1000+
Enterprise Deployments
Petabytes
Data Processed Daily
Trusted by enterprises worldwide for mission-critical data analytics
Battle-Tested Performance
Over 18 years of development and optimization, handling petabytes of data in production environments across the globe.
Vibrant Ecosystem
Seamlessly integrates with Spark, Presto, Impala, and hundreds of other tools in the modern data stack.
SQL-First Approach
Familiar SQL interface makes it easy for data analysts and engineers to work with big data without learning new languages.
Cloud-Native Ready
Native support for S3, Azure Data Lake, Google Cloud Storage, and other cloud storage systems.
Enterprise Security
Comprehensive security features including Kerberos authentication, fine-grained access control, and audit logging.
Apache Foundation
Backed by the Apache Software Foundation with a strong commitment to open source principles and community governance.
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale.
Central Metadata Repository
Hive Metastore (HMS) provides a central repository of metadata that can easily be analyzed to make informed, data driven decisions, making it a critical component of many data lake architectures.
SQL Analytics at Scale
Built on top of Apache Hadoop with support for S3, ADLS, GS and more. Hive allows users to read, write, and manage petabytes of data using familiar SQL syntax.
beeline -u "jdbc:hive2://host:10001/default" Connected to: Apache Hive jdbc:hive2://host:10001/>select count(*) from test_t1;
HiveServer2 (HS2)
HS2 supports multi-client concurrency and authentication with better support for open API clients like JDBC and ODBC, enabling seamless integration with business intelligence tools and applications.
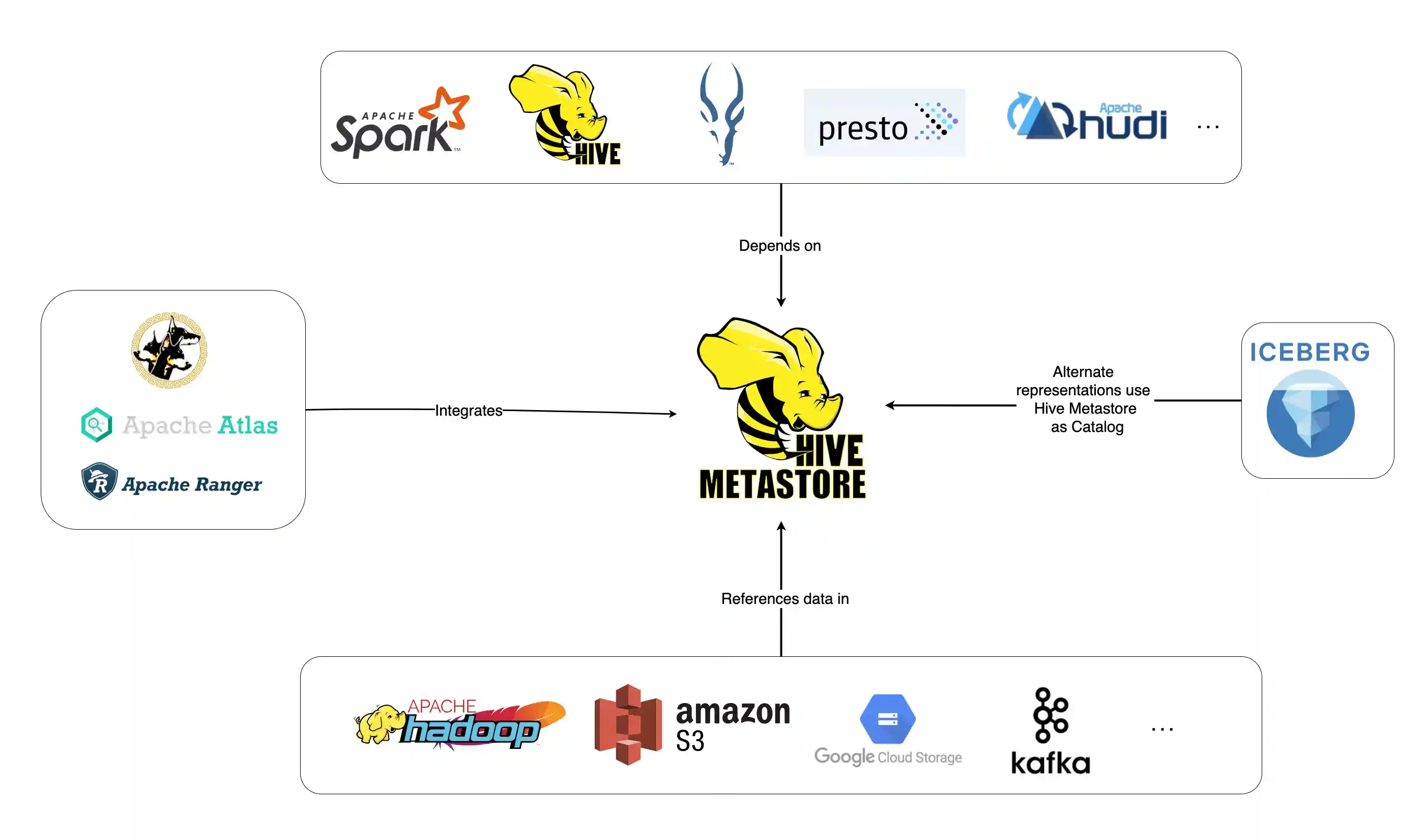
Hive Metastore Server (HMS)
The central repository of metadata for Hive tables and partitions, providing clients including Hive, Impala, and Spark access through the metastore service API. A fundamental building block for modern data lakes.

ACID Transactions
Full ACID support for ORC tables and insert-only support for all other formats, ensuring data consistency and reliability in concurrent environments.
jdbc:hive2://> alter table test_t1 compact "MAJOR"; Done! jdbc:hive2://> alter table test_t1 compact "MINOR"; Done! jdbc:hive2://> show compactions;
Data Compaction
Query-based and MapReduce-based data compactions are supported out-of-the-box, optimizing storage efficiency and query performance.

Apache Iceberg Support
Out-of-the-box support for Apache Iceberg tables, a cloud-native, high-performance open table format, via Hive StorageHandler for modern data lake architectures.
Security & Observability
Enterprise-grade security with Kerberos authentication and seamless integration with Apache Ranger for authorization and Apache Atlas for data lineage and governance.

Low Latency Analytics (LLAP)
Interactive and sub-second SQL queries through persistent query infrastructure and optimized data caching, making Hive suitable for real-time analytics workloads.
jdbc:hive2://> explain cbo select ss.ss_net_profit, sr.sr_net_loss from store_sales ss join store_returns sr on (ss.ss_item_sk=sr.sr_item_sk) limit 5 ; +---------------------------------------------+ Explain +---------------------------------------------+ CBO PLAN: HiveSortLimit(fetch=[5]) HiveProject(ss_net_profit=[$1], sr_net_loss=[$3]) HiveJoin(condition=[=($0, $2)], joinType=[inner]) HiveProject(ss_item_sk=[$2], ss_net_profit=[$22]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_sales]], table:alias=[ss]) HiveProject(sr_item_sk=[$2], sr_net_loss=[$19]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_returns]], table:alias=[sr]) +---------------------------------------------+
Cost-Based Optimizer
Apache Calcite's cost-based query optimizer (CBO) and execution framework automatically optimize SQL queries for optimal performance and resource utilization.
jdbc:hive2://> repl dump src with ( 'hive.repl.dump.version'= '2', 'hive.repl.rootdir'= 'hdfs://<host>:<port>/user/replDir/d1' ); Done! jdbc:hive2://> repl load src into tgt with ( 'hive.repl.rootdir'= 'hdfs://<host>:<port>/user/replDir/d1' ); Done!
Data Replication
Bootstrap and incremental replication capabilities for robust backup and disaster recovery, ensuring business continuity and data protection.
Ready to Get Started with Apache Hive?
Join thousands of organizations using Apache Hive to power their data analytics and build modern data lakes.