Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
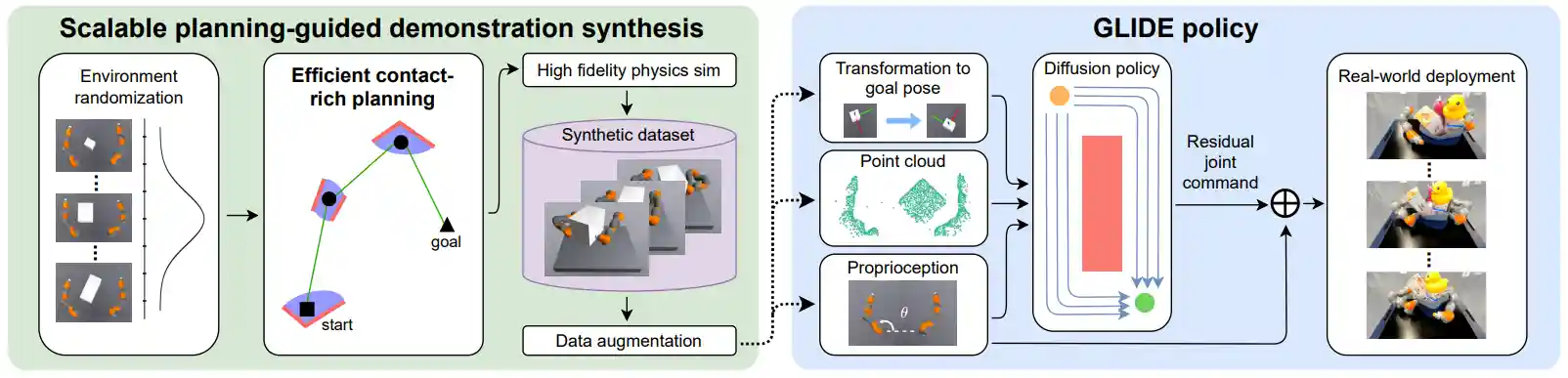
We propose Generalizable PLanning-GuIded Diffusion Policy LEarning (GLIDE). We specifically consider a tabletop environment where a bimanual robot reorients a target object to a pose in SE(2). The policy takes in visual observations (specifically uncolored point clouds), proprioceptive robot joint angles, and task conditioning vector (i.e., delta transformation between the current and the target object pose) as input.
Overall, we adopt a sim-to-real approach. We generate large-scale demonstrations in randomized simulation environments by building on the very recent advances in efficient motion planning through contact. We then filter out unsuccessful planner trajectories and the suboptimal trajectories that take too long to reach the goal, resulting in set of high-quality synthetic demonstrations.
Next, we train a goal-conditioned point cloud diffusion policy using these synthetic demonstrations via Behavior Cloning. We clip the input point cloud within robot's workspace and remove irrelevant background. We also introduce several essential design choices that significantly enhance our policy's ability to transfer to the real world and generalize to unseen scenarios: (1) We introduce a Flying Point Augmentation approach that adds large Gaussian noise to points with a small probability; (2) Our policy predicts residual robot joint actions rather than absolute joint actions; (3) During inference, we use a larger action sequence length than originally used in the diffusion policy and DP3.
To deploy our policy in the real-world, we would like to track the changes in object pose for arbitrary objects. We achieve this by using open-world detection (Grounding-Dino) and segmentation (EfficientViT-SAM) to segment out the target object in the first frame. We then select keypoints within the segmented mask and track these keypoints across subsequent frames, allowing us to calculate the delta transformation in object pose.