Task Arithmetic can Mitigate Synthetic-to-Real Gap in Automatic Speech Recognition
Synthetic data is widely used in speech recognition due to the availability of text-to-speech models, which facilitate adapting models to previously unseen text domains. However, existing methods suffer in performance when they fine-tune an automatic speech recognition (ASR) model on synthetic data as they suffer from the distributional shift commonly referred to as the synthetic-to-real gap.
In this paper, we find that task vector arithmetic is effective at mitigating this gap. Our proposed method, SYN2REAL task vector, shows an average improvement of 10.03% in word error rate over baselines on the SLURP dataset.
Additionally, we show that an average of SYN2REAL task vectors, when we have real speeches from multiple different domains, can further adapt the original ASR model to perform better on the target text domain.
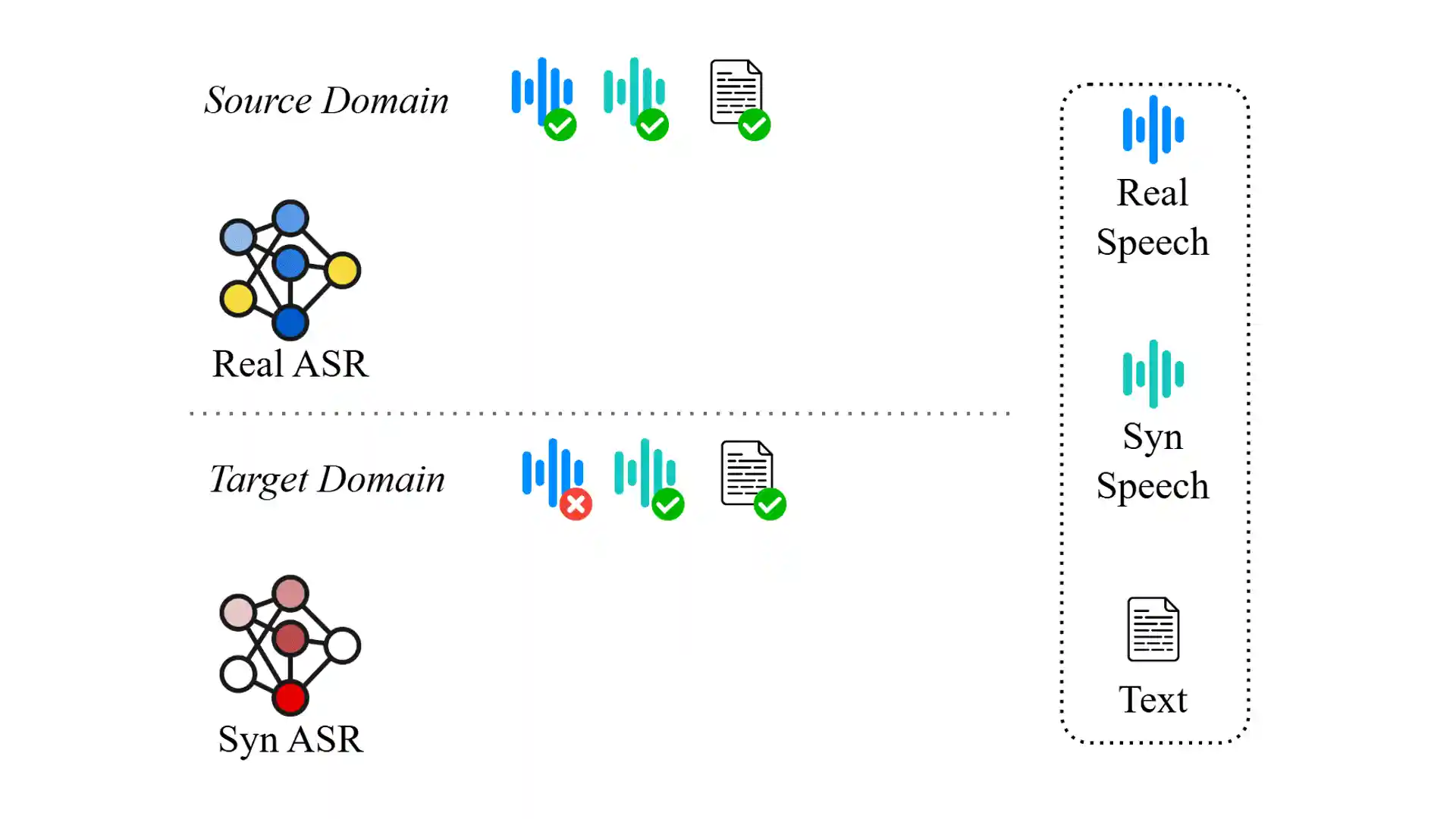
Overview of the SYN2REAL Task Vector. The pre-trained model is fine-tuned on source domain synthetic and real speech data, separately. The difference between their parameters forms the SYN2REAL task vector. The SYN2REAL task vector is then added to a model fine-tuned on target synthetic data to overcome the synthetic-to-real gap.