1Peking University
2GalBot
3USTC
4BAAI
5University of Adelaide
6Zhejiang University
7Differential Robotics
*Joint First Author †Equal Advising
NavFoM is a cross-embodiment and cross-task navigation model trained on 8 million samples encompassing quadrupeds, drones, wheeled robots, and vehicles, spanning tasks including vision-and-language navigation, object searching, target tracking, and autonomous driving.
Summary Video
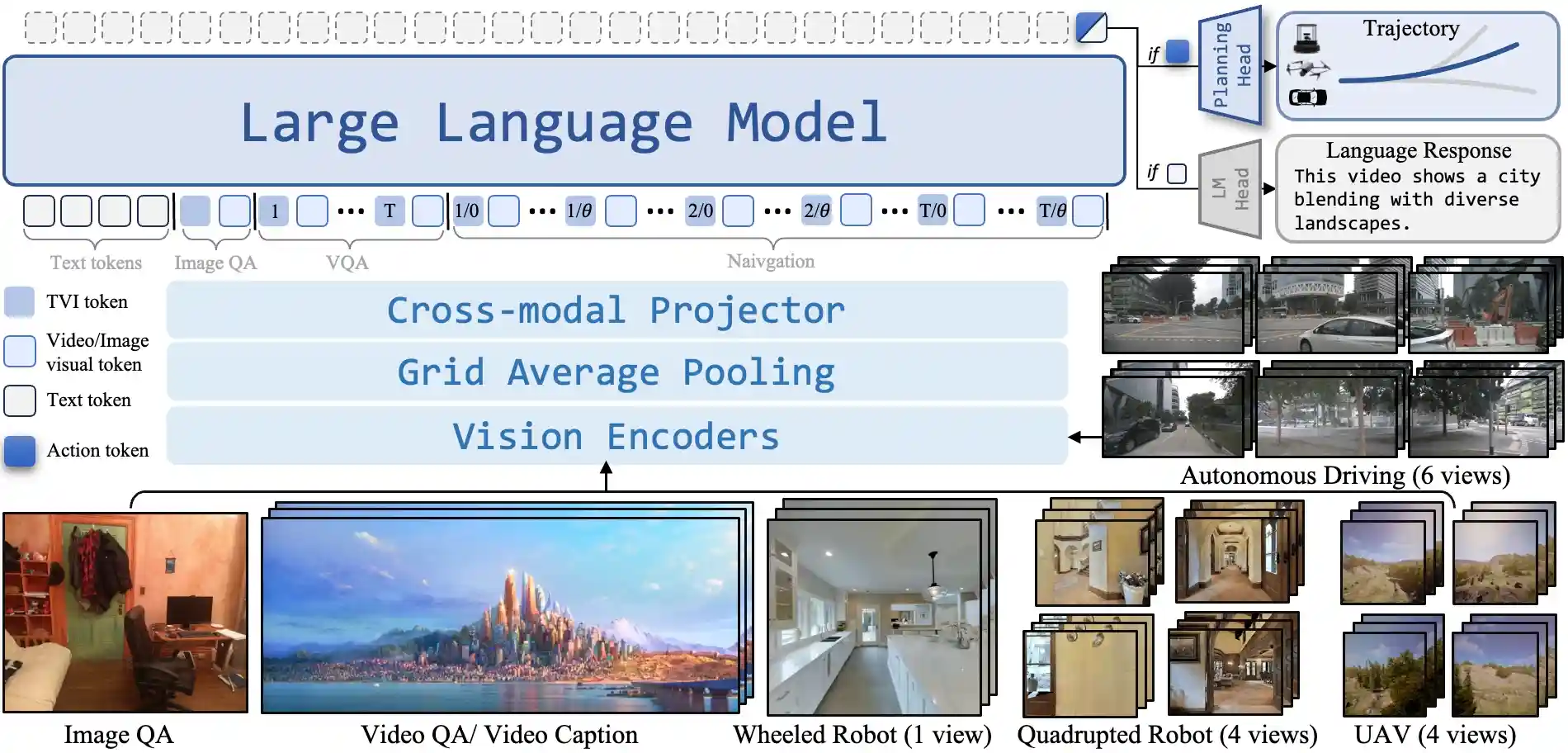
NavFoM Pipeline
Our method provides a unified framework for handling multiple tasks, including Image QA, Video QA, and Navigation. We organize text tokens and visual tokens using temporal-viewpoint indicator tokens. For question answering, our model employs a conventional language modeling head in an autoregressive manner, while for navigation, it uses a planning head to directly predict trajectories.
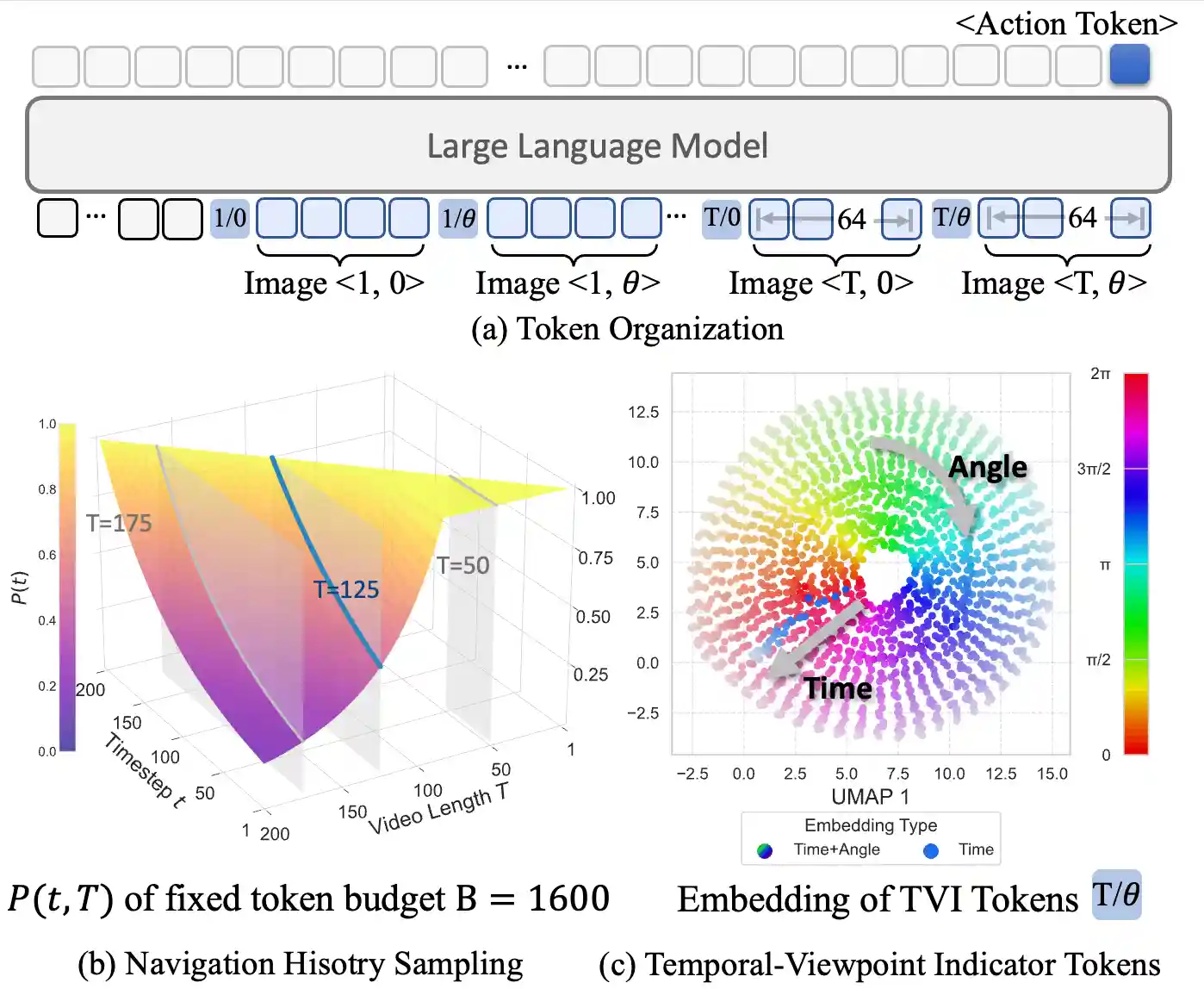
NavFoM Forwarding for Navigation Tasks
For navigation, (a) our approach utilizes both coarse-grained and fine-grained visual tokens. (b) The navigation history is efficiently sampled under a fixed token budget using our Budget-Aware Temporal Sampling (BATS) method. (c) To distinguish historical information from different timesteps and viewpoints, we employ Temporal-Viewpoint Indicator (TVI) tokens, which encode both temporal and angular information.
Standard Test Cases(VLN)
Standard Test Cases(Tracking)
Standard Test Cases(ObjNav)
VLN-CE RxR (Four Views)
VLN-CE RxR (Single Front View)
Tracking EVT-Bench Distracted Target (Four Views)
ObjNav HM3D-OVON (Four Views)
VLN OpenUAV (Four Views)
Autonomus Driving nuScenes (Six Views)
Autonomus Driving openScenes (Eight Views)
Real-world Deployment System
we deploy our model on a remote server equipped with a GeForce RTX 5090 GPU and use the Internet for communication between the server and the client (which includes the controller and embodiments). Given a user instruction, the robots compress their current observations and transmit them to the server. The server then processes both the observations and the instruction to output a trajectory. This trajectory is subsequently processed by the local planner of each individual robot, which sends appropriate commands (e.g., velocity or joint controls) to drive the robot.
Acknowleagemnt
We sincerely thank Jianmin Wang and Wenhao Li for their support with the hardware setup. We also thank Chen Gao, Zhiyong Wang, Zhichao Hang, and Donglin Yang for their support with the experiments.
BibTeX
@article{zhang2025embodied,
title={Embodied navigation foundation model},
author={Zhang, Jiazhao and Li, Anqi and Qi, Yunpeng and Li, Minghan and Liu, Jiahang and Wang, Shaoan and Liu, Haoran and Zhou, Gengze and Wu, Yuze and Li, Xingxing and others},
journal={arXiv preprint arXiv:2509.12129},
year={2025}
}