SOCIAL MEDIA TITLE TAG
GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object Manipulation
1Institute of Automation, Chinese Academy of Sciences,
2School of Artificial Intelligence, University of Chinese Academy of Sciences,
3Beijing Academy of Artificial Intelligence,
4CFCS, School of Computer Science, Peking University
5Carnegie Mellon University
6University of California, Berkeley
7Xi'an Jiaotong-Liverpool University
8Galbot
*Equal Contribution
†Corresponding Author
ICRA 2025
Abstract
Effectively manipulating articulated objects in household scenarios is a crucial step toward achieving general embodied artificial intelligence. Mainstream research in 3D vision has primarily focused on manipulation through depth perception and pose detection. However, in real-world environments, these methods often face challenges due to imperfect depth perception, such as with transparent lids and reflective handles. Moreover, they generally lack the diversity in part-based interactions required for flexible and adaptable manipulation. To address these challenges, we introduced a large-scale part-centric dataset for articulated object manipulation that features both photo-realistic material randomization and detailed annotations of part-oriented, scene-level actionable interaction poses. We evaluated the effectiveness of our dataset by integrating it with several state-of-the-art methods for depth estimation and interaction pose prediction. Additionally, we proposed a novel modular framework that delivers superior and robust performance for generalizable articulated object manipulation. Our extensive experiments demonstrate that our dataset significantly improves the performance of depth perception and actionable interaction pose prediction in both simulation and real-world scenarios.
Dataset
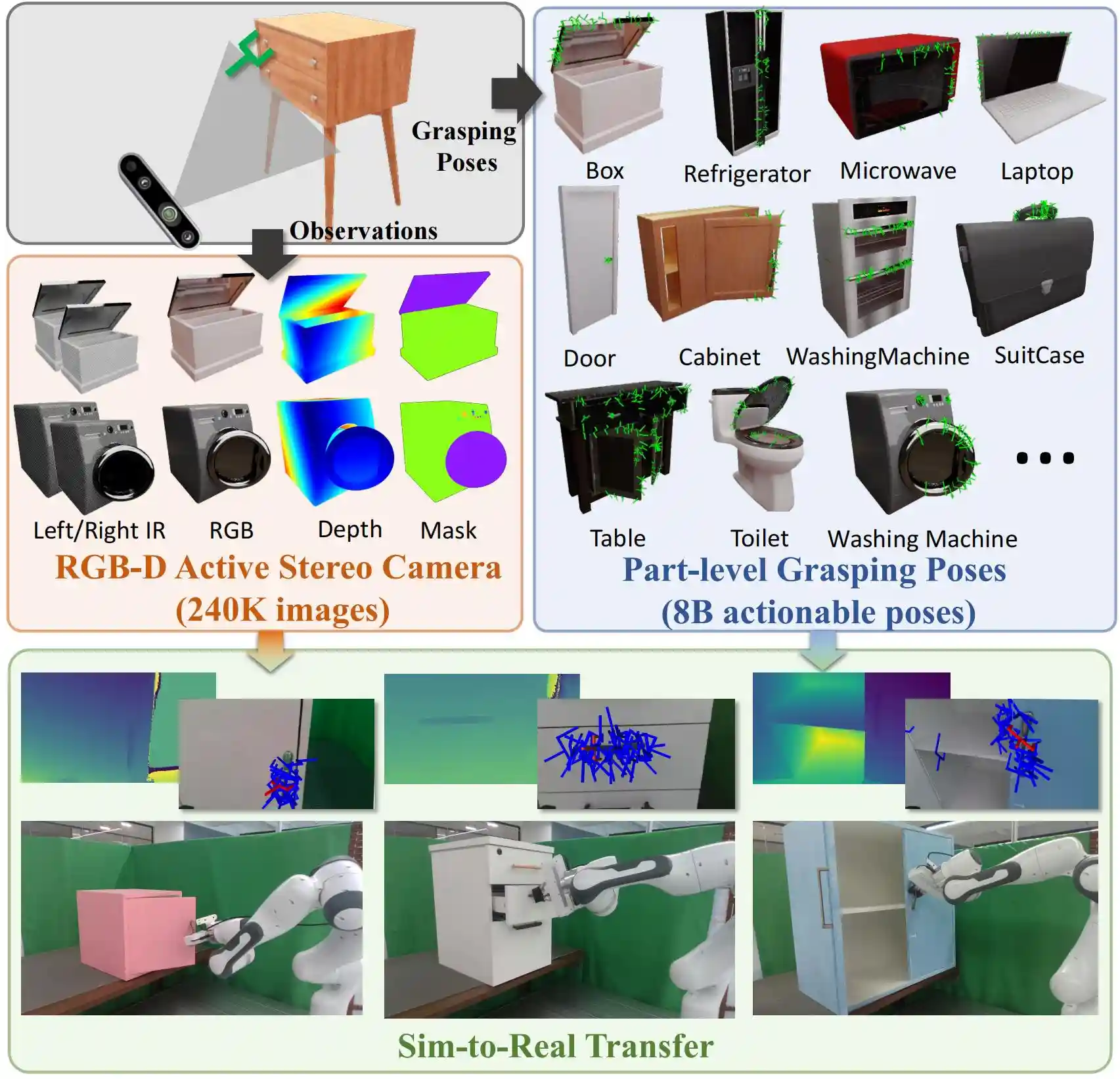
We introduce a large-scale part-centric dataset for material-agnostic articulated object manipulation. It encompasses 19 common household articulated categories, totaling 918 object instances, 240K photo-realistic rendering images, and 8B scene-level actionable interaction poses. GAPartManip enables robust zero-shot sim-to-real transfer for accomplishing articulated object manipulation tasks.
Framework
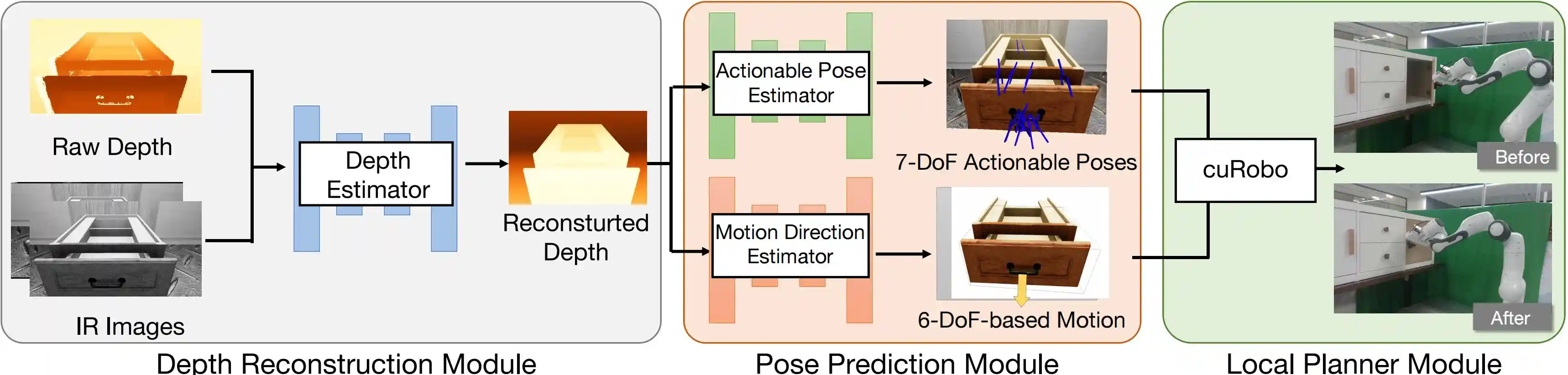
Given IR images and raw depth map, the depth reconstruction module first performs depth recovery. Subsequently, the pose prediction module generates a 7-DoF actionable pose and a 6-DoF post-grasping motion for interaction based on the reconstructed depth. Finally, the local planner module carries out the action planning and execution.
Results
Cross-Category Depth Estimation

Qualitative Results for Depth Estimation in the Real World. Our refined depth maps are cleaner and more accurate than the ones from the baseline, indicating that our depth reconstruction module is more robust for transparent and translucent lids and small handles. Zoom in to better observe small parts like handles and knobs.
Cross-Category Interaction Pose Prediction

Qualitative Comparison of Actionable Pose Prediction in Simulation.
Part-aware Articulaed Object Manipulation

Qualitative Results For Real-world Manipulation. The actionable poses with top scores are displayed, with the red gripper representing the top-1 pose.
BibTeX
@article{cui2024gapartmanip,
title={GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object Manipulation},
author={Cui, Wenbo and Zhao, Chengyang and Wei, Songlin and Zhang, Jiazhao and Geng, Haoran and Chen, Yaran and Li, Haoran and Wang, He},
journal={arXiv preprint arXiv:2411.18276},
year={2024}
}