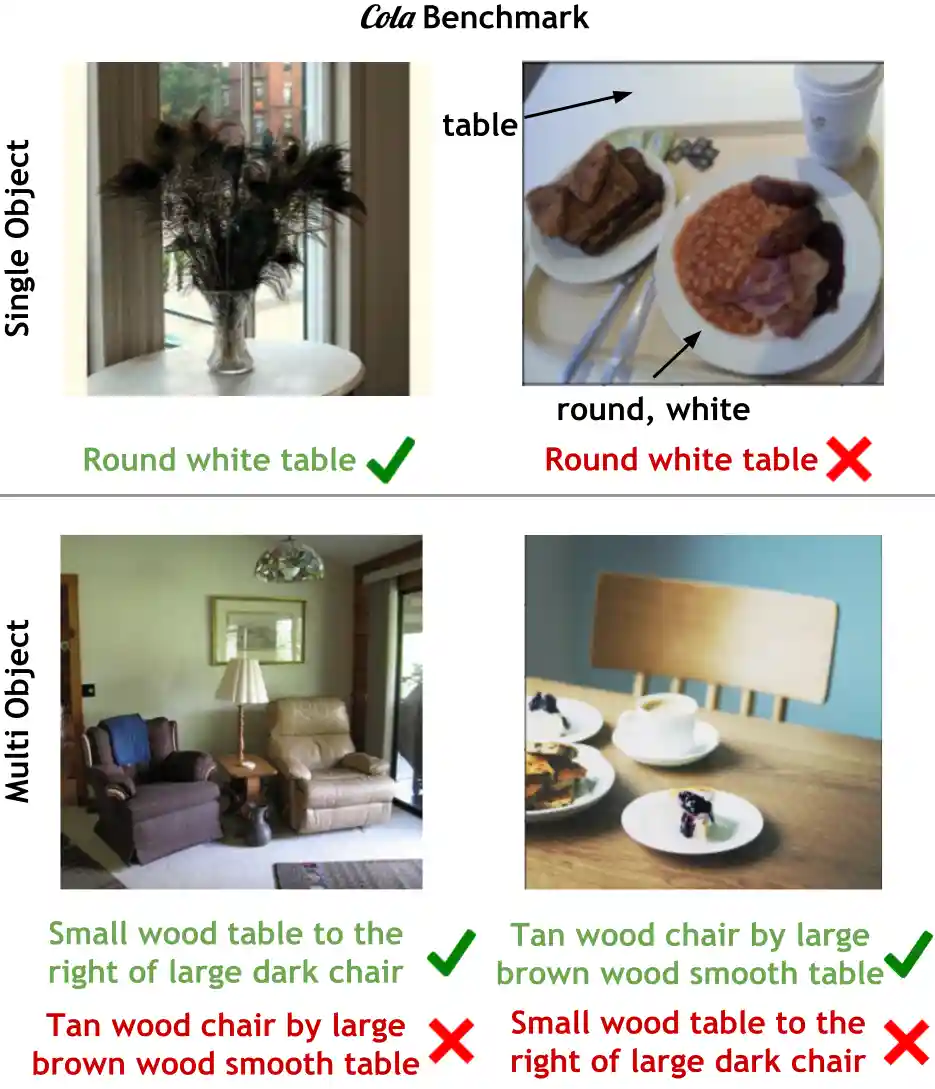
Cola: A Benchmark for Compositional Text-to-image Retrieval
TL;DR: Multimodal layers are the most responsible for compositional reasoning rather than the visual or textual encoders. Tuning multimodal layers over frozen representations are more effective than tuning similar amount of parameters in the individual encoders or even the entire model.

Lasagna: Layered Score Distillation for Disentangled Object Relighting
TL;DR: Synthetically generated examples using 3D graphics engines are effective in teaching physics-aware edits like relighting if we use score-distillation to avoid overfitting.

Socratis: Are Large Multimodal Models Emotionally Aware?
TL;DR: A preliminary benchmark to test MLMs on why different people may feel different emotions for diverse reasons while viewing the same image-text content.

User-targeted content generation using multimodal embeddings

Knowing What VQA Does Not: Pointing to Error-Inducing Regions to Improve Explanation Helpfulness

Sunny and Dark Outside?! Improving Answer Consistency in VQA through Entailed Question Generation
EMNLP 2019, also at CVPR-W 2019 VQA and Visual Dialog Workshop
TL;DR: Use a learned teacher module to reward VQA models for predicting consistent answers to entailed questions.

Question Relevance in VQA: Identifying Non-Visual And False-Premise Questions
TL;DR: Image captions are a surprisingly strong baseline to identify whether a question is relevant to an image or not.