Whole-Body Conditioned Egocentric Video Prediction
1 UC Berkeley (BAIR), 2 FAIR at Meta 3 New York University
*Indicates Equal Contribution
†Indicates Equal Advising
NeurIPS 2025
A World Model for Embodied Agents
What are the requirements?
To create a World Model for Embodied Agents , we need...
• …a real embodied agent...: complex actions.
- ❌ abstract control signals — ⬆️,⬇️,⬅️,➡️
- ✅ real, physical grounded complex action space
• … that act in the real world: complex scenarios.
- ❌ Aesthetic scene, stationary camera
- ✅ diverse real-life scenario, ego-centric view
Human, as the most complex agent in the world:
• Ego-centric view -> Intention
Humans routinely look first and act second—our eyes lock onto a goal, the brain runs a brief visual “simulation” of the outcome, and only then does the body move.
At every moment, our egocentric view both serves as input from the environment and reflects the intention/goal behind the next movement.

• Whole-body Control -> Physicality
When we consider our body movements, we should consider both actions of the feet (locomotion and navigation) and the actions of the hand (manipulation), or more generally, whole-body control.

Actions of the Feet

Actions of the Hand

Whole-body Control
What did we do?
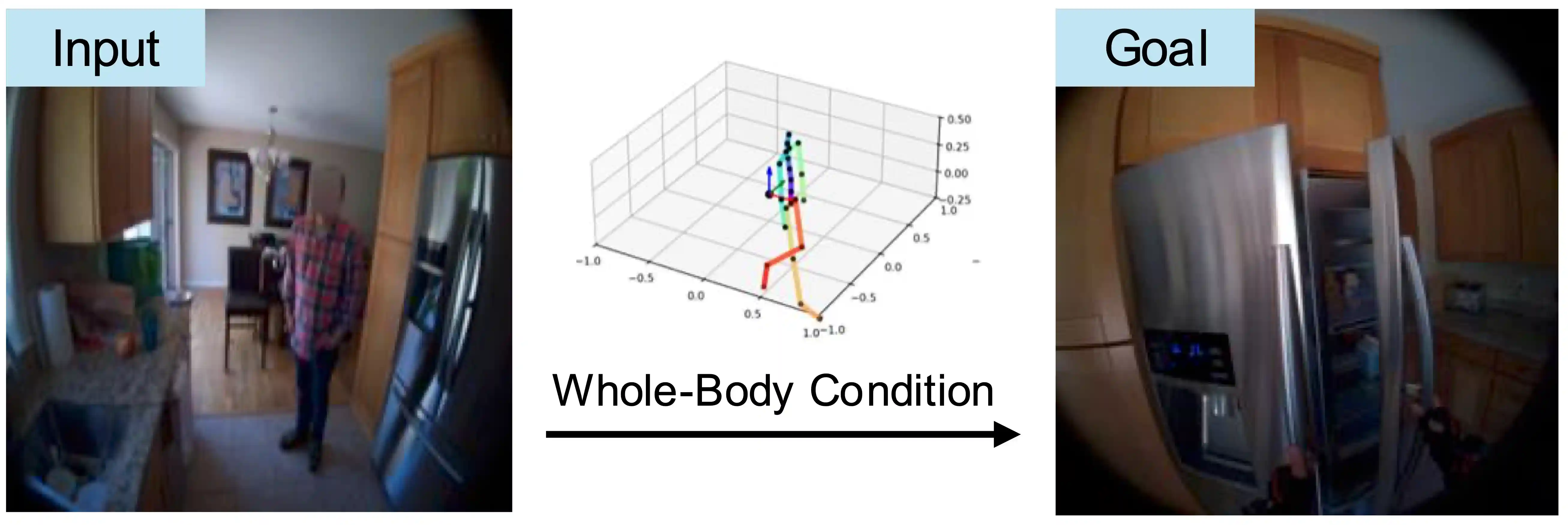
We trained a model, to Predict Egocentric Video from human Actions (PEVA).
By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, our model learns to simulate how physical human actions shape the environment from a first-person point of view. We train an auto-regressive conditional diffusion transformer on Nymeria, a large-scale dataset of real-world egocentric video and body pose capture. We further design a hierarchical evaluation protocol with increasingly challenging tasks, enabling a comprehensive analysis of the model's embodied prediction and control abilities. Our work represents an initial attempt to tackle the challenges of modeling complex real-world environments and embodied agent behaviors with video prediction from the perspective of a human.
Why it's hard?
• Action & Vision is Heavily Context Dependent
Same view can lead to different movements and vice versa — because humans act in complex, embodied, goal-directed environments.
• Human Control is High-Dimensional and Structured
Full-body motion spans 48+ DoF with hierarchical, time-dependent dynamics—not synthetic control codes.
• Egocentric View Reveals Intention—But Hides the Body
First-person vision reflects goals, but not motion execution—models must infer consequences from invisible physical actions.
• Perception Lags Behind Action
Visual feedback often comes seconds later, requiring long-horizon prediction and temporal reasoning.
Results
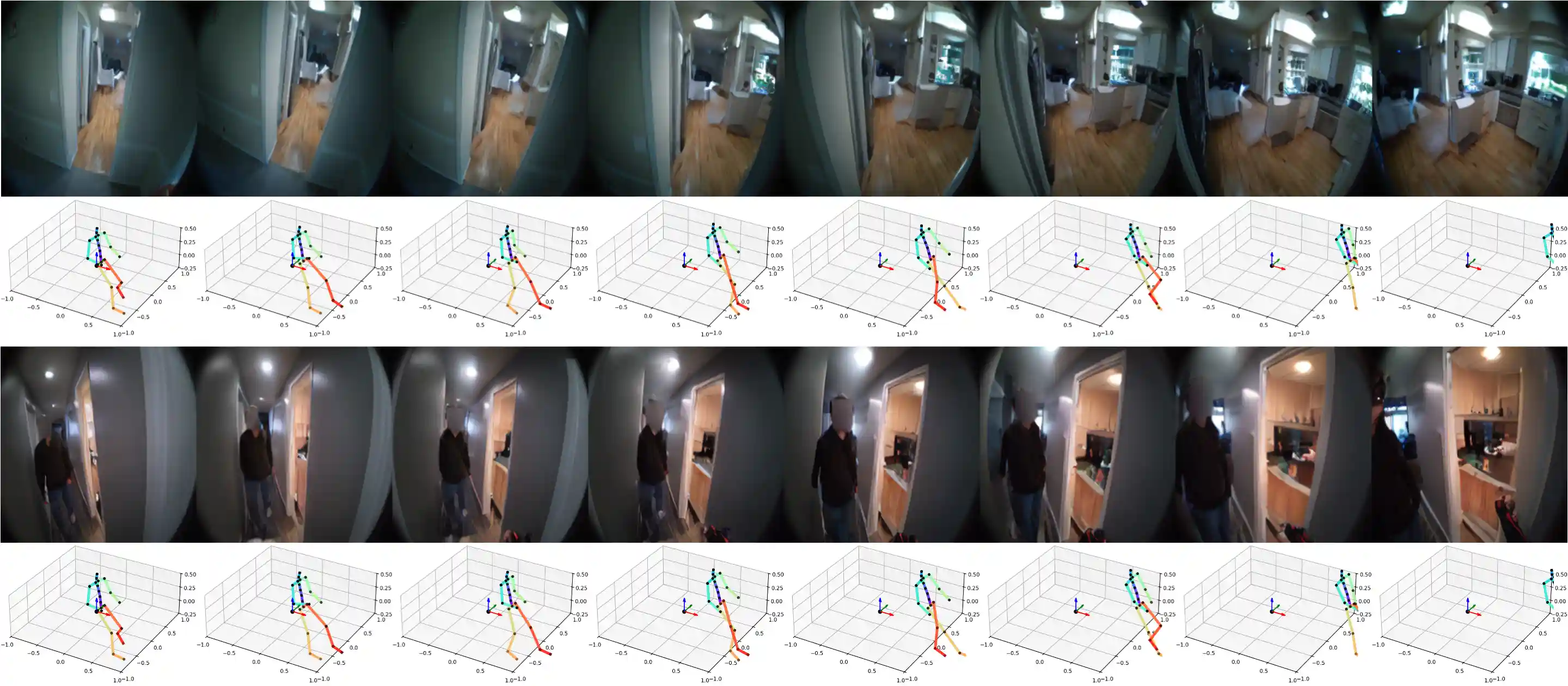
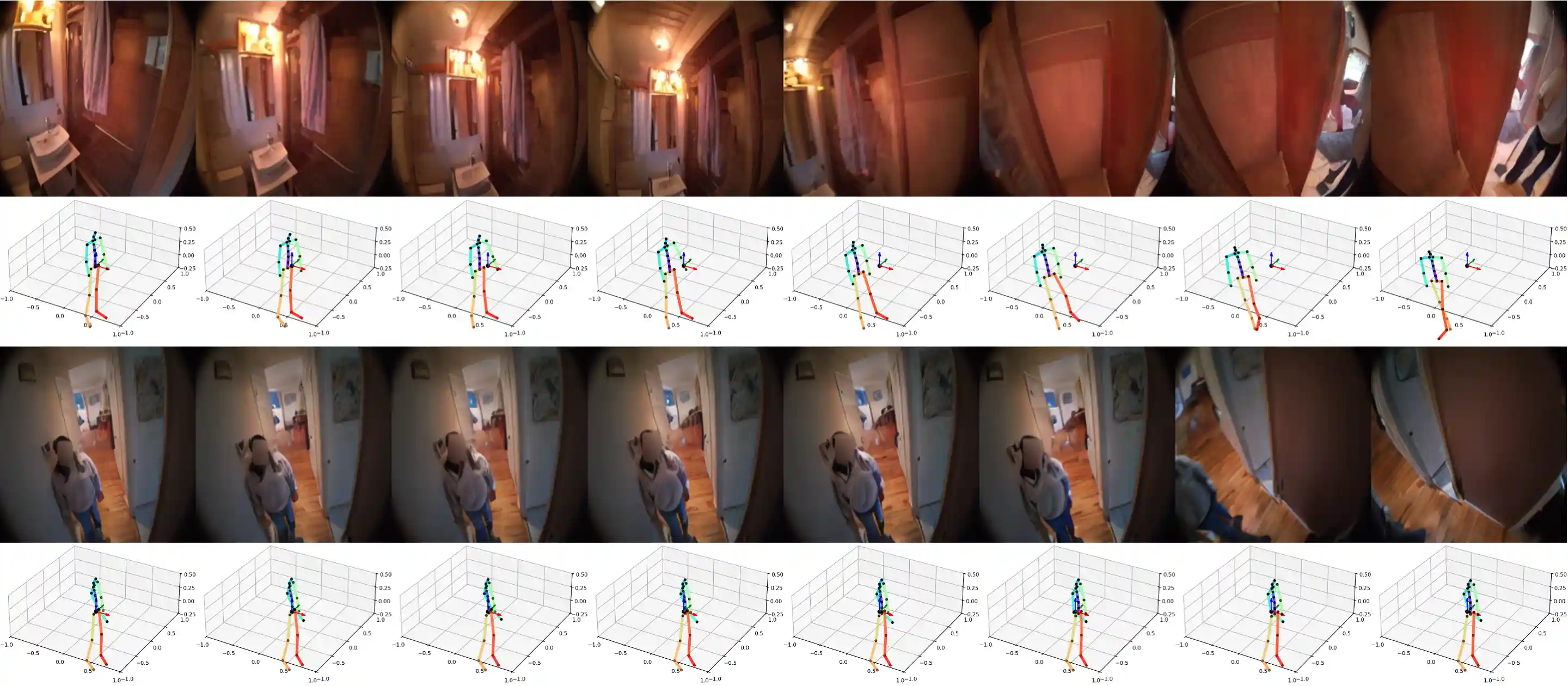
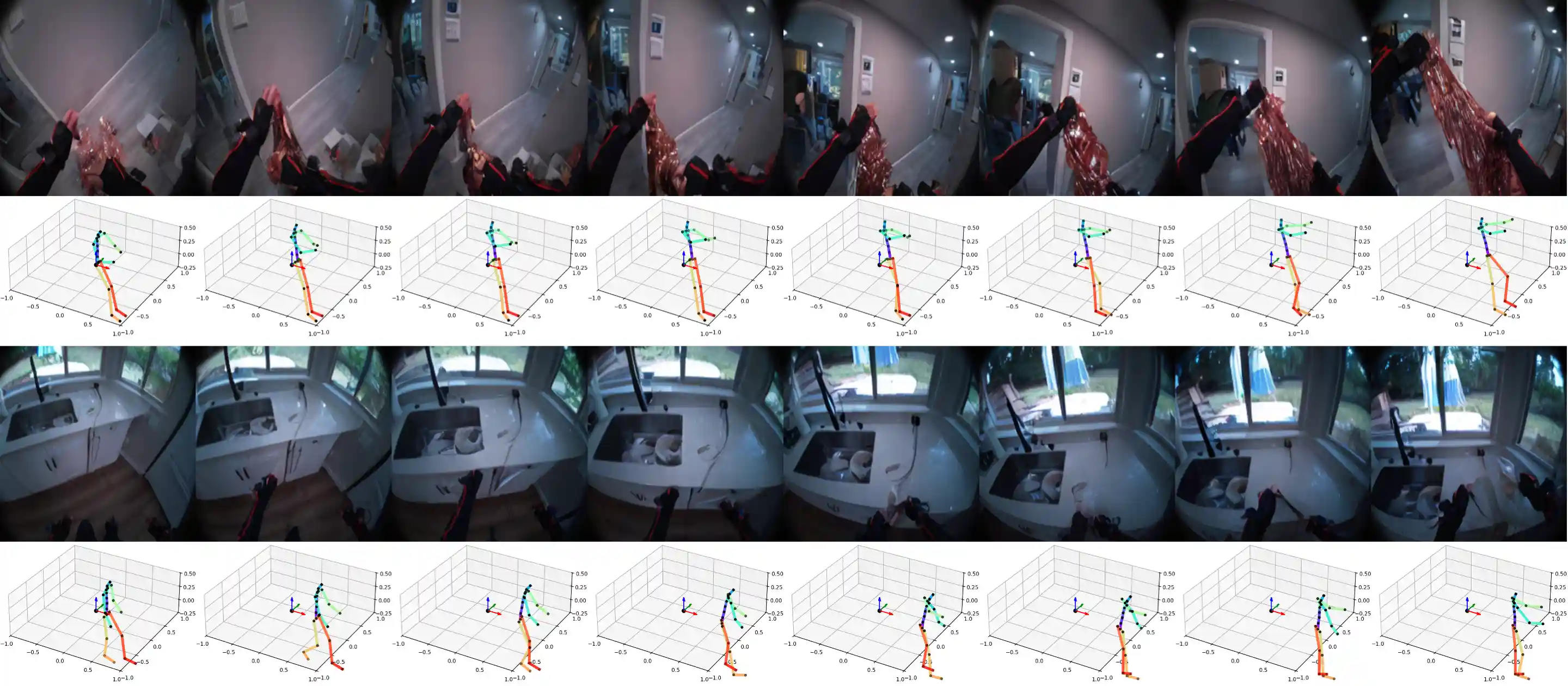
Following Atomic Actions
We demonstrate samples of PEVA following atomic actions.
Move Forward
Rotate Left

Rotate Right
Move Left Hand Up
Move Left Hand Down
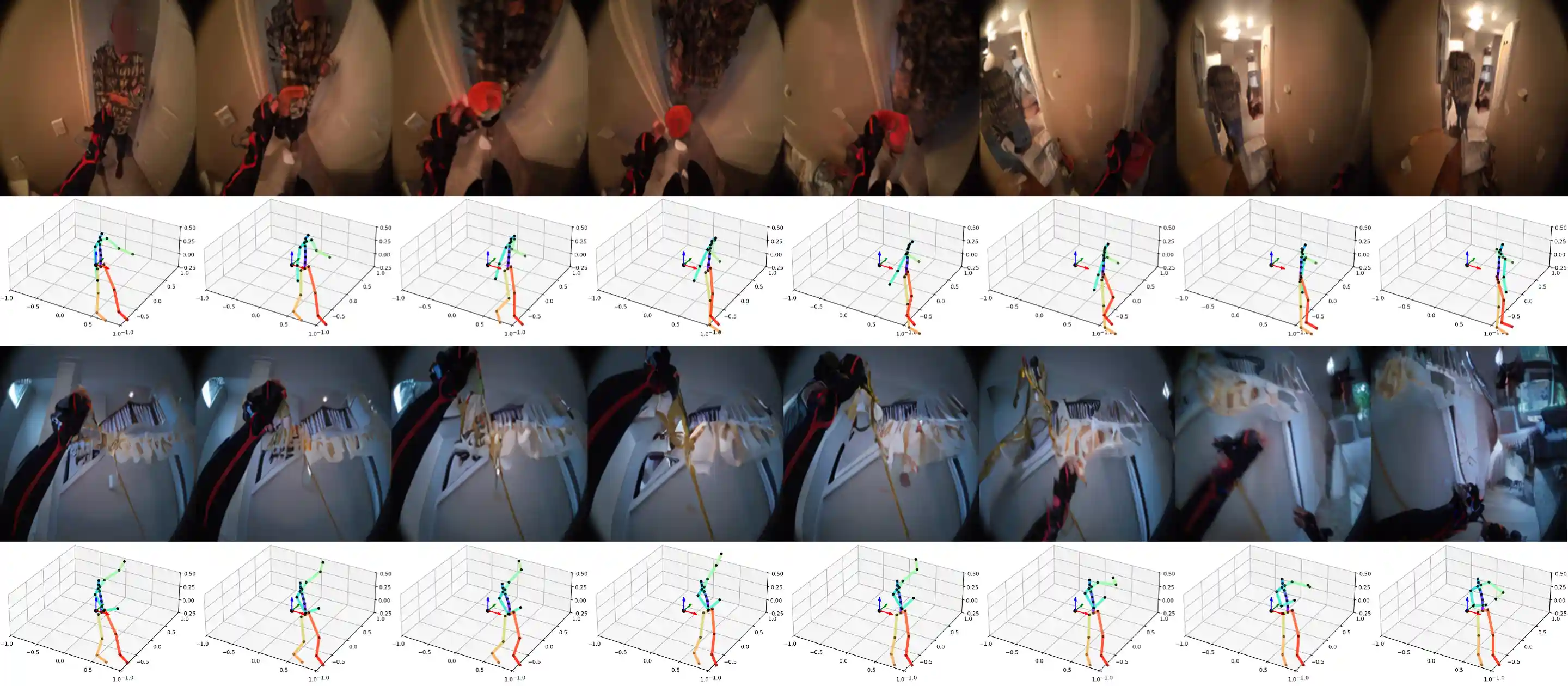
Move Left Hand Left
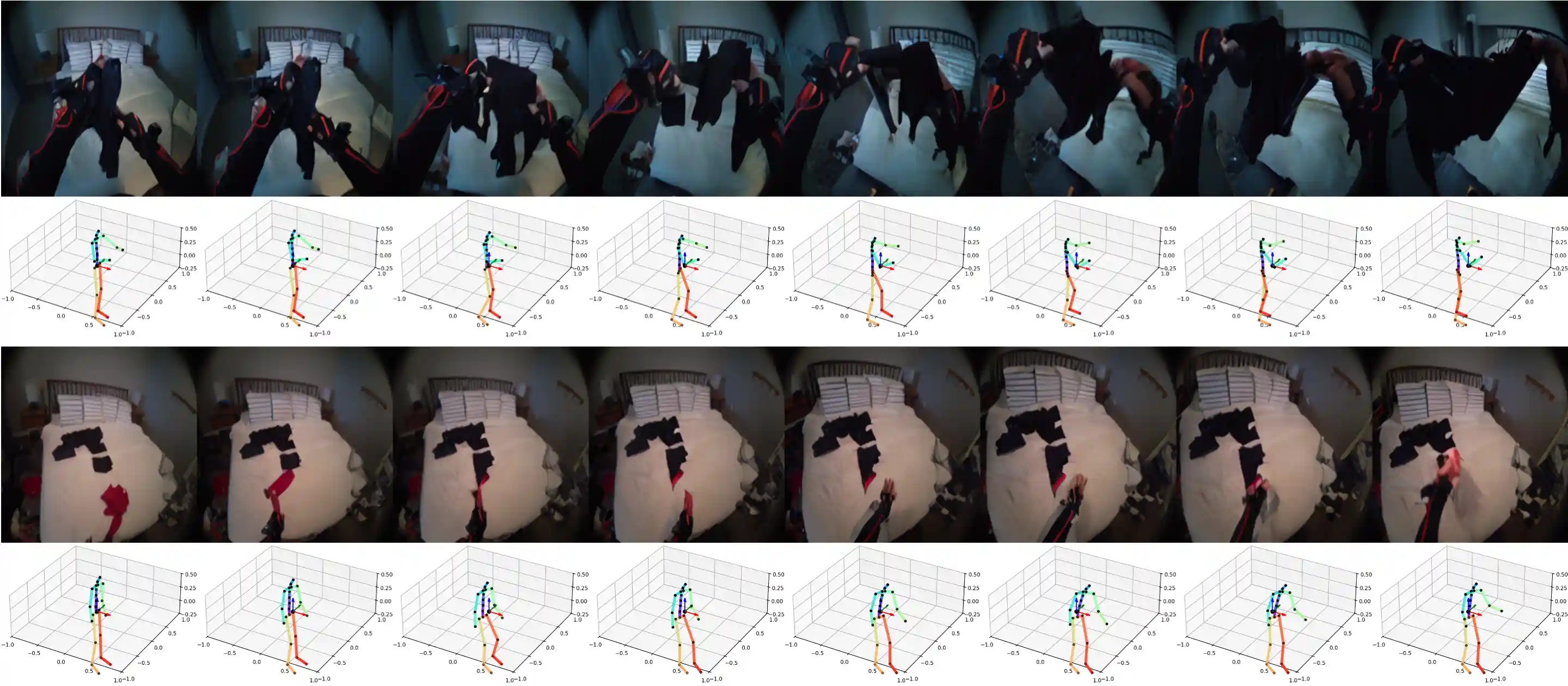
Move Left Hand Right

Move Right Hand Up

Move Right Hand Down
Move Right Hand Left
Move Right Hand Right

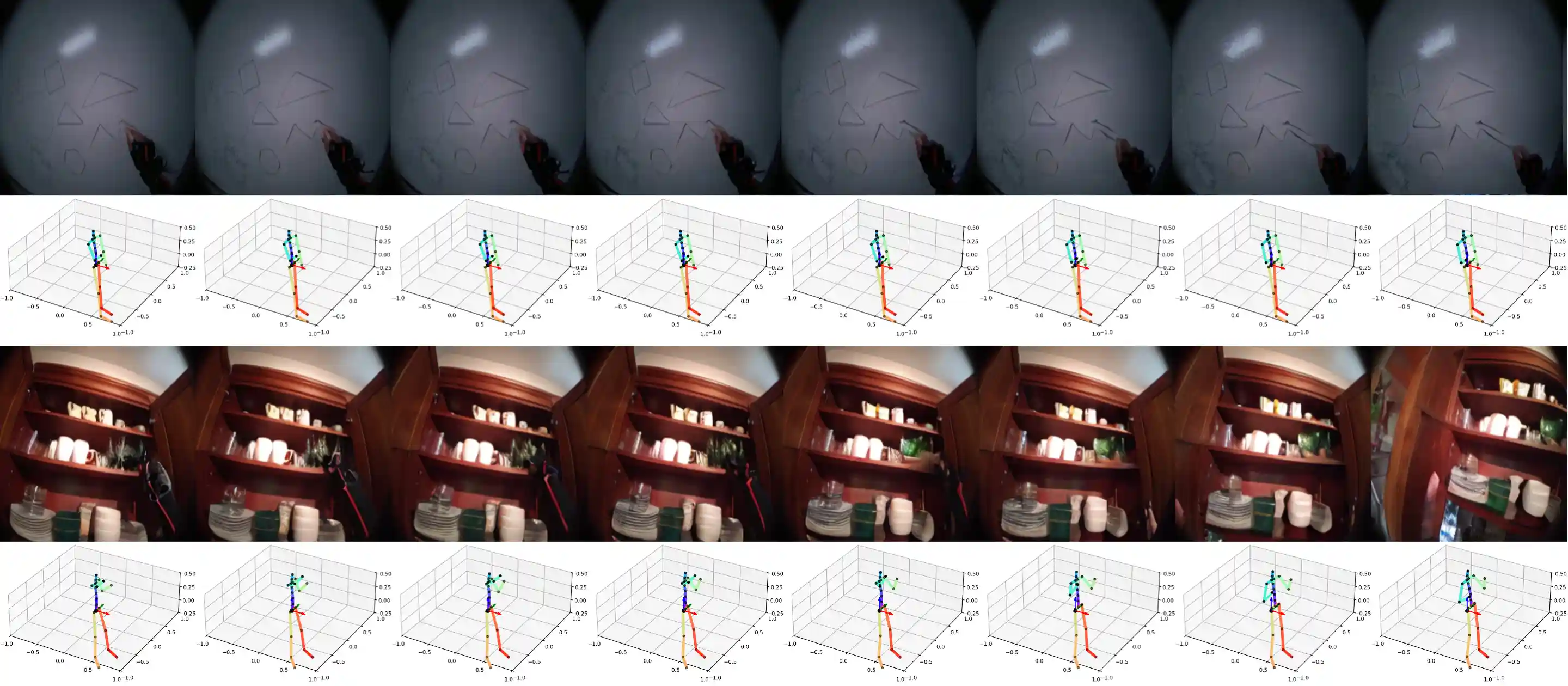
Long Video Generation
Generation Over Long-Horizons, including 16-second video generation examples. PEVA generates coherent 16-second rollouts conditioned on whole-body motion.
More Long Video Generation

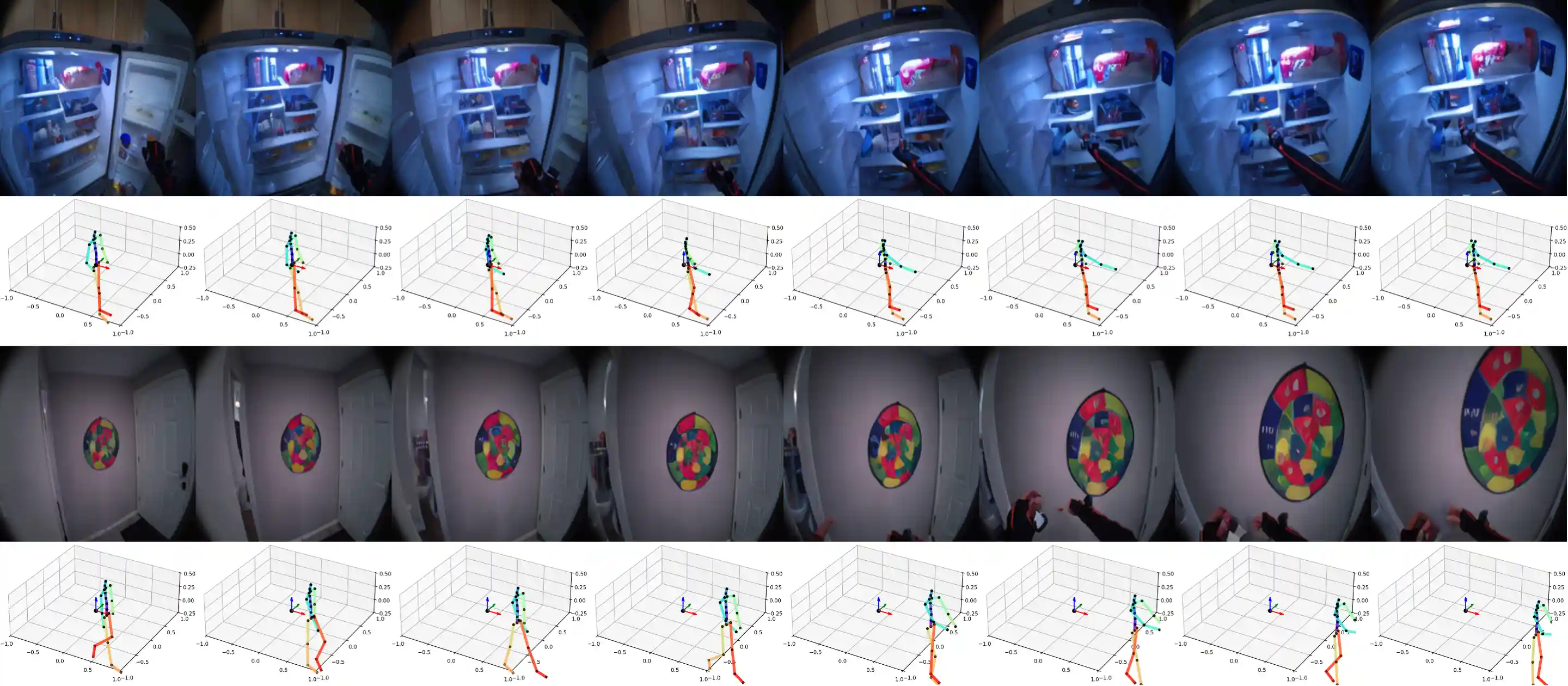
Planning with Multiple Action Candidates
We explore PEVA's ability to serve as a world model by demonstrating a planning example by simulating multiple action candidates using PEVA and scoring them based on their perceptual similarity to the goal, as measured by LPIPS. Hover over the video to play.
PEVA enables us to rule out action sequences that leads us to the sink in the top row, and outdoors in the second row. PEVA allows us to find a reasonable sequence of actions to open the refridgerator in the third row.
PEVA enables us to rule out action sequences that leads us to the plants in the top row, and to the kitchen in the second row. PEVA allows us to find a reasonable sequence of actions to grab the box in the second row.
More Attempts with Planning
We formulate planning as an energy minimization problem and perform standalone planning in the same way as NWM (Bar et al., 2025) using the Cross-Entropy Method (CEM) (Rubinstein, 1997) besides minor modifications in the representation and initialization of the action. For simplicity, we conduct two experiments where we only predict moving either the left or right arm controlled by predicting the relative joint rotations represented as euler angles.
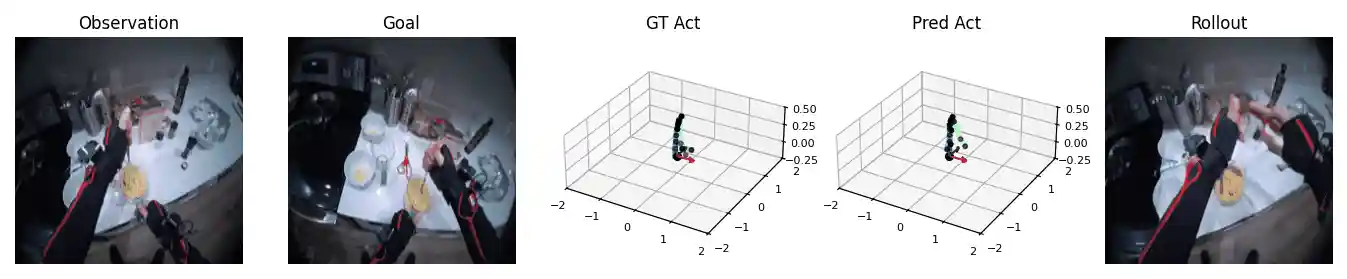
In this case, we are able to predict a sequence of actions that raises our right arm to the mixing stick. We see a limitation with our method as we only predict the right arm so we do not predict to move the left arm down accordingly.
What can it unlock?
• Action–Perception Coupling
Humans act to see, and see to act.
• Moving Beyond Synthetic Actions
Prior world models use abstract control signals—ours models real, physical human action
• Toward Embodied Intelligence
Physically grounded video models bring us closer to agents that plan, adapt, and interact like humans
• Intention Understanding Through Prediction
Predicting what an agent will see is a path to inferring what it wants
Method
Random Timeskips: It allows the model to learn both short-term motion dynamics and longer-term activity patterns.
Sequence-Level Training: Model the entire sequence of motion by applying the loss over each prefix of frames.
Action Embeddings: Whole-body motion is high-dimensional, concatenate all actions at time t into a 1D tensor and use it to condition each AdaLN layer.
Quantitative Results
Atomic Action Performance

Comparison of models in generating videos of atomic actions.
Baselines
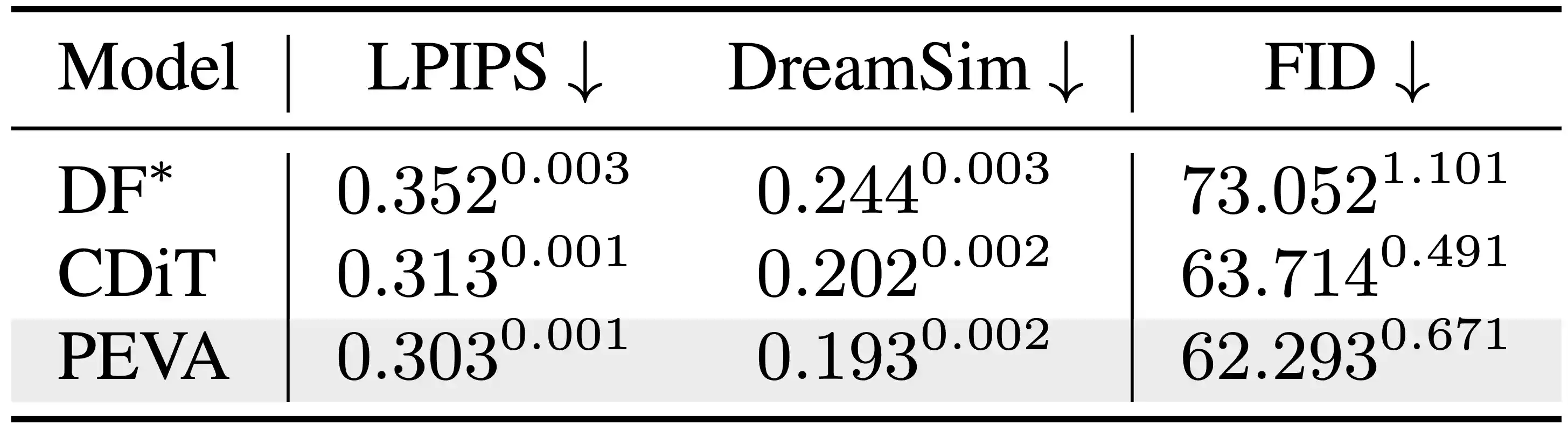
Baseline Perceptual Metrics.
Video Quality

Video Quality Across Time (FID).
Scaling

PEVA has good scaling ability. Larger models lead to better performance.
BibTeX
@misc{bai2025wholebodyconditionedegocentricvideo,
title={Whole-Body Conditioned Egocentric Video Prediction},
author={Yutong Bai and Danny Tran and Amir Bar and Yann LeCun and Trevor Darrell and Jitendra Malik},
year={2025},
eprint={2506.21552},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.21552},
}Acknowledgements