Haggai Maron

Assistant Professor · Technion, Faculty of Electrical and Computer Engineering
Senior Research Scientist · NVIDIA Research, Tel Aviv
My primary research interest is in machine learning, with a focus on deep learning for structured data. Specifically, I study how to apply deep learning techniques to sets, graphs, point clouds, surfaces, weight spaces and other mathematical objects that have an inherent symmetry structure. My goal is twofold: first, to understand and design deep learning architectures from a theoretical perspective, for example, by analyzing their expressive power; and second, to demonstrate their practical effectiveness on real-world problems involving structured data.
I completed my Ph.D. in 2019 at the Weizmann Institute of Science under the supervision of Prof. Yaron Lipman.
Email: haggaimaron (at) technion.ac.il · Google Scholar
Group
Current Members Fabrizio Frasca (Postdoc, 2024–today) · Yam Eitan (PhD, 2024–today) · Guy Bar-Shalom (PhD, 2023–today, joint w/ Ran El-Yaniv) · Yoav Gelberg (PhD, 2024–today, joint w/ Michael Bronstein) · Adir Dayan (PhD, 2025–today) · Alina Sudakov (MSc, 2026–today) · Yonathan Wolanowsky (MSc, 2026–today) Past Members Ran Elbaz (MSc, 2023–2025) · Yaniv Galron (MSc, 2023–2025, joint w/ Eran Treister) · Yuval Aidan (MSc, 2023–2025, joint w/ Ayellet Tal) · Edan Kinderman (MSc, 2023–2025, joint w/ Daniel Soudry) · Ofir Haim (MSc, 2023–2025, joint w/ Shie Mannor) Close Collaborators Theo (Moe) Putterman (UC Berkeley, 2023–2025) · Beatrice Bevilacqua (Purdue, 2021–2025) · Derek Lim (MIT CSAIL, 2021–2025) · Moshe Eliasof (Cambridge/BGU, 2022–today) · Aviv Navon (BIU/Aiola, 2021–today) · Aviv Shamsian (BIU/Aiola, 2022–today)
News
- Keynotes at LoG 2025 and TAG-DS 2025 on Geometric Deep Learning for Neural Artifacts.
- Short tutorial on the expressive power of GNNs at the Simons Institute workshop.
- Recipient of the Alon scholarship for the Integration of Outstanding Faculty.
- Talk on Equivariant architectures for learning in deep weight spaces.
- Blog post on Equivariant architectures for learning in deep weight spaces.
- Tutorial on expressive graph neural networks at LoG Conference (with Fabrizio Frasca and Beatrice Bevilacqua).
- Blog post on Subgraph GNNs on Towards Data Science.
- ICML 2020 paper On Learning Sets of Symmetric Elements received the Outstanding Paper Award. See this interview.
Talks & Media
- Geometric Deep Learning for Neural Artifacts – Symmetry-Aware Learning across Trained Model Weights, Internal Representations, and Gradients
- The expressive power of GNNs – short tutorial at the Simons Institute
- Equivariant architectures for learning in deep weight spaces
- Subgraph-based networks for expressive, efficient, and domain-independent graph learning (CIRM)
- Leveraging Permutation Group Symmetries for Equivariant Neural Networks
- Podcast: Graph neural networks (Hebrew)
Teaching
- 2025/Spring (Technion): Introduction to Machine Learning
- 2025/Spring (Technion): Deep Learning and Groups
- 2024/Winter (Technion): Topics in Learning on Graphs
- 2024/Spring (Technion): Deep Learning and Groups
- 2023/Winter (Technion): Topics in Learning on Graphs
- 2019/Spring (WIS): Geometric and Algebraic Methods in Deep Learning
- 2018/Winter (WIS): Geometry and Deep Learning
Publications

Neural Message-Passing on Attention Graphs for Hallucination Detection
The Fourteenth International Conference on Learning Representations (ICLR 2026)
Summary
Large Language Models (LLMs) often generate incorrect or unsupported content, known as hallucinations. Existing detection methods rely on heuristics or simple models over isolated computational traces such as activations, or attention maps. We unify these signals by representing them as attributed graphs, where tokens are nodes, edges follow attentional flows, and both carry features from attention scores and activations. Our approach, CHARM, casts hallucination detection as a graph learning task and tackles it by applying GNNs over the above attributed graphs. We show that CHARM provably subsumes prior attention-based heuristics and, experimentally, it consistently outperforms other leading approaches across diverse benchmarks.
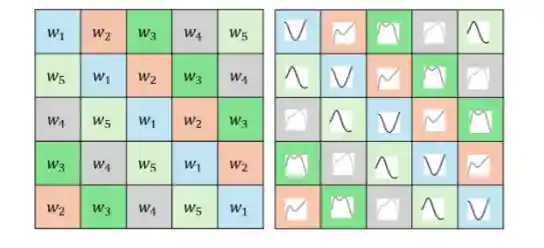
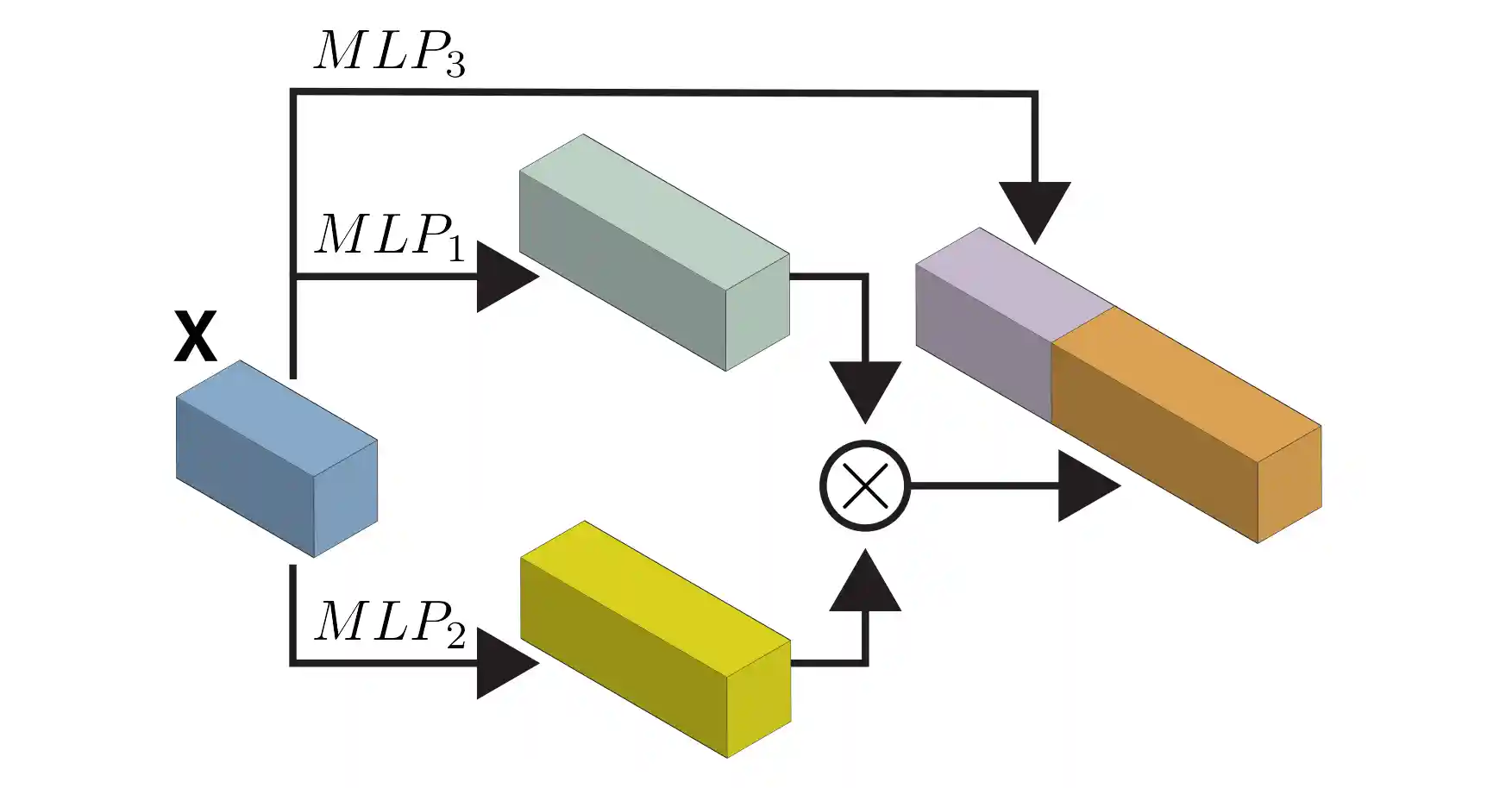
FS-KAN: Permutation Equivariant Kolmogorov-Arnold Networks via Function Sharing
Ran Elbaz, Guy Bar-Shalom, Yam Eitan, Fabrizio Frasca, Haggai Maron
The Fourteenth International Conference on Learning Representations (ICLR 2026)
Summary
This paper introduces Function Sharing KAN (FS-KAN), a principled approach to constructing equivariant and invariant KA layers for arbitrary permutation symmetry groups, unifying and significantly extending previous work in this domain. We derive the basic construction of these FS-KAN layers by generalizing parameter-sharing schemes to the Kolmogorov-Arnold setup and provide a theoretical analysis demonstrating that FS-KANs have the same expressive power as networks that use standard parameter-sharing layers. Empirical evaluations show that FS-KANs exhibit superior data efficiency compared to standard parameter-sharing layers, making them an excellent architecture choice in low-data regimes.
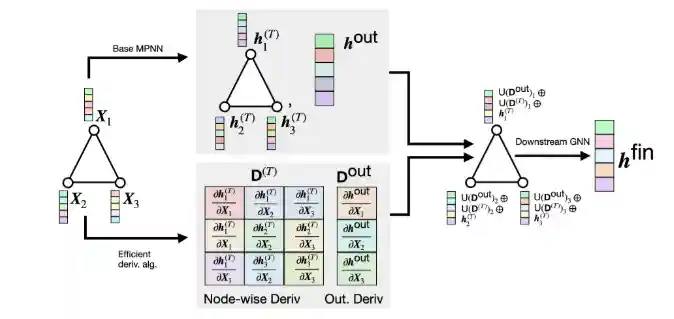
On The Expressive Power of GNN Derivatives
Yam Eitan, Moshe Eliasof, Yoav Gelberg, Fabrizio Frasca, Guy Bar-Shalom, Haggai Maron
The Fourteenth International Conference on Learning Representations (ICLR 2026)
Summary
We introduce High-Order Derivative GNN (HOD-GNN), a novel method that enhances the expressivity of Message Passing Neural Networks (MPNNs) by leveraging high-order node derivatives of the base model. These derivatives generate expressive structure-aware node embeddings processed by a second GNN in an end-to-end trainable architecture. Theoretically, we show that the resulting architecture family's expressive power aligns with the WL hierarchy. We also draw deep connections between HOD-GNN, Subgraph GNNs, and popular structural encoding schemes.
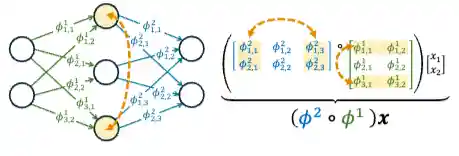
A Graph Meta-Network for Learning on Kolmogorov–Arnold Networks
Guy Bar-Shalom, Ami Tavory, Itay Evron, Maya Bechler-Speicher, Ido Guy, Haggai Maron
The Fourteenth International Conference on Learning Representations (ICLR 2026)
Summary
We show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power and construct a comprehensive 'zoo' of trained KANs as benchmarks. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin.

Learning from Historical Activations in Graph Neural Networks
Yaniv Galron, Hadar Sinai, Haggai Maron, Moshe Eliasof
The Fourteenth International Conference on Learning Representations (ICLR 2026)
Summary
We introduce HistoGraph, a novel two-stage attention-based final aggregation layer that first applies a unified layer-wise attention over intermediate activations, followed by node-wise attention. By modeling the evolution of node representations across layers, our HistoGraph leverages both the activation history of nodes and the graph structure to refine features used for final prediction. Empirical results demonstrate that HistoGraph offers strong performance that consistently improves traditional techniques, with particularly strong robustness in deep GNNs.

Beyond Next Token Probabilities: Learnable, Fast Detection of Hallucinations and Data Contamination on LLM Output Distributions
Guy Bar-Shalom*, Fabrizio Frasca*, Derek Lim, Yoav Gelberg, Yftah Ziser, Ran El-Yaniv, Gal Chechik, Haggai Maron
The 40th Annual AAAI Conference on Artificial Intelligence (AAAI 2026)
Spotlight at ICLR 2025 workshop 'Quantify Uncertainty and Hallucination in Foundation Models'
Summary
We propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both token probabilities and the complete token distribution sequences – a unified data type we term LOS (LLM Output Signature). We develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines.
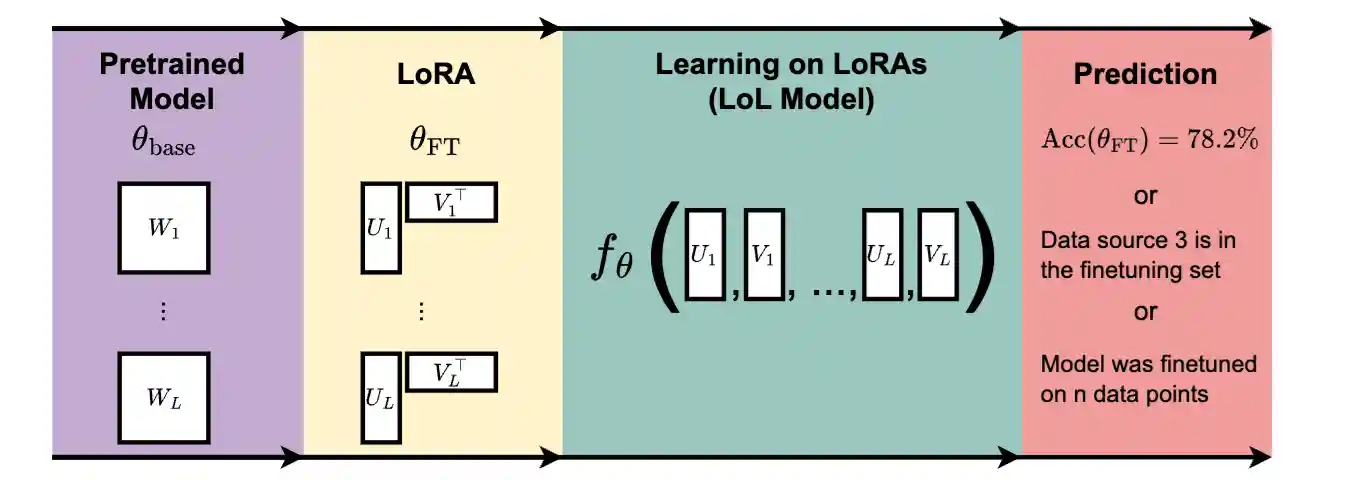
GL Equivariant Metanetworks for Learning on Low Rank Weight Spaces
Theo Putterman, Derek Lim, Yoav Gelberg, Michael M. Bronstein, Stefanie Jegelka, Haggai Maron
The Fourth Learning on Graphs Conference (LOG 2025)
Oral Presentation
Summary
We investigate the potential of Learning on LoRAs (LoL), a setup where machine learning models learn and make predictions on datasets of LoRA weights. We first identify the inherent parameter symmetries of low-rank decompositions of weights and develop several symmetry-aware invariant or equivariant LoL models. In diverse experiments, we show that our LoL architectures can process LoRA weights to predict CLIP scores, finetuning data attributes, and accuracy on downstream tasks over 50,000 times faster than standard evaluation.
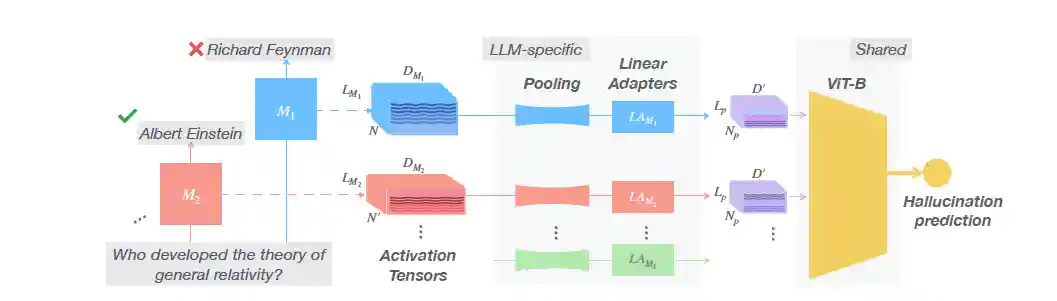
Beyond Token Probes: Hallucination Detection via Activation Tensors with ACT-ViT
Guy Bar-Shalom, Fabrizio Frasca, Yaniv Galron, Yftah Ziser, Haggai Maron
39th Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
Summary
We introduce ACT-ViT, a Vision Transformer-inspired model that can be effectively and efficiently applied to activation tensors and supports training on data from multiple LLMs simultaneously. Through comprehensive experiments encompassing diverse LLMs and datasets, we demonstrate that ACT-ViT consistently outperforms traditional probing techniques while remaining extremely efficient for deployment. Our architecture benefits substantially from multi-LLM training, achieves strong zero-shot performance on unseen datasets, and can be transferred effectively to new LLMs through fine-tuning.
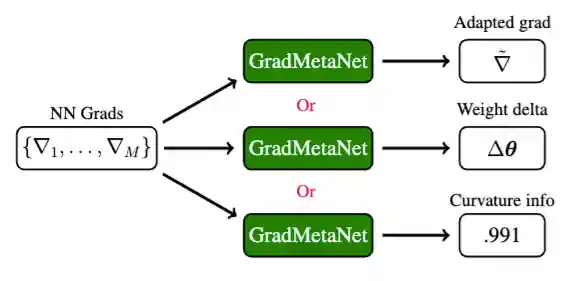
GradMetaNet: An Equivariant Architecture for Learning on Gradients
Yoav Gelberg, Yam Eitan, Aviv Navon, Aviv Shamsian, Theo Putterman, Michael M. Bronstein, Haggai Maron
39th Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
Summary
We present a principled approach for designing architectures that process gradients guided by three principles: (1) equivariant design that preserves neuron permutation symmetries, (2) processing sets of gradients across multiple data points to capture curvature information, and (3) efficient gradient representation through rank-1 decomposition. We introduce GradMetaNet, a novel architecture for learning on gradients, and prove universality results. We demonstrate GradMetaNet's effectiveness on diverse gradient-based tasks for MLPs and transformers, such as learned optimization, INR editing, and loss landscape curvature estimation.

Understanding and Improving Laplacian Positional Encodings For Temporal GNNs
Yaniv Galron, Fabrizio Frasca, Haggai Maron, Eran Treister, Moshe Eliasof
ECML-PKDD 2025
Summary
We address key challenges in supra-Laplacian positional encodings for temporal graphs: high eigendecomposition costs, limited theoretical understanding, and ambiguity about when to apply these encodings. We offer a theoretical framework connecting supra-Laplacian encodings to per-time-slice encodings, introduce novel methods to reduce computational overhead (achieving up to 56x faster runtimes), and conduct an extensive experimental study to identify which models, tasks, and datasets benefit most from these encodings.

Balancing Efficiency and Expressiveness: Subgraph GNNs with Walk-Based Centrality
Joshua Southern*, Yam Eitan, Guy Bar-Shalom, Michael Bronstein, Haggai Maron, Fabrizio Frasca*
International Conference on Machine Learning (ICML) 2025
Summary
We propose HyMN, an expressive and efficient approach that combines Subgraph GNNs and Structural Encodings (SEs) via walk-based centrality measures. By drawing a connection to perturbation analysis, we highlight the effectiveness of centrality-based sampling, which significantly reduces the computational burden of Subgraph GNNs. HyMN effectively addresses the expressiveness limitations of MPNNs while mitigating the computational costs of Subgraph GNNs, outperforming other subgraph sampling approaches while being competitive with full-bag Subgraph GNNs.

Topological Blind Spots: Understanding and Extending Topological Deep Learning Through the Lens of Expressivity
Yam Eitan, Yoav Gelberg, Guy Bar-Shalom, Fabrizio Frasca, Michael Bronstein, Haggai Maron
International Conference on Learning Representations (ICLR) 2025
Oral Presentation
Summary
We aim to explore both the strengths and weaknesses of higher-order message-passing (HOMP)'s expressive power and subsequently design novel architectures to address its limitations. We demonstrate HOMP's inability to distinguish between topological objects based on fundamental topological and metric properties such as diameter, orientability, planarity, and homology. We then develop two new classes of TDL models: multi-cellular networks (MCN) and scalable multi-cellular networks (SMCN), which mitigate many of HOMP's expressivity limitations.
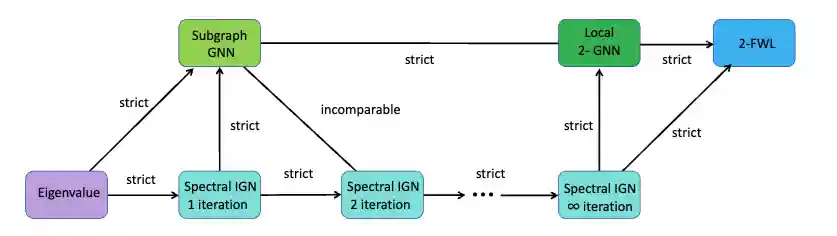
Homomorphism Expressivity of Spectral Invariant Graph Neural Networks
Jingchu Gai, Yiheng Du, Bohang Zhang, Haggai Maron, Liwei Wang
International Conference on Learning Representations (ICLR) 2025
Oral Presentation
Summary
We address the fundamental question of the power of spectral invariants in GNNs through the lens of homomorphism expressivity, providing a comprehensive and quantitative analysis. We prove that spectral invariant GNNs can homomorphism-count exactly a class of specific tree-like graphs referred to as parallel trees, and highlight the significance of this result in establishing quantitative expressiveness hierarchies across different architectural variants.

Lightning-Fast Image Inversion and Editing for Text-to-Image Diffusion Models
Dvir Samuel, Barak Meiri, Haggai Maron, Yoad Tewel, Nir Darshan, Shai Avidan, Gal Chechik, Rami Ben-Ari
International Conference on Learning Representations (ICLR) 2025
Summary
We formulate diffusion inversion as finding the roots of an implicit equation and design a method based on Newton-Raphson (NR). We derive an efficient guided formulation that fastly converges and provides high-quality reconstructions and editing. Our solution, Guided Newton-Raphson Inversion, inverts an image within 0.4 sec (on an A100 GPU) for few-step models (SDXL-Turbo and Flux.1), opening the door for interactive image editing.
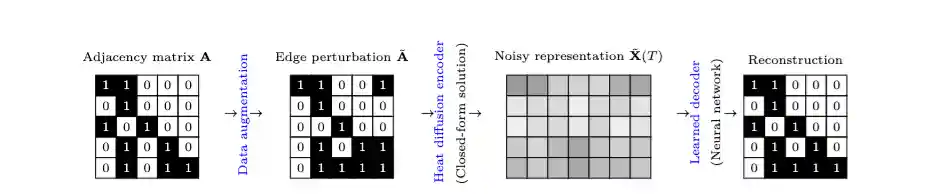
Directed Graph Generation with Heat Kernels
Marc T Law, Karsten Kreis, Haggai Maron
TMLR 2025
Summary
We propose a denoising autoencoder-based generative model that exploits the global structure of directed graphs via their Laplacian dynamics and enables one-shot generation. Our approach generalizes a special class of exponential kernels over discrete structures, called diffusion kernels or heat kernels, to the non-symmetric case via Reproducing Kernel Banach Spaces. We demonstrate that our model is able to generate directed graphs that follow the distribution of the training dataset even if it is multimodal.

Foldable Supernets: Scalable Merging of Transformers with Different Initializations and Tasks
Edan Kinderman, Itay Hubara, Haggai Maron, Daniel Soudry
TMLR 2025
Summary
We propose Foldable SuperNet Merge (FS-Merge), a method that optimizes a SuperNet to fuse original models using a feature reconstruction loss. FS-Merge is simple, data-efficient, and capable of merging models of varying widths. We test FS-Merge against existing methods on MLPs and transformers across various settings, sizes, tasks, and modalities. FS-Merge consistently outperforms them, achieving SOTA results, particularly in limited data scenarios.
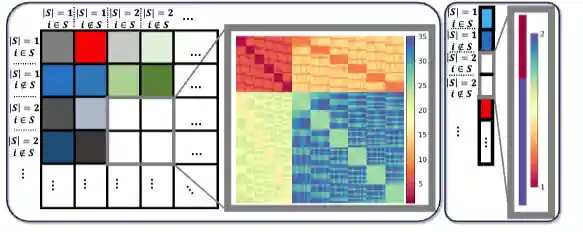
A Flexible, Equivariant Framework for Subgraph GNNs via Graph Products and Graph Coarsening
Guy Bar-Shalom, Yam Eitan, Fabrizio Frasca, Haggai Maron
38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024)
Best Paper Award at Symmetry and Geometry in Neural Representations Workshop @ NeurIPS 2024
Summary
We introduce a new Subgraph GNNs framework employing a graph coarsening function to cluster nodes into super-nodes. The product between the coarsened and original graph reveals an implicit structure whereby subgraphs are associated with specific sets of nodes. By running generalized message-passing on such graph product, our method effectively implements an efficient yet powerful Subgraph GNN. We discover that the resulting node feature tensor exhibits new, unexplored permutation symmetries and leverage this structure to characterize the associated linear equivariant layers.

Fast Encoder-Based 3D from Casual Videos via Point Track Processing
Yoni Kasten, Wuyue Lu, Haggai Maron
38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024)
Summary
We present TracksTo4D, a learning-based approach that enables inferring 3D structure and camera positions from dynamic content originating from casual videos using a single efficient feed-forward pass. We propose operating directly over 2D point tracks as input and designing an architecture tailored for processing 2D point tracks. TracksTo4D is trained in an unsupervised way and can reconstruct a temporal point cloud and camera positions with accuracy comparable to state-of-the-art methods, while drastically reducing runtime by up to 95%.

GRANOLA: Adaptive Normalization for Graph Neural Networks
Moshe Eliasof, Beatrice Bevilacqua, Carola-Bibiane Schönlieb, Haggai Maron
38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024)
Summary
We propose GRANOLA, a novel graph-adaptive normalization layer. Unlike existing normalization layers, GRANOLA normalizes node features by adapting to the specific characteristics of the graph, particularly by generating expressive representations of its neighborhood structure via Random Node Features (RNF). Our extensive empirical evaluation underscores the superior performance of GRANOLA over existing normalization techniques, emerging as the top-performing method within the same time complexity of MPNNs.
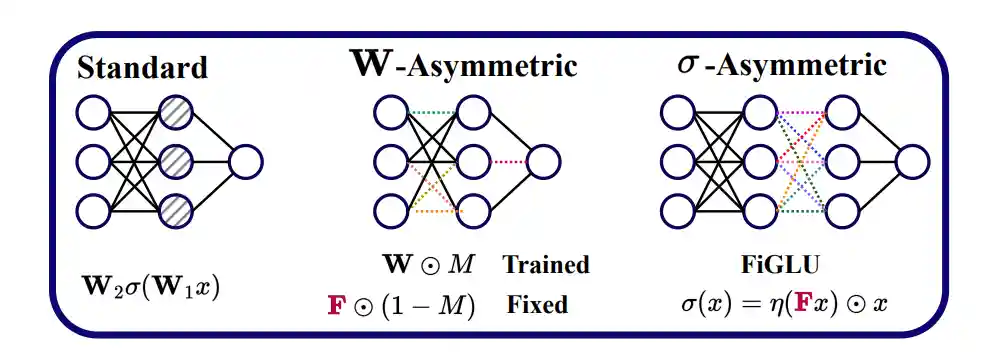
The Empirical Impact of Neural Parameter Symmetries, or Lack Thereof
Derek Lim*, Theo (Moe) Putterman*, Robin Walters, Haggai Maron, Stefanie Jegelka
38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024)
Best Paper Award at HiLD 2024: 2nd Workshop on High-dimensional Learning Dynamics @ ICML 2024
Summary
We empirically investigate the impact of neural parameter symmetries by introducing new neural network architectures that have reduced parameter space symmetries. We develop two methods of modifying standard neural networks to reduce parameter space symmetries and conduct a comprehensive experimental study assessing the effect of removing these symmetries. Our experiments reveal several interesting observations; for instance, we observe linear mode connectivity and monotonic linear interpolation in our networks, without any alignment of weight spaces.

Towards Foundation Models on Graphs: An Analysis on Cross-Dataset Transfer of Pretrained GNNs
Fabrizio Frasca, Fabian Jogl, Moshe Eliasof, Matan Ostrovsky, Carola-Bibiane Schönlieb, Thomas Gärtner, Haggai Maron
Symmetry and Geometry in Neural Representations (NeurReps) @ NeurIPS 2024
Summary
We study the extent to which pretrained Graph Neural Networks can be applied across datasets, requiring feature-agnostic approaches. We build upon a purely structural pretraining approach and propose an extension to capture feature information while still being feature-agnostic. Our preliminary results indicate that embeddings from pretrained models improve generalization only with enough downstream data points and in a degree which depends on the quantity and properties of pretraining data.

Future Directions in Foundations of Graph Machine Learning
Christopher Morris, Nadav Dym, Haggai Maron, İsmail İlkan Ceylan, Fabrizio Frasca, Ron Levie, Derek Lim, Michael Bronstein, Martin Grohe, Stefanie Jegelka
International Conference on Machine Learning (ICML) 2024
Summary
We argue that the graph machine learning community needs to shift its attention to developing a more balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.
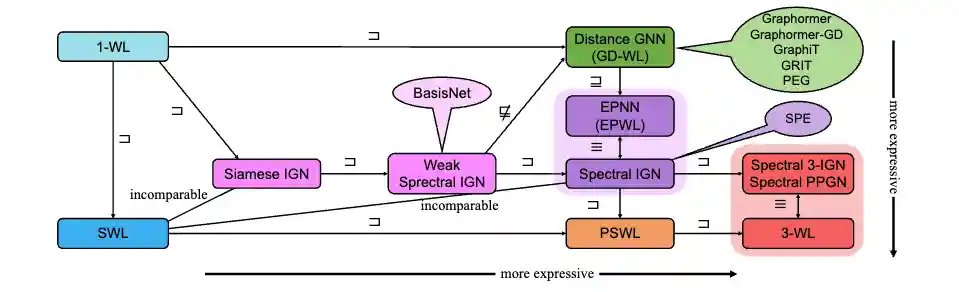
On the Expressive Power of Spectral Invariant Graph Neural Networks
Bohang Zhang, Lingxiao Zhao, Haggai Maron
International Conference on Machine Learning (ICML) 2024
Summary
We introduce a novel message-passing framework for designing spectral invariant GNNs, called Eigenspace Projection GNN (EPNN). Our comprehensive analysis shows that EPNN essentially unifies all prior spectral invariant architectures, and they are either strictly less expressive or equivalent to EPNN. We present a surprising result that EPNN itself is bounded by a recently proposed class of Subgraph GNNs, implying that all spectral invariant architectures are strictly less expressive than 3-WL.

Equivariant Deep Weight Space Alignment
Aviv Navon, Aviv Shamsian, Ethan Fetaya, Gal Chechik, Nadav Dym, Haggai Maron
International Conference on Machine Learning (ICML) 2024
Summary
We propose Deep-Align, a novel framework aimed at learning to solve the weight alignment problem. We demonstrate that weight alignment adheres to two fundamental symmetries and propose a deep architecture that respects these symmetries. Our framework does not require any labeled data. Our experimental results indicate that a feed-forward pass with Deep-Align produces better or equivalent alignments compared to those produced by current optimization algorithms.

Subgraphormer: Unifying Subgraph GNNs and Graph Transformers via Graph Products
Guy Bar-Shalom, Beatrice Bevilacqua, Haggai Maron
International Conference on Machine Learning (ICML) 2024
Summary
We propose Subgraphormer, an architecture that integrates Subgraph GNNs and Graph Transformers, combining enhanced expressive power and message-passing mechanisms from Subgraph GNNs with attention and positional encodings from Graph Transformers. Our method is based on a new connection between Subgraph GNNs and product graphs, suggesting that Subgraph GNNs can be formulated as MPNNs operating on a product of the graph with itself.
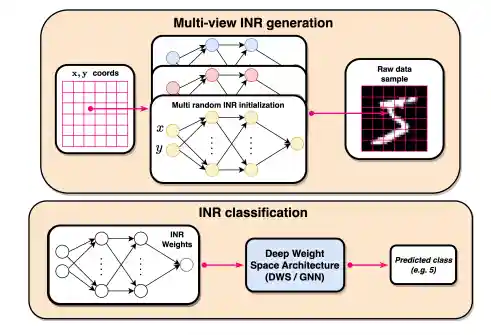
Improved Generalization of Weight Space Networks via Augmentations
Aviv Shamsian, Aviv Navon, David W. Zhang, Yan Zhang, Ethan Fetaya, Gal Chechik, Haggai Maron
International Conference on Machine Learning (ICML) 2024
Oral Presentation at NeurReps Workshop @ NeurIPS 2023
Summary
We empirically analyze the reasons for overfitting in deep weight space models and find that a key reason is the lack of diversity in DWS datasets. We explore strategies for data augmentation in weight spaces and propose a MixUp method adapted for weight spaces. These methods improve classification performance similarly to having up to 10 times more data, and yield substantial 5–10% gains in downstream classification under contrastive learning.
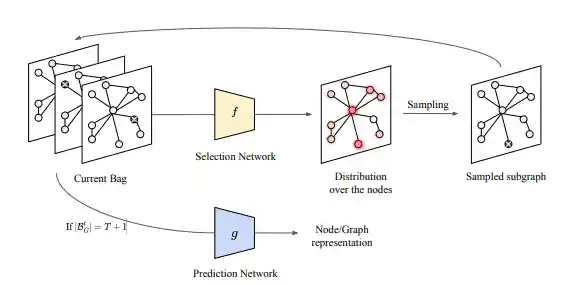
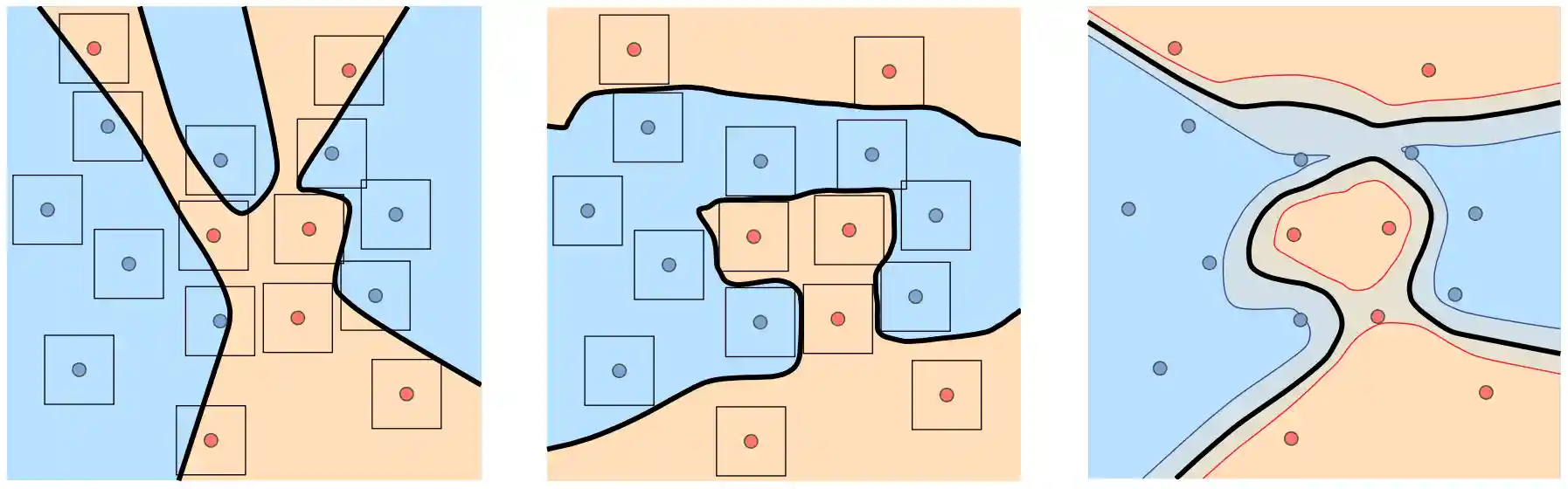
Efficient Subgraph GNNs by Learning Effective Selection Policies
Beatrice Bevilacqua, Moshe Eliasof, Eli Meirom, Bruno Ribeiro, Haggai Maron
International Conference on Learning Representations (ICLR) 2024
Summary
We consider the problem of learning to select a small subset of the large set of possible subgraphs in a data-driven fashion. We prove that there are families of WL-indistinguishable graphs for which there exist efficient subgraph selection policies. We then propose Policy-Learn, that learns how to select subgraphs in an iterative manner. We prove that, unlike popular random policies and prior work, our architecture is able to learn these efficient policies.
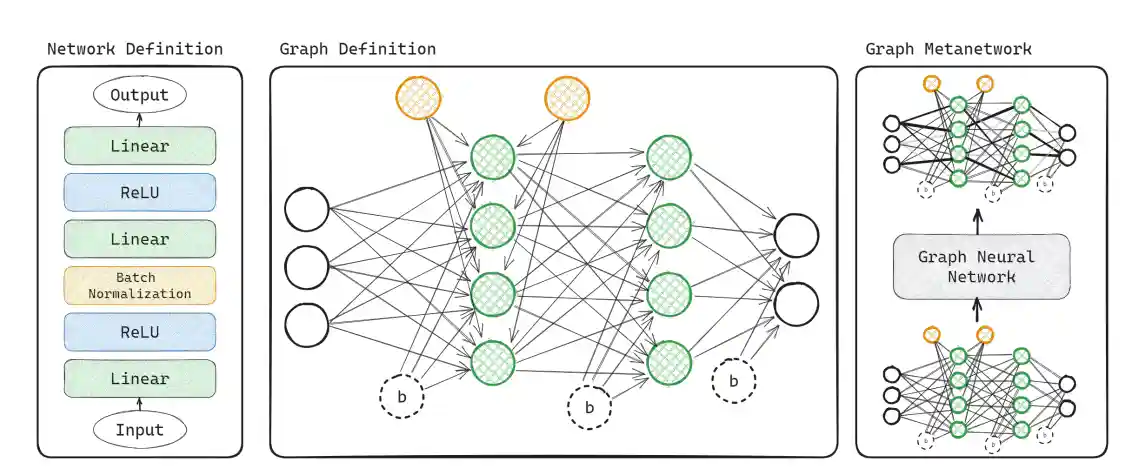
Graph Metanetworks for Processing Diverse Neural Architectures
Derek Lim, Haggai Maron, Marc T. Law, Jonathan Lorraine, James Lucas
International Conference on Learning Representations (ICLR) 2024
Spotlight Presentation
Summary
We build new metanetworks – neural networks that take weights from other neural networks as input – by carefully building graphs representing the input neural networks and processing them using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries.

Expressive Sign Equivariant Networks for Spectral Geometric Learning
Derek Lim, Joshua Robinson, Stefanie Jegelka, Haggai Maron
37th Annual Conference on Neural Information Processing Systems (NeurIPS 2023)
Spotlight Presentation
Summary
We demonstrate that sign equivariance is useful for applications such as building orthogonally equivariant models and link prediction. We develop novel sign equivariant neural network architectures based on an analytic characterization of the sign equivariant polynomials and thus inherit provable expressiveness properties.

Norm-Guided Latent Space Exploration for Text-to-Image Generation
Dvir Samuel, Rami Ben-Ari, Nir Darshan, Haggai Maron, Gal Chechik
37th Annual Conference on Neural Information Processing Systems (NeurIPS 2023)
Summary
We make the observation that current training procedures make diffusion models biased toward inputs with a narrow range of norm values. We propose a novel method for interpolating between two seeds that defines a new non-Euclidean metric taking into account a norm-based prior on seeds. We show that our new interpolation and centroid evaluation techniques significantly enhance the generation of rare concept images, leading to state-of-the-art performance on few-shot and long-tail benchmarks.

Equivariant Architectures for Learning in Deep Weight Spaces
Aviv Navon, Aviv Shamsian, Idan Achituve, Ethan Fetaya, Gal Chechik, Haggai Maron
International Conference on Machine Learning (ICML) 2023
Oral Presentation
Summary
We present a novel network architecture for learning in deep weight spaces. It takes as input a concatenation of weights and biases of a pre-trained MLP and processes it using a composition of layers that are equivariant to the natural permutation symmetry of the MLP's weights. We provide a full characterization of all affine equivariant and invariant layers for these symmetries and demonstrate the effectiveness of our architecture on a variety of learning tasks.

Graph Positional Encoding via Random Feature Propagation
Moshe Eliasof, Fabrizio Frasca, Beatrice Bevilacqua, Eran Treister, Gal Chechik, Haggai Maron
International Conference on Machine Learning (ICML) 2023
Summary
We propose Random Feature Propagation (RFP), a novel family of positional encoding schemes that draws a link between random features and spectral positional encoding. RFP is inspired by the power iteration method and concatenates several intermediate steps of an iterative algorithm for computing dominant eigenvectors of a propagation matrix, starting from random node features. RFP significantly outperforms both spectral PE and random features in multiple node classification and graph classification benchmarks.

Equivariant Polynomials for Graph Neural Networks
Omri Puny, Derek Lim, Bobak T. Kiani, Haggai Maron, Yaron Lipman
International Conference on Machine Learning (ICML) 2023
Oral Presentation
Summary
We introduce an alternative expressive power hierarchy for GNNs based on their ability to calculate equivariant polynomials of a certain degree. We provide a full characterization of all equivariant graph polynomials by introducing a concrete basis, significantly generalizing previous results. We propose algorithmic tools for evaluating the expressiveness of GNNs using tensor contraction sequences, and enhance the expressivity of common GNN architectures by adding polynomial features or additional operations inspired by our theory.
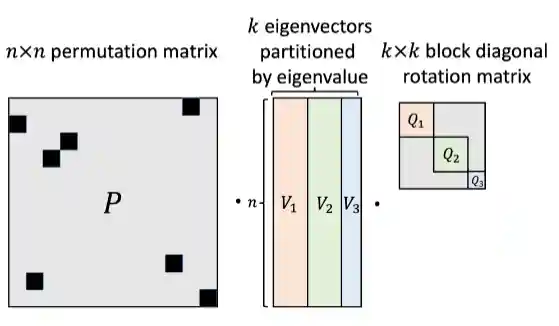
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Derek Lim*, Joshua Robinson*, Lingxiao Zhao, Tess Smidt, Suvrit Sra, Haggai Maron, Stefanie Jegelka
International Conference on Learning Representations (ICLR 2023)
Notable-top-25% (Spotlight)
Summary
We introduce SignNet and BasisNet – new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal and theoretically strong for graph representation learning – they can approximate any spectral graph convolution, compute spectral invariants beyond MPNNs, and provably simulate previously proposed graph positional encodings.
Weisfeiler and Leman go Machine Learning: The Story so far
Christopher Morris, Yaron Lipman, Haggai Maron, Bastian Rieck, Nils M. Kriege, Martin Grohe, Matthias Fey, Karsten Borgwardt
JMLR 2023
Summary
We give a comprehensive overview of the Weisfeiler-Leman algorithm's use in a machine learning setting, focusing on the supervised regime. We discuss the theoretical background, show how to use it for supervised graph- and node representation learning, discuss recent extensions, and outline the algorithm's connection to permutation-equivariant neural architectures.

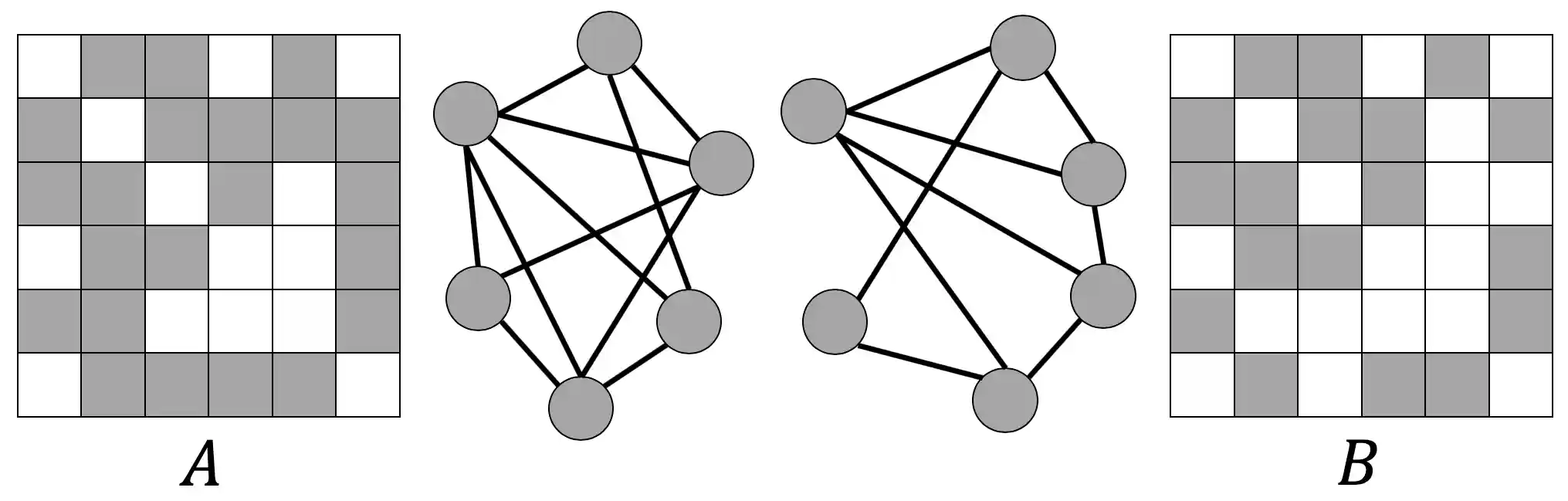
Understanding and Extending Subgraph GNNs by Rethinking Their Symmetries
Fabrizio Frasca*, Beatrice Bevilacqua*, Michael M. Bronstein, Haggai Maron
36th Annual Conference on Neural Information Processing Systems (NeurIPS 2022)
Oral Presentation (1.7% acceptance rate)
Summary
We study the most prominent form of subgraph methods employing node-based subgraph selection policies. A novel symmetry analysis shows that modeling the symmetries of node-based subgraph collections requires a significantly smaller symmetry group than the one adopted in previous works. We bound the expressive power of subgraph methods by 3-WL and propose SUN, a general family of message-passing layers for subgraph methods that generalizes all previous node-based Subgraph GNNs.
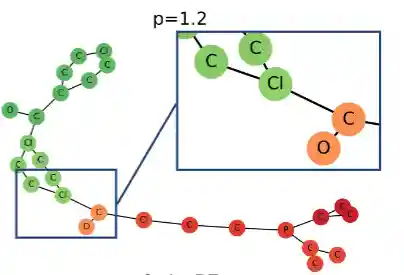
Generalized Laplacian Positional Encoding for Graph Representation Learning
Sohir Maskey*, Ali Parviz*, Maximilian Thiessen, Hannes Stärk, Ylli Sadikaj, Haggai Maron
NeurIPS 2022 Workshop on Symmetry and Geometry in Neural Representations
Summary
We define a novel family of positional encoding schemes for graphs by generalizing the optimization problem that defines the Laplace embedding to more general dissimilarity functions rather than the 2-norm used in the original formulation. This family of positional encodings is instantiated by considering p-norms and can improve the expressive power of MPNNs.
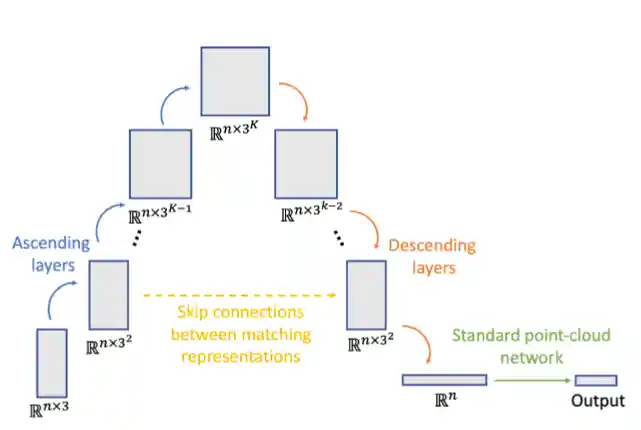
A Simple and Universal Rotation Equivariant Point-Cloud Network
Ben Finkelshtein, Chaim Baskin, Haggai Maron, Nadav Dym
Workshop on Topology, Algebra, and Geometry in Learning, ICML 2022

StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
Rinon Gal, Or Patashnik, Haggai Maron, Gal Chechik, Daniel Cohen-Or
ACM SIGGRAPH 2022
Summary
Leveraging the semantic power of large scale CLIP models, we present a text-driven method that allows shifting a generative model to new domains without collecting even a single image from those domains. Through natural language prompts and a few minutes of training, our method can adapt a generator across a multitude of domains characterized by diverse styles and shapes.

Multi-Task Learning as a Bargaining Game
Aviv Navon, Aviv Shamsian, Idan Achituve, Haggai Maron, Kenji Kawaguchi, Gal Chechik, Ethan Fetaya
International Conference on Machine Learning (ICML) 2022
Summary
We propose viewing the gradients combination step in MTL as a bargaining game, where tasks negotiate to reach an agreement on a joint direction of parameter update. Under certain assumptions, the bargaining problem has a unique solution, known as the Nash Bargaining Solution, which we propose to use as a principled approach to multi-task learning. We describe Nash-MTL and derive theoretical guarantees for its convergence, achieving state-of-the-art results on multiple benchmarks.

Optimizing Tensor Network Contraction Using Reinforcement Learning
Eli A Meirom, Haggai Maron, Shie Mannor, Gal Chechik
International Conference on Machine Learning (ICML) 2022
Summary
We propose an RL approach combined with GNNs to address the contraction ordering problem for quantum circuit simulation. We show how a carefully implemented RL-agent using a GNN as the basic policy construct can obtain significant improvements over state-of-the-art techniques in three varieties of circuits.
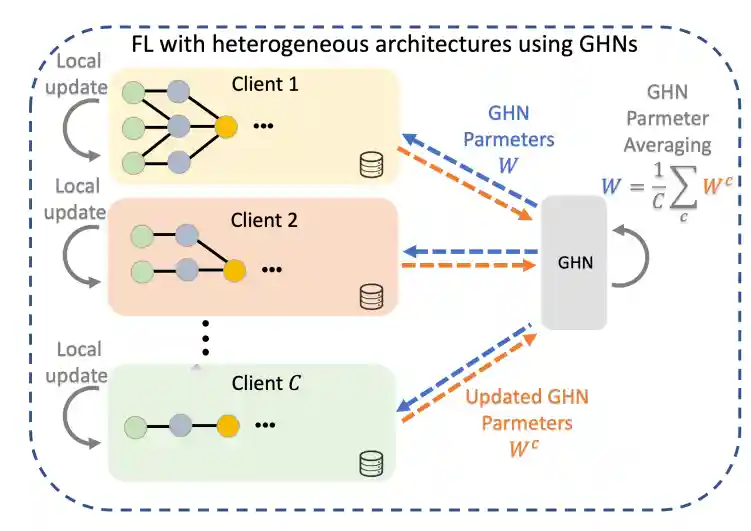
Federated Learning with Heterogeneous Architectures using Graph HyperNetworks
Or Litany, Haggai Maron, David Acuna, Jan Kautz, Gal Chechik, Sanja Fidler
Technical report, 2022
Summary
We propose a new FL framework that accommodates heterogeneous client architectures by adopting a graph hypernetwork for parameter sharing. Unlike existing solutions, our framework does not limit clients to sharing the same architecture type, makes no use of external data, and does not require clients to disclose their model architecture.

Equivariant Subgraph Aggregation Networks
Beatrice Bevilacqua*, Fabrizio Frasca*, Derek Lim*, Balasubramaniam Srinivasan, Chen Cai, Gopinath Balamurugan, Michael M. Bronstein, Haggai Maron (*equal contribution)
International Conference on Learning Representations (ICLR) 2022
Spotlight Presentation (5% acceptance rate)
Summary
We propose ESAN, a novel framework where each graph is represented as a set of subgraphs derived by some predefined policy, and processed using a suitable equivariant architecture. We develop novel variants of the 1-WL test for graph isomorphism and prove lower bounds on the expressiveness of ESAN. We further prove that our approach increases the expressive power of both MPNNs and more expressive architectures.
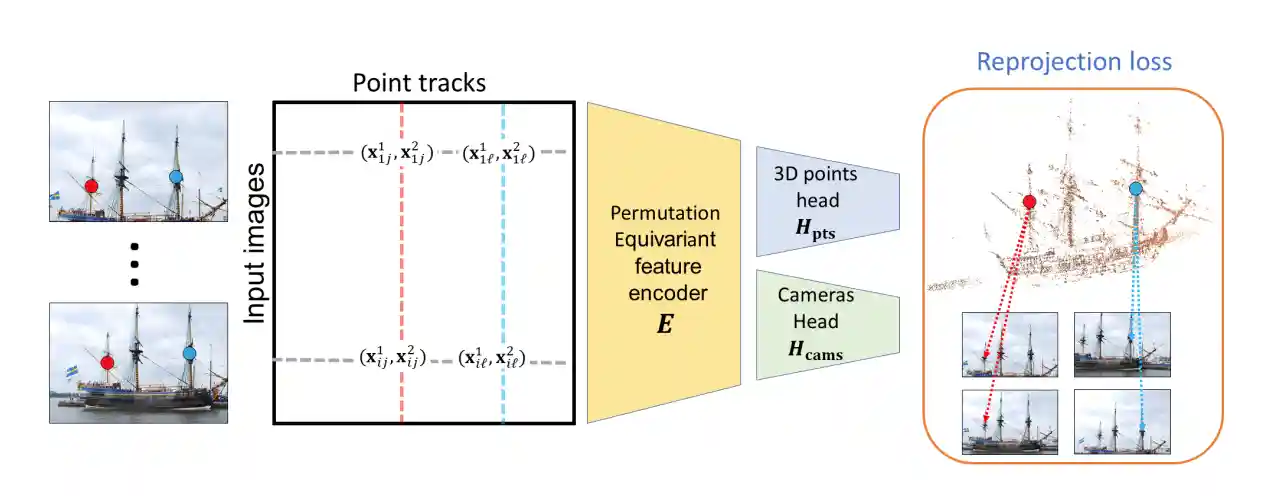
Deep Permutation Equivariant Structure from Motion
Dror Moran, Hodaya Koslowsky, Yoni Kasten, Haggai Maron, Meirav Galun, Ronen Basri
International Conference on Computer Vision (ICCV) 2021
Oral Presentation (3% acceptance rate)
Summary
We propose a neural network architecture that recovers both camera parameters and a sparse scene structure from point tracks in multiple images by minimizing an unsupervised reprojection loss. Our network architecture is designed to be equivariant to permutations of both cameras and scene points. We show that a pre-trained network can be used to reconstruct novel scenes using inexpensive fine-tuning with no loss of accuracy.

Secondary Vertex Finding in Jets with Neural Networks
Jonathan Shlomi, Sanmay Ganguly, Eilam Gross, Kyle Cranmer, Yaron Lipman, Hadar Serviansky, Haggai Maron, Nimrod Segol
European Physical Journal C, 2021
Summary
We use a neural network to perform vertex finding inside jets to improve jet classification performance, with a focus on b vs. c flavor tagging. We implement a novel, universal set-to-graph model, which takes into account information from all tracks in a jet to determine if pairs of tracks originated from a common vertex.
Scene-Agnostic Multi-Microphone Speech Dereverberation
Yochai Yemini, Ethan Fetaya, Haggai Maron, Sharon Gannot
INTERSPEECH 2021
Summary
We present an NN architecture that is able to cope with microphone arrays on which no prior knowledge is presumed, and demonstrate its applicability on the speech dereverberation problem. Our approach harnesses the Deep Sets framework to design an architecture that enhances the reverberant log-spectrum.

From Local Structures to Size Generalization in Graph Neural Networks
Gilad Yehudai, Ethan Fetaya, Eli Meirom, Gal Chechik, Haggai Maron
International Conference on Machine Learning (ICML) 2021
Summary
We put forward the size-generalization question and characterize important aspects theoretically and empirically. We show that even for very simple tasks, GNNs do not naturally generalize to graphs of larger size. Their generalization performance is closely related to the distribution of patterns of connectivity and features. We formalize size generalization as a domain-adaptation problem and describe two learning setups where it can be improved.
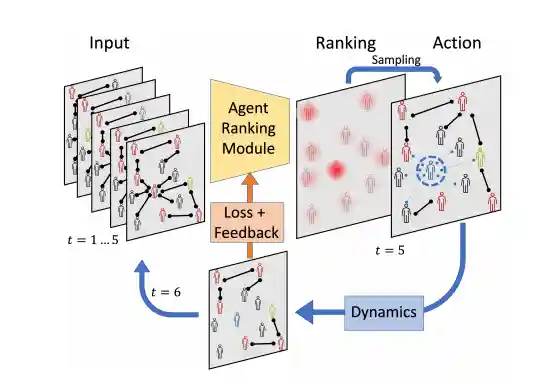
Controlling Graph Dynamics with Reinforcement Learning and Graph Neural Networks
Eli A Meirom, Haggai Maron, Shie Mannor, Gal Chechik
International Conference on Machine Learning (ICML) 2021
Summary
We formulate partially-observed dynamic graph processes (e.g., epidemic spread) as a sequential decision problem and design RLGN, a novel tractable RL scheme to prioritize which nodes should be tested, using GNNs to rank the graph nodes. RLGN consistently outperforms all baselines and can increase the number of healthy people by 25% and contain the epidemic 30% more often than supervised approaches using the same resources.

On the Universality of Rotation Equivariant Point Cloud Networks
Nadav Dym, Haggai Maron
International Conference on Learning Representations (ICLR) 2021
Summary
We present the first study of the approximation power of rotation-equivariant point cloud network architectures. We derive two sufficient conditions for an equivariant architecture to have the universal approximation property, and use these conditions to show that two recently suggested models are universal and to devise two other novel universal architectures.

Auxiliary Learning by Implicit Differentiation
Aviv Navon*, Idan Achituve*, Haggai Maron, Gal Chechik**, Ethan Fetaya** (*/** equal contribution)
International Conference on Learning Representations (ICLR) 2021
Summary
We propose AuxiLearn, a novel framework based on implicit differentiation that targets both designing useful auxiliary tasks and combining them into a single coherent loss. We propose learning a network that combines all losses into a single coherent objective function that can learn non-linear interactions between auxiliary tasks. AuxiLearn consistently improves accuracy compared with competing methods on image segmentation and learning with attributes.

Self-Supervised Learning for Domain Adaptation on Point-Clouds
Idan Achituve, Haggai Maron, Gal Chechik
Winter Conference on Applications of Computer Vision (WACV), 2021
Summary
We describe the first study of SSL for domain adaptation on point-clouds. We introduce a new pretext task, Region Reconstruction, motivated by deformations encountered in sim-to-real transformation, and combine it with a training procedure motivated by the MixUp method. Evaluations on six domain adaptations across synthetic and real furniture data demonstrate large improvement over previous work.

Set2Graph: Learning Graphs From Sets
Hadar Serviansky, Nimrod Segol, Jonathan Shlomi, Kyle Cranmer, Eilam Gross, Haggai Maron, Yaron Lipman
34th Annual Conference on Neural Information Processing Systems (NeurIPS 2020)
Summary
We suggest a neural network model family for learning Set2Graph functions that is both practical and of maximal expressive power (universal), that is, can approximate arbitrary continuous Set2Graph functions over compact sets. Testing our models on different machine learning tasks, including an application to particle physics, we find them favorable to existing baselines.

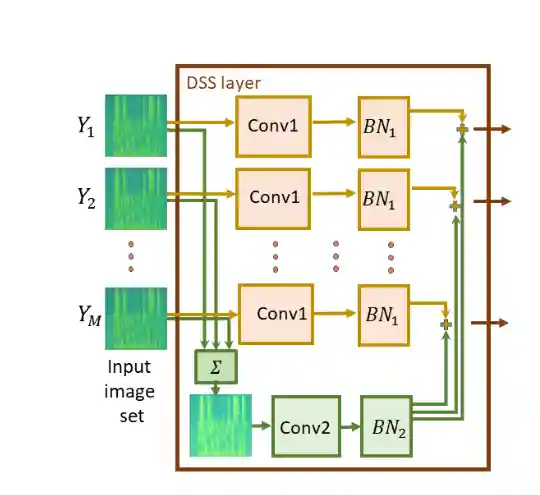
On Learning Sets of Symmetric Elements
Haggai Maron, Or Litany, Gal Chechik, Ethan Fetaya
International Conference on Machine Learning (ICML) 2020
ICML 2020 Outstanding Paper Award (Best Paper)
Summary
We present a principled approach to learning sets of general symmetric elements. We first characterize the space of linear layers that are equivariant both to element reordering and to the inherent symmetries of elements, like translation in the case of images. We show that networks composed of these layers (Deep Sets for Symmetric elements, DSS) are universal approximators of both invariant and equivariant functions, and they improve over existing set-learning architectures in experiments with images, graphs, and point-clouds.
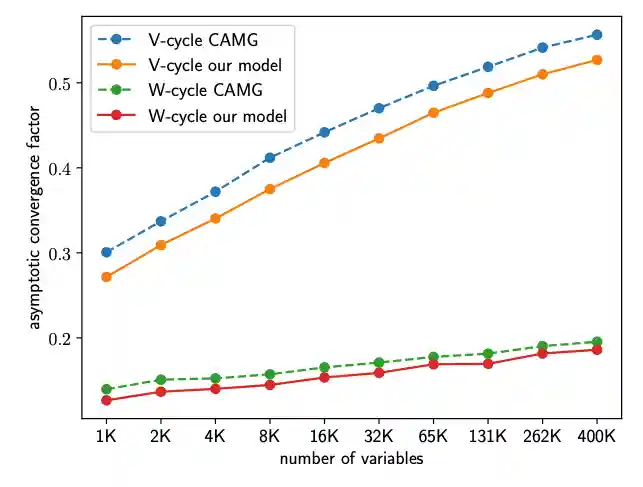
Learning Algebraic Multigrid Using Graph Neural Networks
Ilay Luz, Meirav Galun, Haggai Maron, Ronen Basri, Irad Yavneh
International Conference on Machine Learning (ICML) 2020
Summary
We propose a framework for learning AMG prolongation operators for linear systems with sparse symmetric positive (semi-)definite matrices. We train a single graph neural network to learn a mapping from an entire class of such matrices to prolongation operators, using an efficient unsupervised loss function. Experiments demonstrate improved convergence rates compared to classical AMG, demonstrating the potential utility of neural networks for developing sparse system solvers.
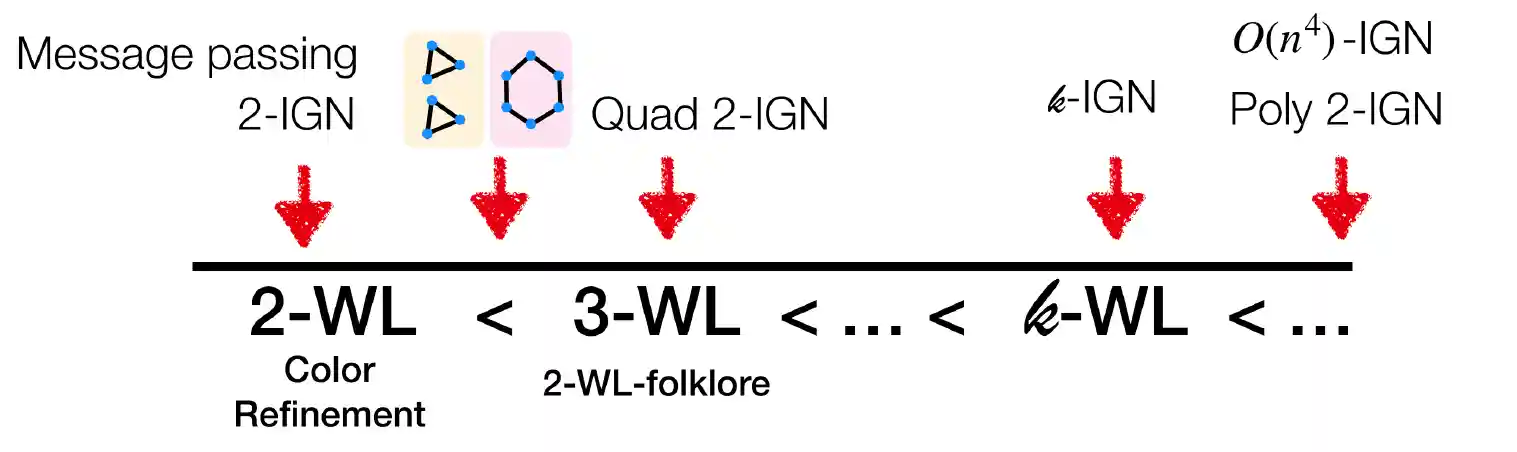
Open Problems: Approximation Power of Invariant Graph Networks
Haggai Maron, Heli Ben-Hamu, Yaron Lipman
NeurIPS 2019 Graph Representation Learning Workshop
Summary
We formulate several open problems aiming at characterizing the trade-off between expressive power and complexity of invariant and equivariant graph networks, building on recent work showing these models to be universal, in contrast to popular message passing models.

Ph.D. Thesis: Deep and Convex Shape Analysis
Haggai Maron
Weizmann Institute of Science, 2019
Summary
This dissertation summarizes the main results obtained during my Ph.D. studies at the Weizmann Institute of Science under the guidance of Professor Yaron Lipman. Two fundamental problems in shape analysis were considered: (1) how to apply deep learning techniques to irregular data and (2) how to compute meaningful maps between shapes. My work resulted in several novel methods for applying deep learning to surfaces, point clouds, graphs and hyper-graphs as well as new efficient techniques to solve relaxations of well-known matching problems.
Deep and Convex Shape Analysis
Haggai Maron
SIGGRAPH 2019 Doctoral Consortium
Summary
I review the main results obtained during my Ph.D. studies, considering two fundamental problems in shape analysis: (1) how to apply deep learning techniques to geometric objects and (2) how to compute meaningful maps between shapes. My work resulted in novel methods for applying deep learning to surfaces, point clouds, and hyper-graphs as well as new efficient techniques to solve relaxations of well-known matching problems.
Provably Powerful Graph Networks
Haggai Maron*, Heli Ben-Hamu*, Hadar Serviansky*, Yaron Lipman (*equal contribution)
33rd Annual Conference on Neural Information Processing Systems (NeurIPS 2019)
Summary
Building upon k-order invariant and equivariant graph neural networks, we present two results: First, we show that k-order networks can distinguish between non-isomorphic graphs as well as the k-WL tests, which are provably stronger than the 1-WL test for k > 2. Second, we show that a reduced 2-order network containing just scaled identity operator augmented with a single quadratic operation (matrix multiplication) has provable 3-WL expressive power. This model interleaves applications of MLP applied to the feature dimension and matrix multiplication, achieving state-of-the-art results on graph classification and regression tasks.
Controlling Neural Level Sets
Matan Atzmon, Niv Haim, Lior Yariv, Ofer Israelov, Haggai Maron, Yaron Lipman
33rd Annual Conference on Neural Information Processing Systems (NeurIPS 2019)
Summary
We present a simple and scalable approach to directly control level sets of a deep neural network. Our method consists of two parts: (i) sampling of the neural level sets, and (ii) relating the samples' positions to the network parameters via a sample network. We test our method on training networks robust to adversarial attacks, improving generalization to unseen data, and curve and surface reconstruction from point clouds.

Surface Networks via General Covers
Niv Haim*, Nimrod Segol*, Heli Ben-Hamu, Haggai Maron, Yaron Lipman (*equal contribution)
International Conference on Computer Vision (ICCV) 2019
Summary
We develop a novel surface-to-image representation based on a covering map from the image domain to the surface. The map wraps around the surface several times, providing a low distortion coverage of all surface parts in a single image. We use this representation to apply standard CNN models to semantic shape segmentation and shape retrieval, achieving state-of-the-art results.

On the Universality of Invariant Networks
Haggai Maron, Ethan Fetaya, Nimrod Segol, Yaron Lipman
International Conference on Machine Learning (ICML) 2019
Summary
We consider the fundamental question: Can G-invariant networks approximate any continuous invariant function? We tackle the general case where G ≤ S_n acts on R^n by permuting coordinates. We present two main results: First, G-invariant networks are universal if high-order tensors are allowed. Second, there are groups G for which higher-order tensors are unavoidable for obtaining universality.
Invariant and Equivariant Graph Networks
Haggai Maron, Heli Ben-Hamu, Nadav Shamir and Yaron Lipman
International Conference on Learning Representations (ICLR) 2019
Summary
We provide a characterization of all permutation invariant and equivariant linear layers for (hyper-)graph data, and show that their dimension, in case of edge-value graph data, is 2 and 15, respectively. More generally, for graph data defined on k-tuples of nodes, the dimension is the k-th and 2k-th Bell numbers. Orthogonal bases for the layers are computed. The constant number of basis elements and their characteristics allow successfully applying the networks to different size graphs.
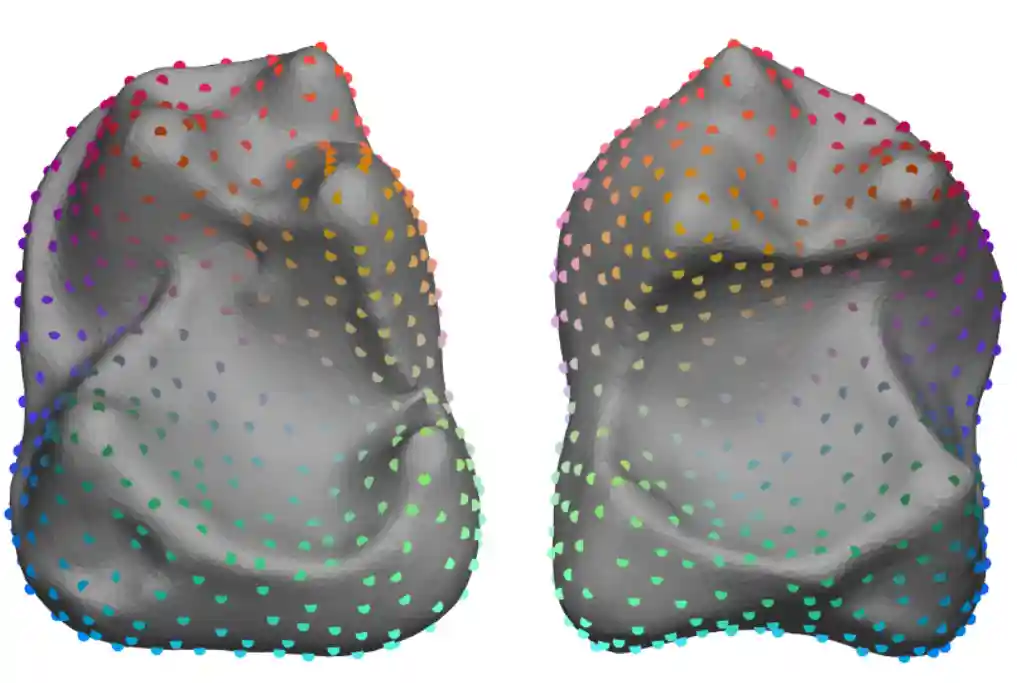
Sinkhorn Algorithm for Lifted Assignment Problems
Yam Kushinsky, Haggai Maron, Nadav Dym and Yaron Lipman
SIAM Journal on Imaging Sciences, 2019
Summary
We generalize the Sinkhorn projection algorithm to higher dimensional polytopes originated from well-known lifted linear program relaxations of the Markov Random Field (MRF) energy minimization problem and the Quadratic Assignment Problem (QAP). We derive a closed-form projection on one-sided local polytopes and devise a provably convergent algorithm to solve regularized linear program relaxations of MRF and QAP.

(Probably) Concave Graph Matching
Haggai Maron and Yaron Lipman
32nd Annual Conference on Neural Information Processing Systems (NeurIPS 2018)
Spotlight Presentation (3.5% acceptance rate)
Summary
We analyze and generalize the idea of concave relaxations for graph matching. We introduce the concepts of conditionally concave and probably conditionally concave energies on polytopes and show that they encapsulate many instances of the graph matching problem, including matching Euclidean graphs and graphs on surfaces. We prove that local minima of probably conditionally concave energies on general matching polytopes are with high probability extreme points.

Multi-Chart Generative Surface Modeling
Heli Ben-Hamu, Haggai Maron, Itay Kezurer, Gal Avineri and Yaron Lipman
ACM SIGGRAPH Asia 2018
Summary
A new image-like tensor data representation for genus-zero 3D shapes is devised, based on multiple parameterizations (charts) focusing on different parts of the shape. The new tensor representation is used as input to Generative Adversarial Networks for 3D shape generation, learning the shape distribution and enabling generation of novel shapes, interpolation, and exploration of the generated shape space.

Point Convolutional Neural Networks by Extension Operators
Matan Atzmon*, Haggai Maron* and Yaron Lipman (*equal contribution)
ACM SIGGRAPH 2018
Summary
We present Point Convolutional Neural Networks (PCNN): a novel framework for applying convolutional neural networks to point clouds. The framework consists of extension and restriction operators, mapping point cloud functions to volumetric functions and vice-versa. PCNN is computationally efficient, invariant to the order of points, robust to different samplings and varying densities, and translation invariant. Evaluation on three central point cloud learning benchmarks convincingly outperforms competing methods.

DS++: A Flexible, Scalable and Provably Tight Relaxation for Matching Problems
Nadav Dym*, Haggai Maron* and Yaron Lipman (*equal contribution)
ACM SIGGRAPH Asia 2017
Summary
We present a convex quadratic programming relaxation which is provably stronger than both DS and spectral relaxations, with the same scalability as the DS relaxation. The derivation naturally suggests a projection method for achieving meaningful integer solutions. Our method can be extended to optimization over doubly stochastic matrices, partial or injective matching, and problems with additional linear constraints.

Convolutional Neural Networks on Surfaces via Seamless Toric Covers
Haggai Maron, Meirav Galun, Noam Aigerman, Miri Trope, Nadav Dym, Ersin Yumer, Vladimir G. Kim and Yaron Lipman
ACM SIGGRAPH 2017
Summary
We present a method for applying deep learning to sphere-type shapes using a global seamless parameterization to a planar flat-torus, for which the convolution operator is well defined. This allows standard deep learning frameworks to be readily applied for learning semantic, high-level properties of the shape. We demonstrate success in human body segmentation and automatic landmark detection on anatomical surfaces.
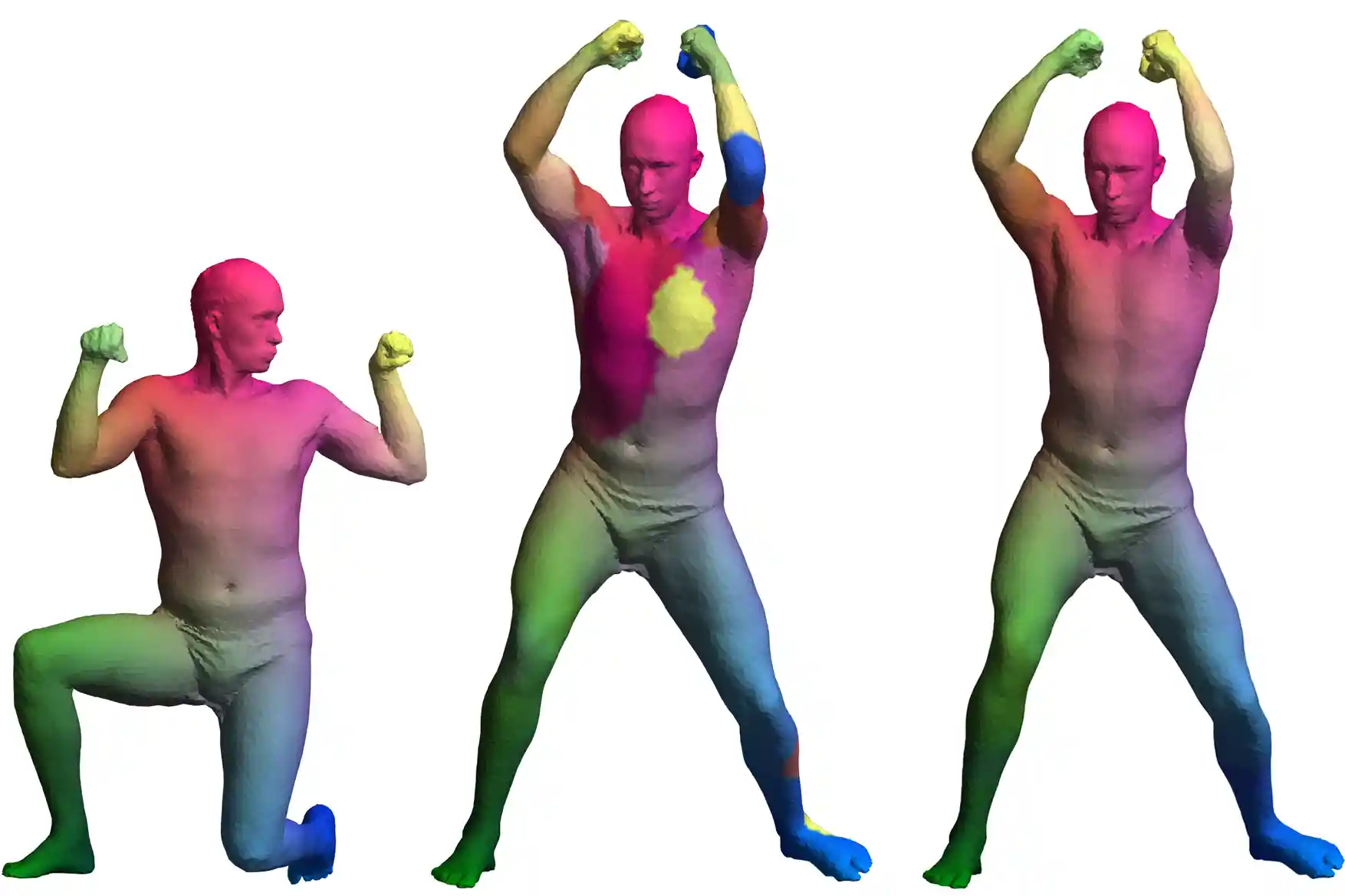
Point Registration via Efficient Convex Relaxation
Haggai Maron, Nadav Dym, Itay Kezurer, Shahar Kovalsky and Yaron Lipman
ACM SIGGRAPH 2016
Summary
We introduce a novel and efficient convex SDP relaxation for the Procrustes Matching (PM) problem. We prove that for generic isometric or almost-isometric problems the algorithm returns a correct global solution. We show our algorithm gives state-of-the-art results on popular shape matching datasets and for anatomical classification of shapes.

Passive Light and Viewpoint Sensitive Display of 3D Content
Anat Levin, Haggai Maron and Michal Yarom
International Conference on Computational Photography (ICCP) 2016
Summary
We present a 3D light-sensitive display capable of presenting simple opaque 3D surfaces without self-occlusions, while reproducing both viewpoint-sensitive depth parallax and illumination-sensitive variations such as shadows and highlights. Our display is passive and uses two layers of Spatial Light Modulators whose micron-sized elements allow us to digitally simulate thin optical surfaces with flexible shapes.