HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding
![]()
1University of Chicago,
2Massachusetts Institute of Technology,
3UNC Chapel-Hill
4University of Illinois at Urbana-Champaign,
5Toyota Technological Institute at Chicago
*Equal Contribution
billchandler0226@gmail.com, zhuokai@uchicago.edu
Abstract
While large vision-language models (LVLMs) have demonstrated impressive capabilities in interpreting multi-modal contexts, they invariably suffer from object hallucinations (OH). We introduce HALC, a novel decoding algorithm designed to mitigate OH in LVLMs. HALC leverages distinct fine-grained optimal visual information in vision-language tasks and operates on both local and global contexts simultaneously. Specifically, HALC integrates a robust auto-focal grounding mechanism (locally) to correct hallucinated tokens on the fly, and a specialized beam search algorithm (globally) to significantly reduce OH while preserving text generation quality. Additionally, HALC can be integrated into any LVLMs as a plug-and-play module without extra training. Extensive experimental studies demonstrate HALC’s effectiveness in reducing OH, outperforming state-of-the-arts across four benchmarks. Code is released here.
Overview
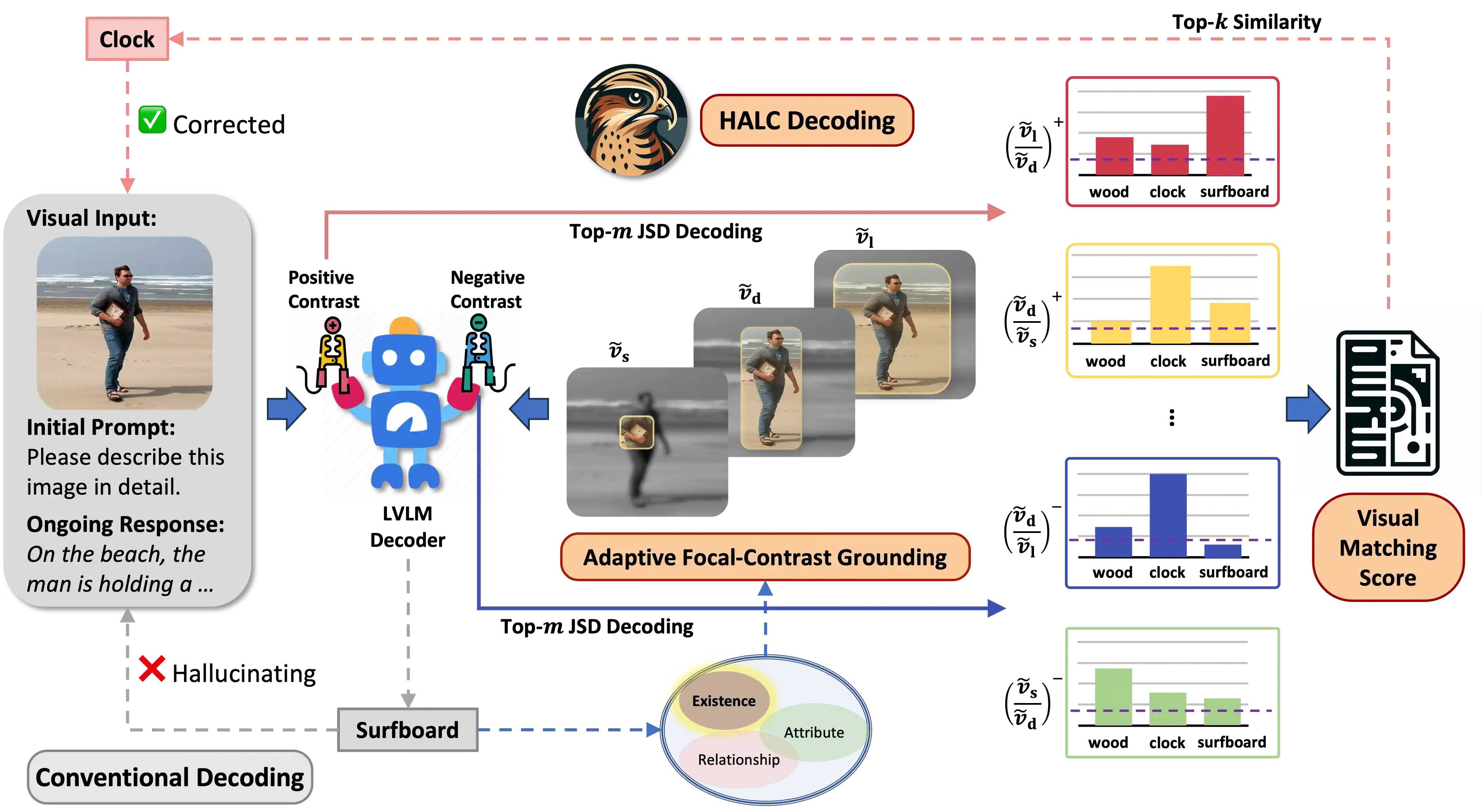
An overview of HALC. As LVLM autoregressively generates texts w.r.t. an image input (e.g., a man holding a clock on the beach), the conventional decoding method may hallucinate the clock as surfboard. However, HALC corrects this potential hallucination by first locating its visual grounding \( v_d \), then sample \( n \) distinctive yet overlapping FOVs (e.g., \( \tilde{v}_s \), \( \tilde{v}_d \), \( \tilde{v}_l \)).
Result
CHAIR Result
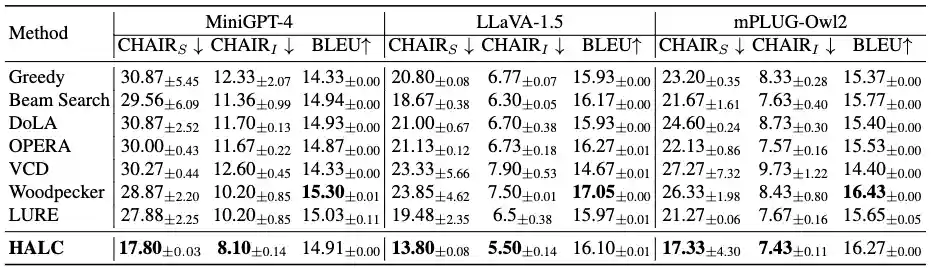
\( \text{CHAIR} \) evaluation results on MSCOCO dataset of LVLMs with different decoding baselines and SOTAs designed for mitigating OH. Lower \( \text{CHAIR}_S \) and \( \text{CHAIR}_I \) indicates less OH. Higher \( \text{BLEU} \) generally represent higher captioning quality, although existing work has reported weak correlation between \( \text{CHAIR} \) and text overlapping quality metrics. Bold indicates the best results of all methods.
POPE Result
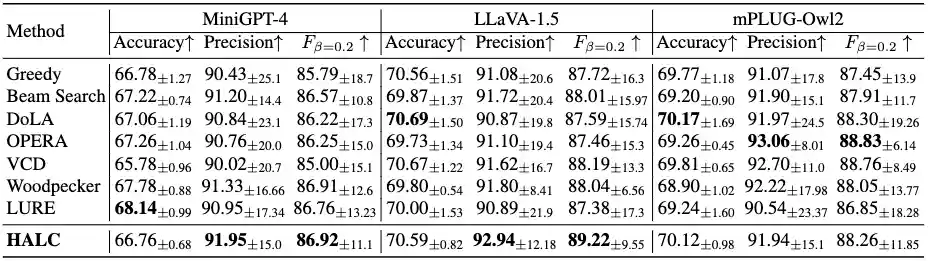
Proposed \( \text{OPOPE} \) evaluation results on MSCOCO dataset of LVLMs with different decoding baselines and SOTAs designed for mitigating OH. Higher accuracy, precision, and \(\text{F score} \) indicates better performance. Bold indicates the best results of all methods.
MME Benchmarks
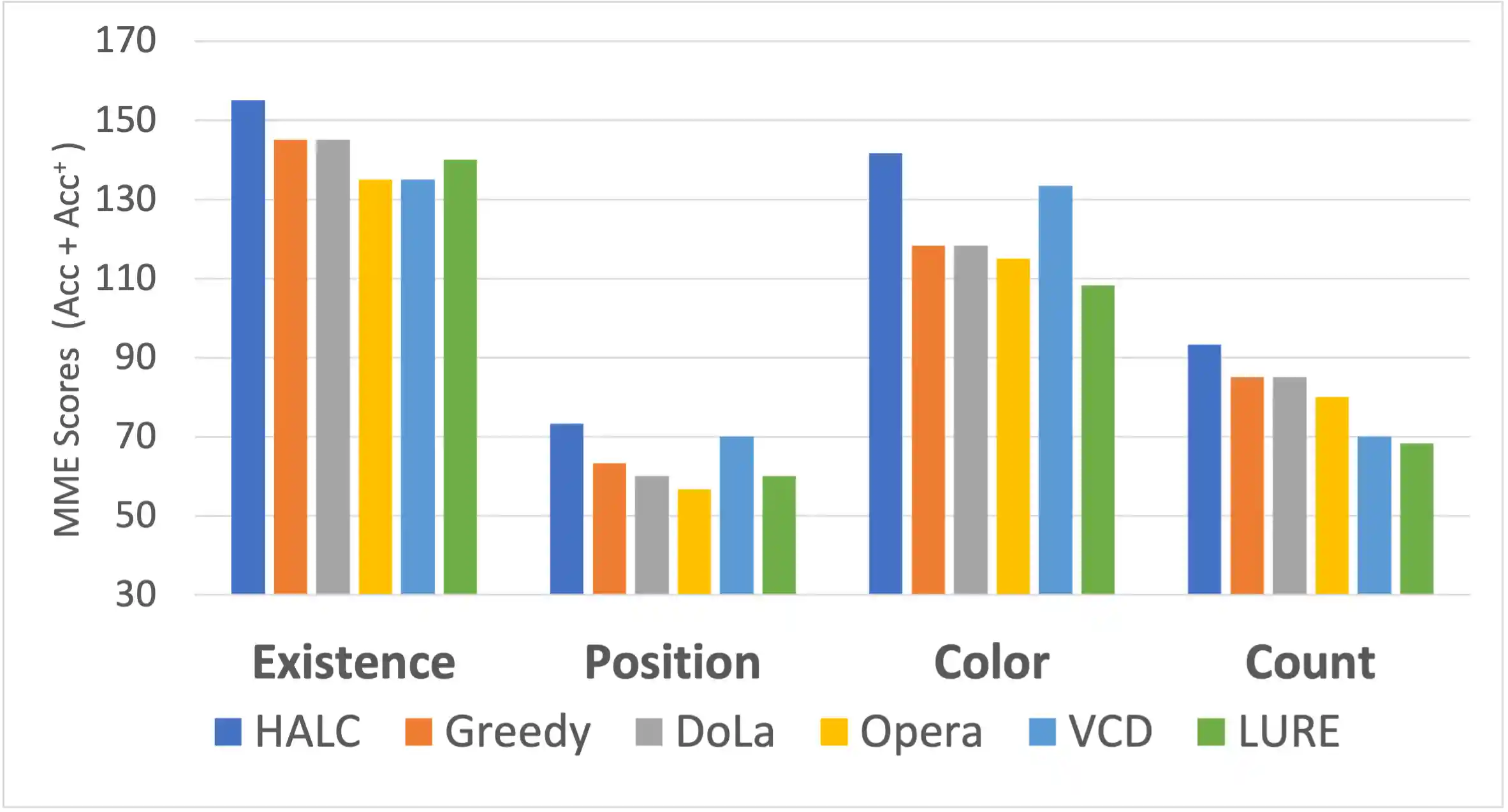
Comparison across OH baselines and SOTAs on four OH-critical MME subsets. All methods adopt MiniGPT-4 as LVLM backbone. HALC outperforms all other methods with a large margin: existence: \( +10.7\% \); position: \( +18.3\% \); color: \( +19.4\% \) and count: \(+20.2\% \) in average.
BibTeX
@article{chen2024halc,
title={HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding},
author={Chen, Zhaorun and Zhao, Zhuokai and Luo, Hongyin and Yao, Huaxiu and Li, Bo and Zhou, Jiawei},
journal={arXiv preprint arXiv:2403.00425},
year={2024}
}