FastAdaSP: Multitask-Adapted Efficient Inference for Large Speech Language Model
Experimental results on WavLLM and Qwen-Audio demonstrate that FastAdaSP achieves significant improvements in both memory efficiency and computational speed. Specifically, FastAdaSP achieved a 7x increase in memory efficiency and a 1.83x increase in decoding throughput compared to baseline methods, without any degradation in task performance.
For dense tasks like Automatic Speech Recognition (ASR), FastAdaSP maintained high accuracy while reducing computational costs by up to 50%. In Speech Translation (ST), the framework effectively balanced the efficiency-performance trade-off, demonstrating only minor degradation in BLEU scores at high reduction levels. For sparse tasks such as Emotion Recognition (ER) and Spoken Question Answer (SQA), FastAdaSP even improved task accuracy by focusing the model's attention on the most informative tokens.
The experiments also highlighted the robustness of FastAdaSP's weighted merge strategy, which outperformed traditional token pruning methods by preserving essential content while reducing redundancy. The use of Transfer Entropy-based layer selection further improved the performance of sparse tasks by ensuring that token reduction occurred at optimal stages, minimizing information loss. Overall, FastAdaSP sets a new benchmark in multitask SpeechLM efficiency, combining state-of-the-art performance with practical applicability across multiple speech-related tasks.
Computational Cost experiments results show that FastAdaSP can also decrease both pre-filling and decoding latency at about 4% and 50% on A100 and H100 GPU.
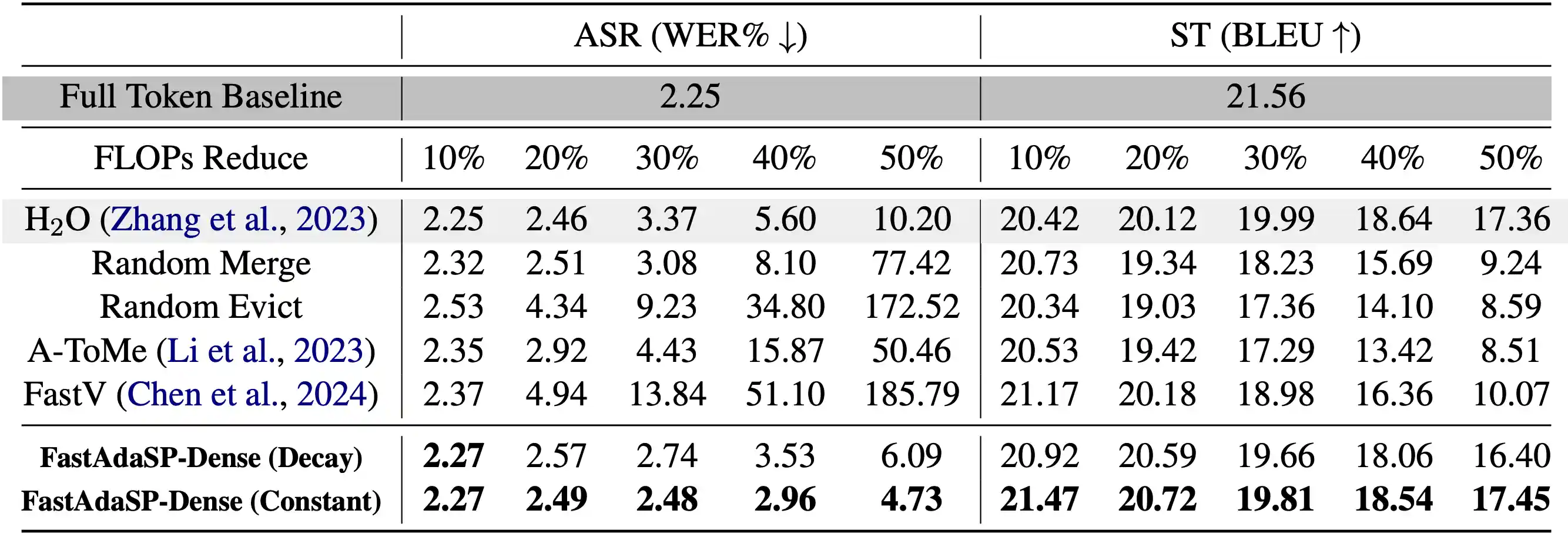
Table 1: Comparison between FastAdaSP with other token reduction methods on WavLLM dense tasks.
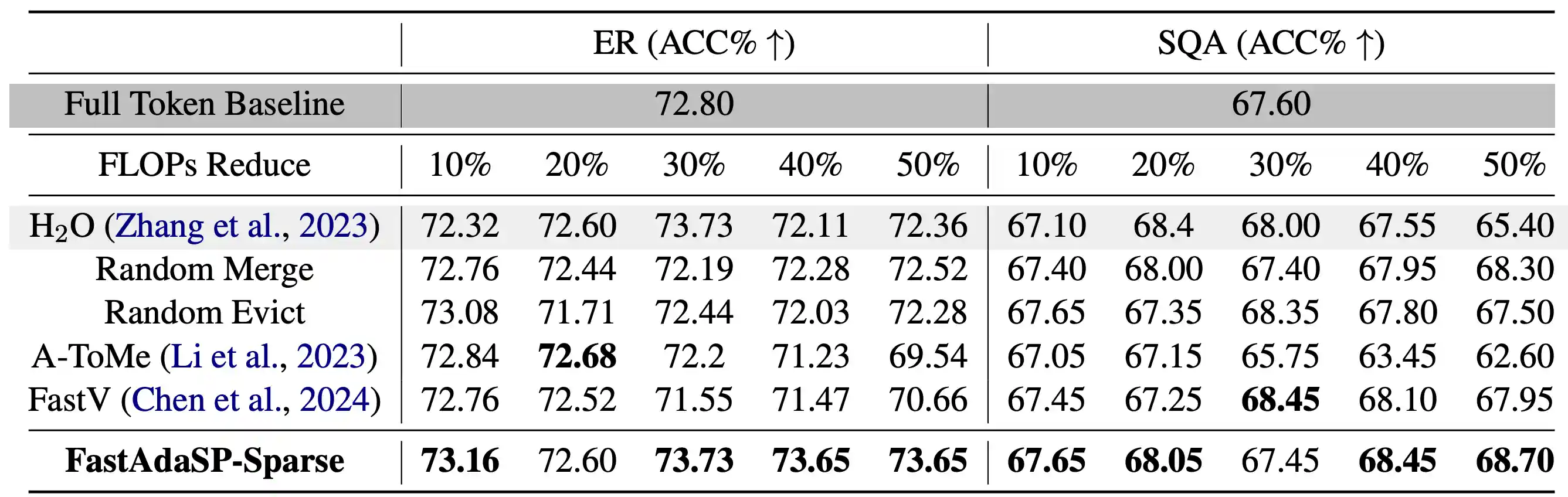
Table 2: Comparison between FastAdaSP with other token reduction methods on WavLLM sparse tasks.
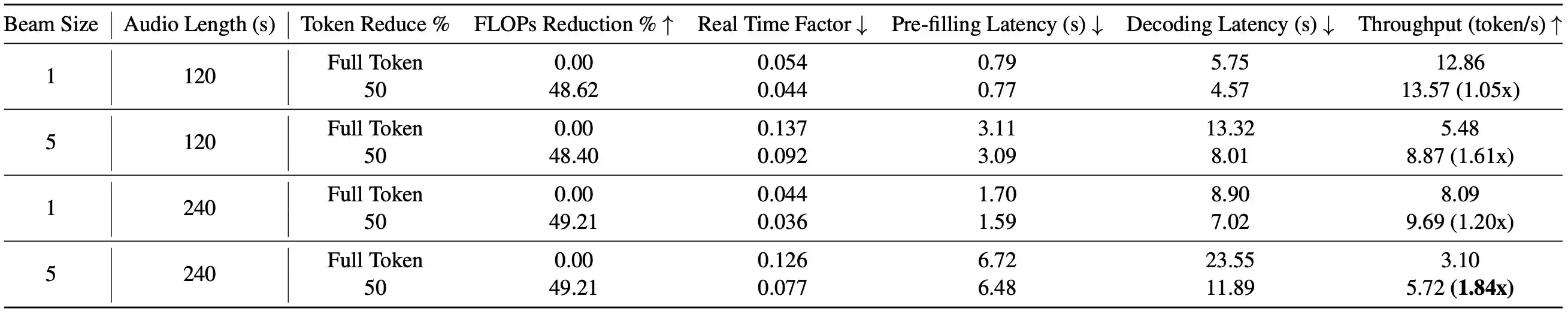
Table 3: Long Sequence Computational cost experiments on A100. Long sequence audio samples (120s and 240s) input on WavLLM using one A100 80GB GPU.
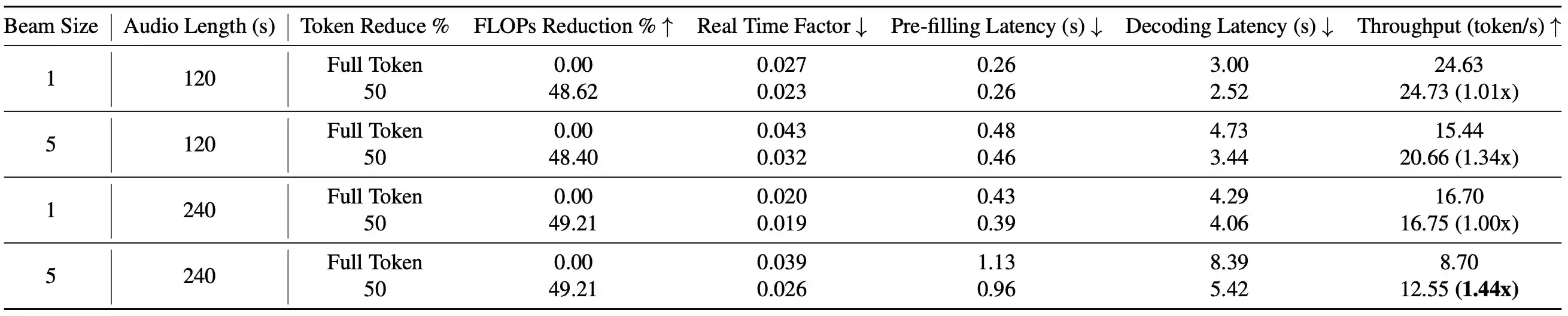
Table 4: Long Sequence Computational cost experiments on H100. Long sequence audio samples (120s and 240s) input on WavLLM using one H100 80GB GPU.