Haoyu Ma
Selected Publications [Full List]
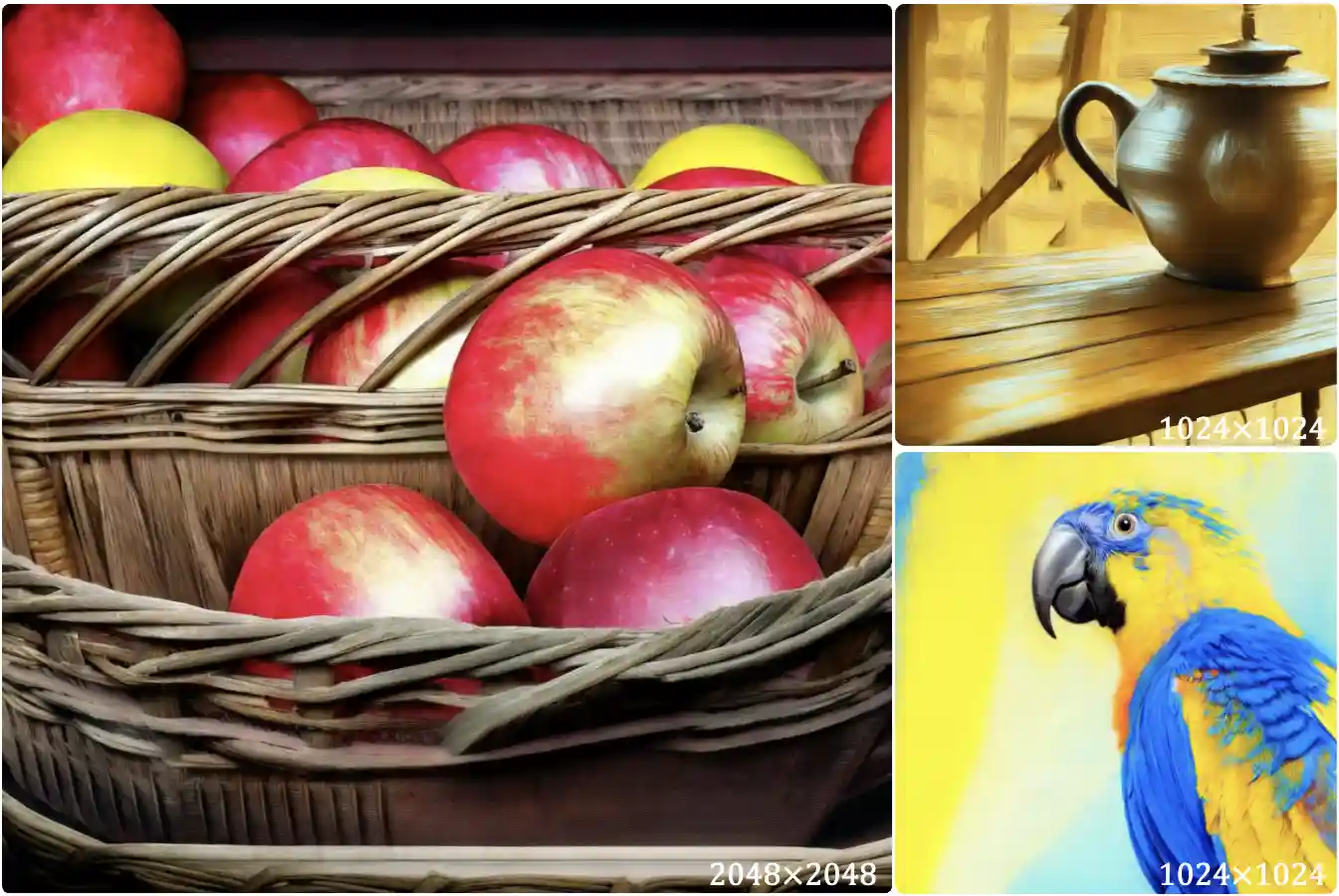
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
X. Ma, P. Sun, H. Ma, H. Tang, CY. Ma, J. Wang, K. Li, X. Dai, et al
Preprint, 2025.
[ Paper ] [ Project Page ]

MoCha: Towards Movie-Grade Talking Character Synthesis
C. Wei, B. Sun, H. Ma, J. Hou, F. Xu, Z. He, X. Dai, L. Zhang, K. Li, T. Hou, A. Sinha, P. Vajda, W. Chen
Advances in Neural Information Processing Systems (NeurIPS), 2025. (Spotlight)
[ Paper ] [ Project Page ]
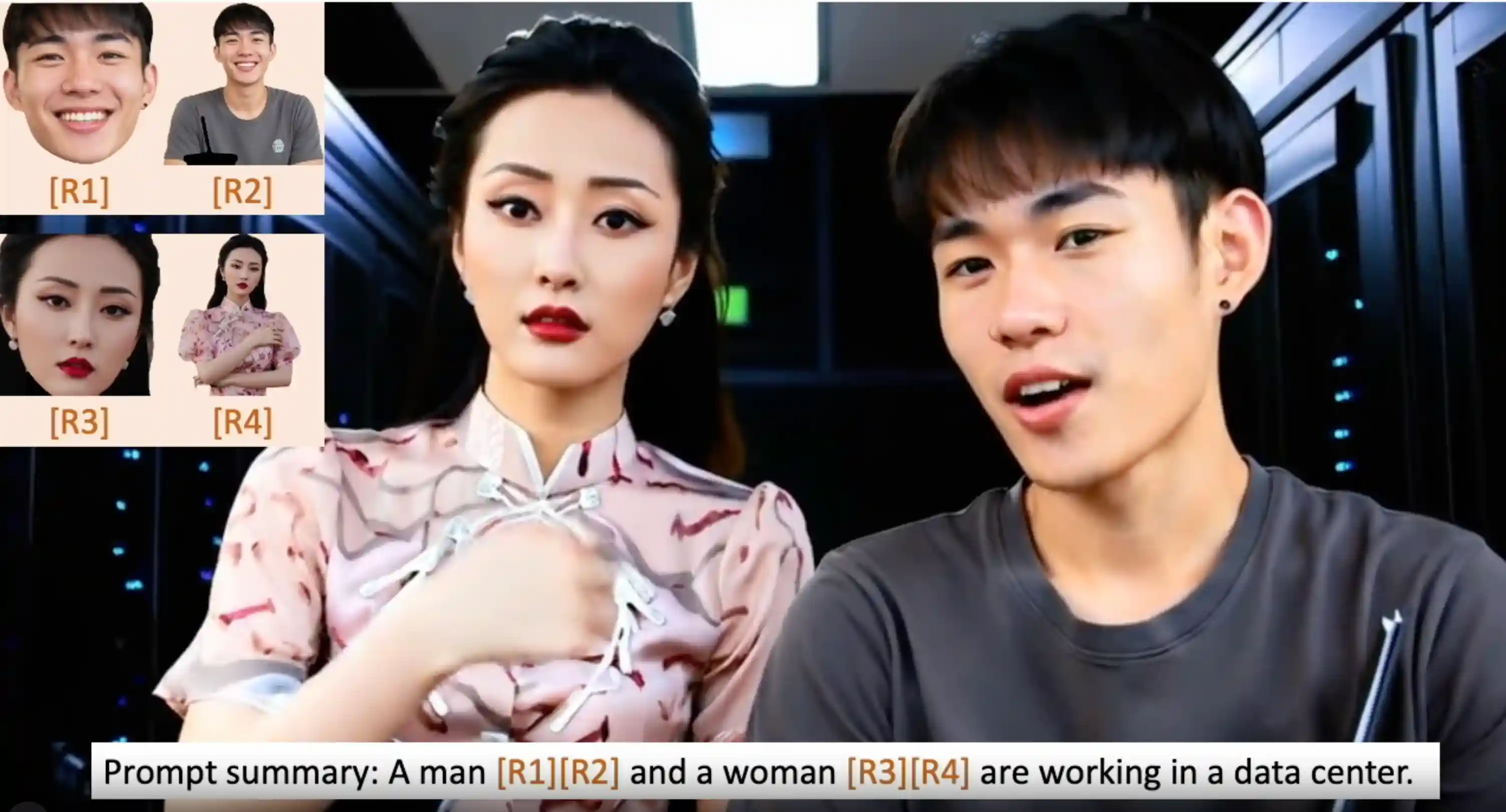
Movie Weaver: Tuning-Free Multi-Concept Video Personalization with Anchored Prompts
F. Liang, H. Ma, Z. He, T. Hou, J. Hou, K. Li, X. Dai, F. Xu, S. Azadi, A. Sinha, P. Zhang, P. Vajda, D. Marculescu
Computer Vision and Pattern Recognition Conference (CVPR), 2025.
[ Paper ] [ Project Page ]
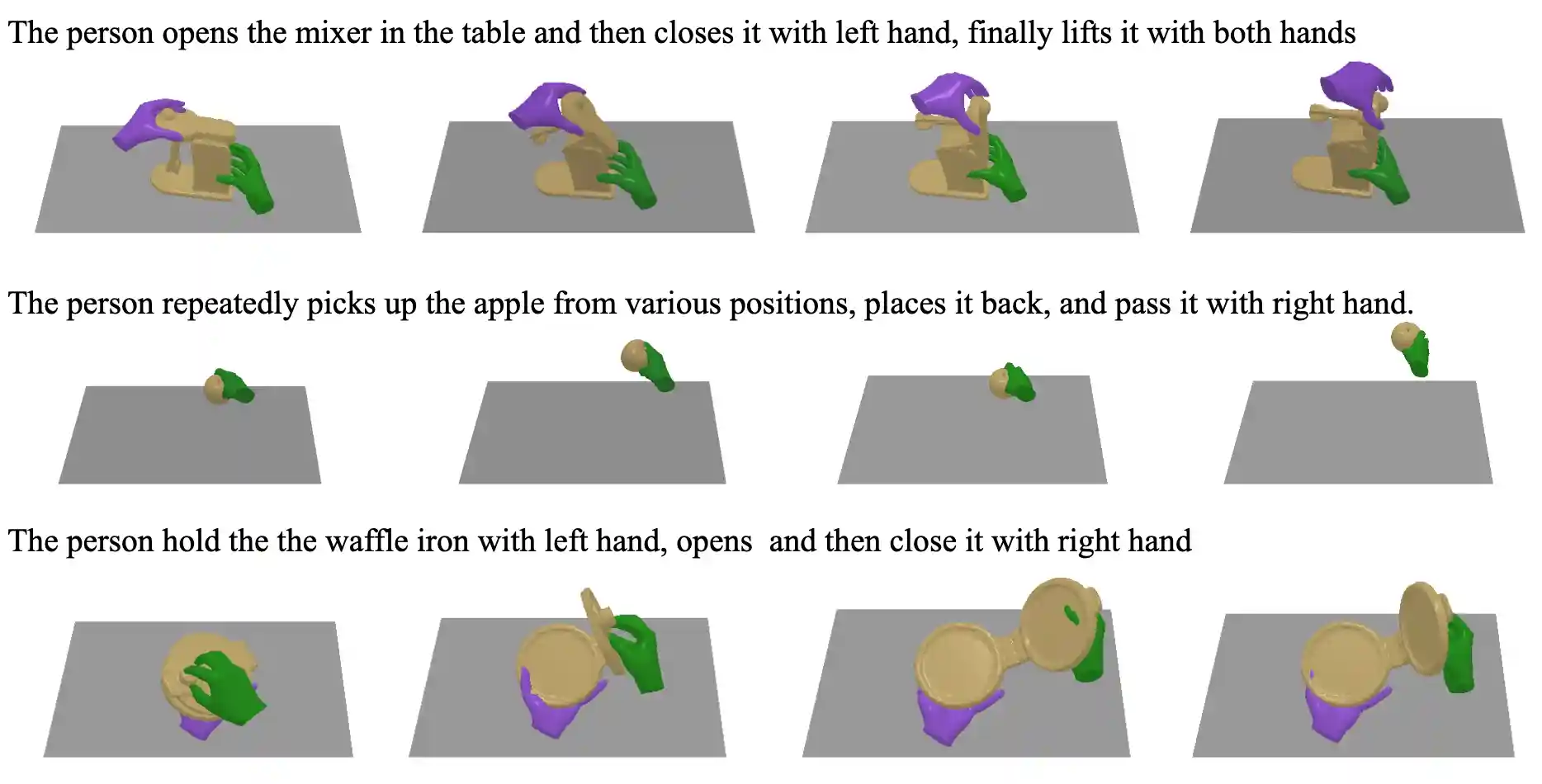
HOIGPT: Learning Long-Sequence Hand-Object Interaction with Language Models
M. Huang, FJ. Chu, B. Tekin, K. Liang, H. Ma, W. Wang, X. Chen, P. Gleize, H. Xue, S. Lyu, K. Kitani, M. Feiszli, H. Tang
Computer Vision and Pattern Recognition Conference (CVPR), 2025.
[ Paper ]

Movie Gen: A Cast of Media Foundation Models
Core Contributor
Preprint, 2024.
[ Paper ] [ Project Page ]

Imagine yourself: Tuning-Free Personalized Image Generation
Z. He , B. Sun , F. Xu, H. Ma, A. Ramchandani, V. Cheung, S. Shah, A. Kalia, N. Zhang, P. Zhang, R. Sumbaly, P. Vajda, A. Sinha
Preprint, 2024.
[ Paper ]
Before PhD graduation
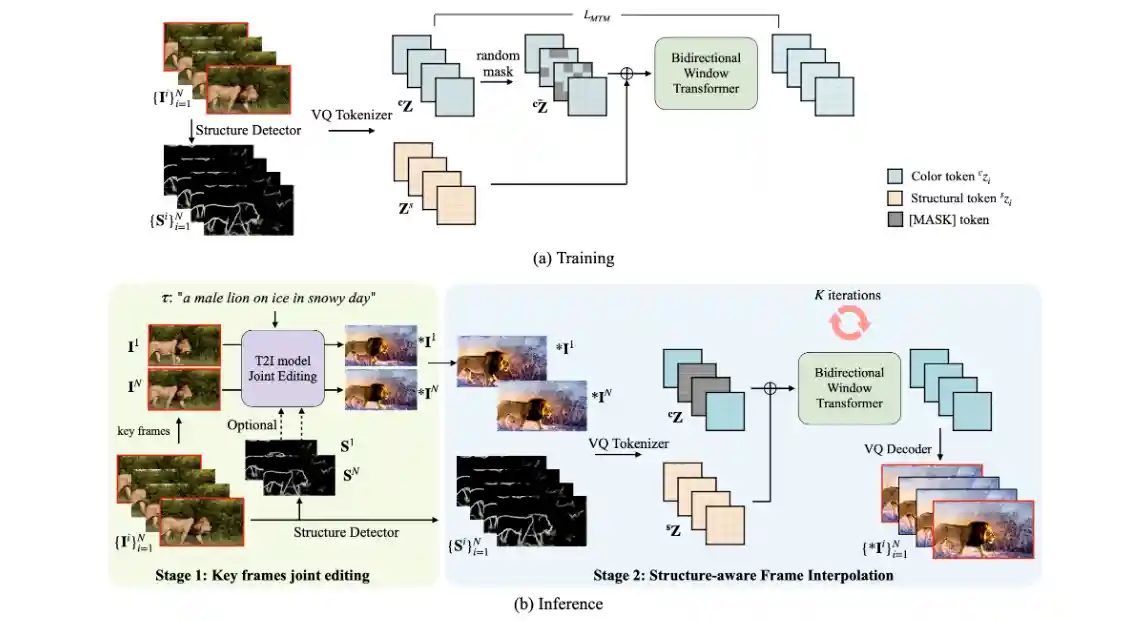
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
H. Ma, S. Mahdizadehaghdam, B. Wu, Z. Fan, Y. Gu, Z. Zhao, L. Shapira and X. Xie
Computer Vision and Pattern Recognition Conference (CVPR), 2024.
[ Paper ] [ Project Page ]
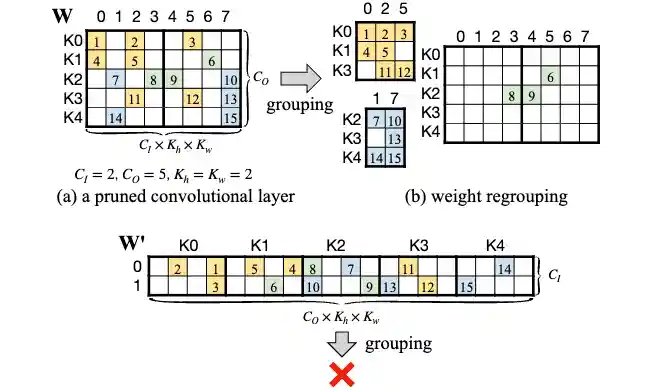
HRBP: Hardware-friendly Regrouping towards Block-based Pruning for Sparse CNN Training
H. Ma, C. Zhang, L. Xiang, X. Ma, G. Yuan, W. Zhang, S. Liu, T. Chen, D. Tao, Y. Wang, Z. Wang, and X. Xie
Conference on Parsimony and Learning (CPAL), 2024.
[ Paper ] [ Code ] [ Slides ]

CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
H. Ma, T. Zhang, S. Sun, X. Yan, K. Han, and X. Xie
IEEE Winter Conference on Applications of Computer Vision (WACV), 2024.
[ Paper ] [ Code ] [ Poster ] [ Slides ]
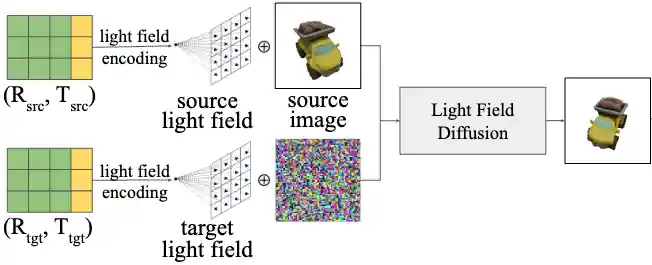
Light Field Diffusion for Single-View Novel View Synthesis
Y. Xiong, H. Ma, S. Sun, K. Han, H. Tang, and X. Xie
Arxiv Preprint, 2023.
[ Paper ] [ Project Page ]
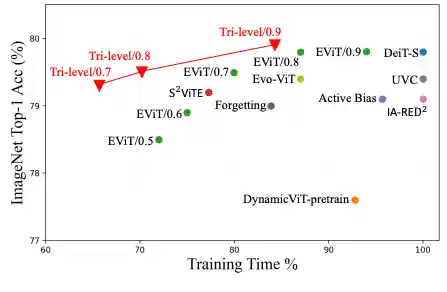
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training
Z. Kong*, H. Ma*, G. Yuan*, M. Sun, Y. Xie, P. Dong, X. Meng, X. Shen, H. Tang, M. Qin, T. Chen, X. Ma, X. Xie, Z. Wang, and Y. Wang
Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 2023.
[ Paper ] [ Code ]
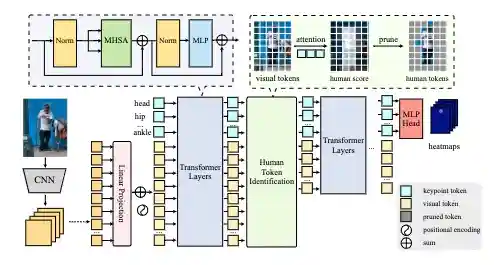
PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation
H. Ma, Z. Wang, Y. Chen, D. Kong, L. Chen, X. Liu, X. Yan, H. Tang, and X. Xie
European Conference on Computer Vision (ECCV), 2022.
[ Paper ] [ Code ] [ Poster ]
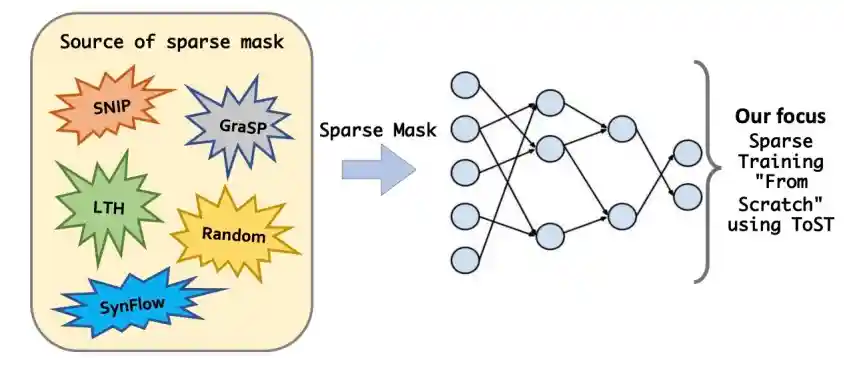
Training Your Sparse Neural Network Better with Any Mask
A. Jaiswal, H. Ma, T. Chen, Y. Ding, and Z. Wang
International Conference on Machine Learning (ICML), 2022.
[ Paper ] [ Code ]
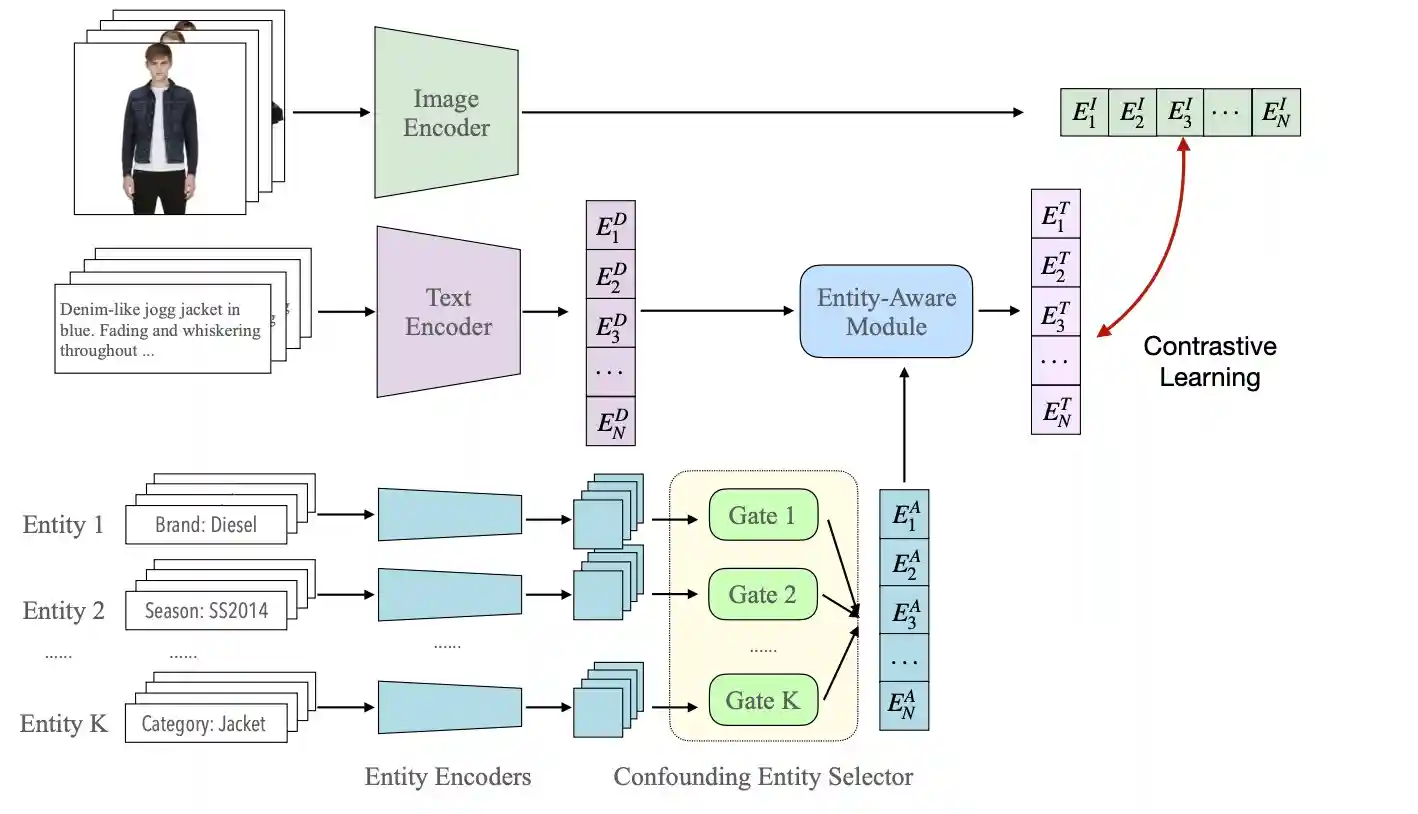
EI-CLIP: Entity-aware Interventional Contrastive Learning for E-commerce Cross-modal Retrieval
H. Ma, H. Zhao, Z. Lin, A. Kale, Z. Wang, T. Yu, J. Gu, S. Choudhary, and X. Xie
Computer Vision and Pattern Recognition Conference (CVPR), 2022.
[ Paper ] [ Poster ]
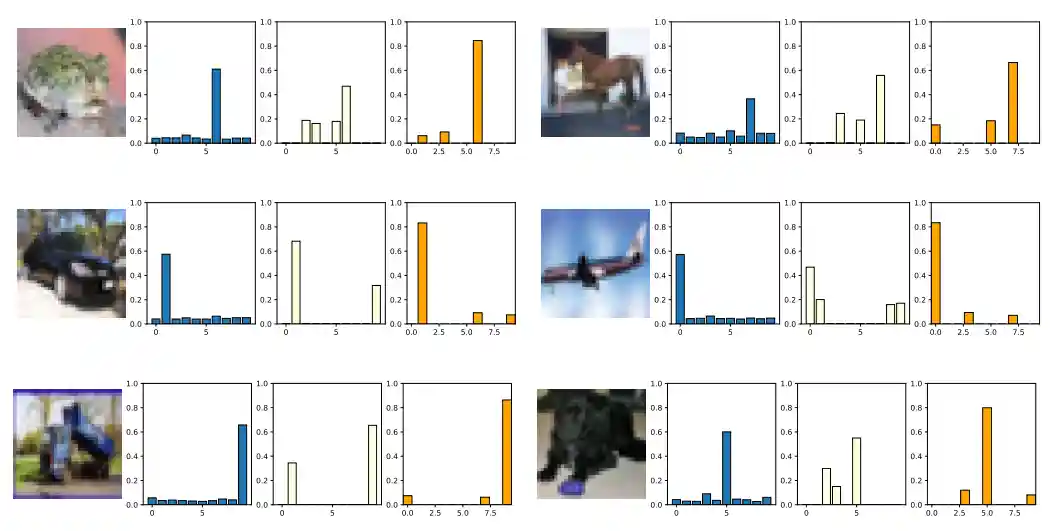
Sparse Logits Suffice to Fail Knowledge Distillation
H. Ma, Y. Huang. H. Tang, C. You, D. Kong, and X. Xie
International Conference on Learning Representations (ICLR) Workshop on PAIR^2Struct, 2022
[ Paper ] [ Code ] [ Poster ]
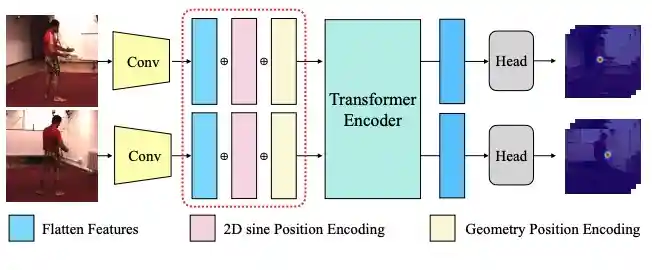
TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation
H. Ma, L. chen, D. Kong, Z. Wang, X. Liu, H. Tang, X. Yan, Y. Xie, S. Lin, and X. Xie
British Machine Vision Virtual Conference (BMVC), 2021.
[ Paper ] [ Code ] [ Presentation ] [ Slides ]
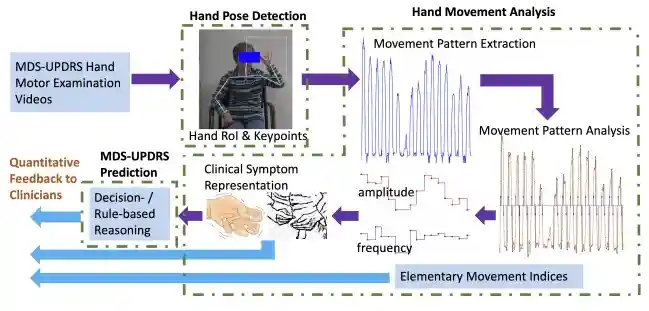
PD-Net: Quantitative Motor Function Evaluation for Parkinson's Disease via Automated Hand Gesture Analysis
Y. Chen, H. Ma, J. Wang, J. Wu, X. Wu, and X. Xie
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2021.
[ Paper ]

Undistillable: Making A Nasty Teacher That CANNOT Teach Students
H. Ma, T. Chen, T. Hu, C. You, X. Xie, and Z. Wang
International Conference on Learning Representations (ICLR), 2021. (Spotlight)
[ Paper ] [ Code ] [ Presentation ] [ Slides ] [ Poster ]

SIA-GCN: A Spatial Information Aware Graph Neural Network with 2D Convolutions for Hand Pose Estimation
D. Kong, H. Ma and X. Xie
British Machine Vision Virtual Conference (BMVC), 2020. (Oral)
[ Paper ]

Nonparametric Structure Regularization Machine for 2D Hand Pose Estimation
Y. Chen*, H. Ma*, D. Kong, X. Yan, J. Wu, W. Fan, and X. Xie
IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
[ Paper ] [ Code ] [ Presentation ] [ Slides ] [ Poster ]
