Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
MindEye2:
Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Paul S. Scotti1,2, Mihir Tripathy†2, Cesar Kadir Torrico Villanueva†2, Reese Kneeland†3, Tong Chen4,2, Ashutosh Narang2, Charan Santhirasegaran2, Jonathan Xu5,2, Thomas Naselaris3, Kenneth A. Norman6, Tanishq Mathew Abraham1,2
1Stability AI, 2Medical AI Research Center (MedARC),
3University of Minnesota, 4The University of Sydney, 5University of Waterloo, 6Princeton Neuroscience Institute.
(† indicates core contribution)
Methods
MindEye2 is first trained using data from 7 subjects in the Natural Scenes Dataset and then fine-tuned using a target held-out subject who may have scarce training data. The fMRI activity is initially mapped to a shared-subject latent space via subject-specific ridge regression. The rest of the model is subject-agnostic, consisting of an MLP backbone and a diffusion prior which are used to output predicted CLIP embeddings which are reconstructed into images using our SDXL unCLIP model. The diffusion prior helps bridge the modality gap between CLIP latent space and the fMRI latents generated by the MLP backbone. The alignment to shared-subject space is not trained independently—the whole pipeline is trained end-to-end where pretraining involves each batch containing brain inputs from all subjects.
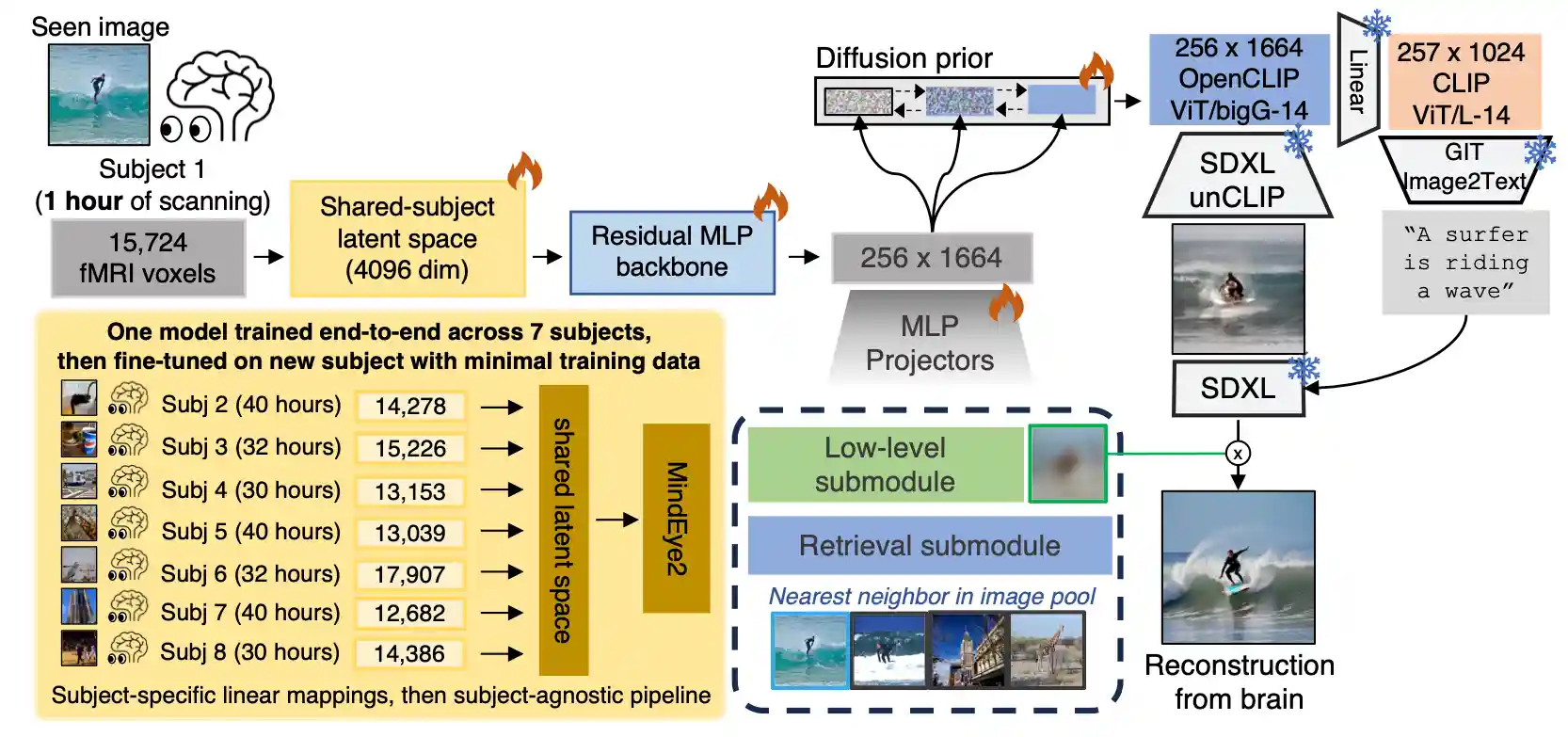
UnCLIP (or “image variations”) models have previously been used for the creative application of returning variations of a given reference image. Contrary to this, our goal was to train a model that returns images as close as possible to the reference image across both low-level structure and high-level semantics. For this use-case, we observed that existing unCLIP models do not accurately reconstruct images from their ground truth CLIP image embeddings (see below Figure). We therefore fine-tuned our own unCLIP model (using the 256 x 1664 dim. image embeddings from OpenCLIP ViT-bigG/14) from Stable Diffusion XL to support this goal, leading to much higher fidelity reconstructions from ground truth CLIP embeddings. For MindEye2, we can use OpenCLIP embeddings predicted from the brain instead of the ground truth embeddings to reconstruct images. This change increases the ceiling possible performance for fMRI-to-image reconstructions as it is no longer limited by the performance of the pre-trained frozen unCLIP model.

Results
MindEye2 achieves state-of-the-art image retrieval, image reconstruction and caption generation metrics across multiple subjects, and enables high quality image generation with just 2.5% of the previously required data (i.e., 1 hour of training data instead of 40 hours). That is, given a sample of fMRI activity from a participant viewing an image, MindEye can identify either which image out of a pool of possible image candidates was the original seen image (retrieval), or it can recreate the image that was seen (reconstruction) along with its text caption. These results can be generated by fine-tuning the pre-trained model with just an hour of fMRI data from a new subject.
Qualitative comparison above confirms that in the 1-hour training data setting, MindEye2 outperforms other methods, and that specifically pre-training on other subjects’ data helps to enable such performance. See preprint for quantitative comparisons.
If we use the full 40 hours of training data instead of 1, we also achieve SOTA performance for reconstruction and retrieval. We found that the 1-hour setting offered a good balance between scan duration and reconstruction performance, with notable improvements from first pre-training on other subjects.

Acknowledgements
Special thanks to Dustin Podell, Vikram Voleti, Andreas Blattmann, and Robin Rombach for technical assistance fine-tuning Stable Diffusion XL to support our unCLIP usecase. Thanks to the MedARC Discord community for being the public forum from which this research was developed, particularly thank you to Connor Lane, Alex Nguyen, Atmadeep Bannerjee, Amir Refaee, and Mohammed Baharoon for their helpful discussions. Thanks to Alessandro Gifford and Connor Lane for providing useful feedback on drafts of the manuscript. Thank you to Richard Vencu for help navigating the Stability AI HPC. Thanks to Stability AI for their support for open neuroAI research and providing the computational resources necessary to develop MindEye2. Collection of the Natural Scenes Dataset was supported by NSF IIS-1822683 and NSF IIS-1822929. This webpage template was recycled from here.