Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
Yunpeng
Qi3, 4*,
Jiazhao Zhang1, 2*,
Minghan Li2,
Shaoan Wang1,
Kui
Wu5,
Hanjing Ye6,
Hong
Zhang6,
Zhibo Chen3,
Fangwei Zhong7,
Zhizheng
Zhang2, 4†,
He Wang1, 2, 4†
1Peking University
2GalBot
3USTC
4BAAI
5Beihang University
6SUSTech
7Beijing Normal University
*Equal Contribution †Equal Advising

TrackVLA++ is a novel Vision-Language-Action model that incorporates spatial reasoning and target identification memory, enabling superior performance in both long-horizon and highly crowded tracking scenarios.
Summary Video
Abstract
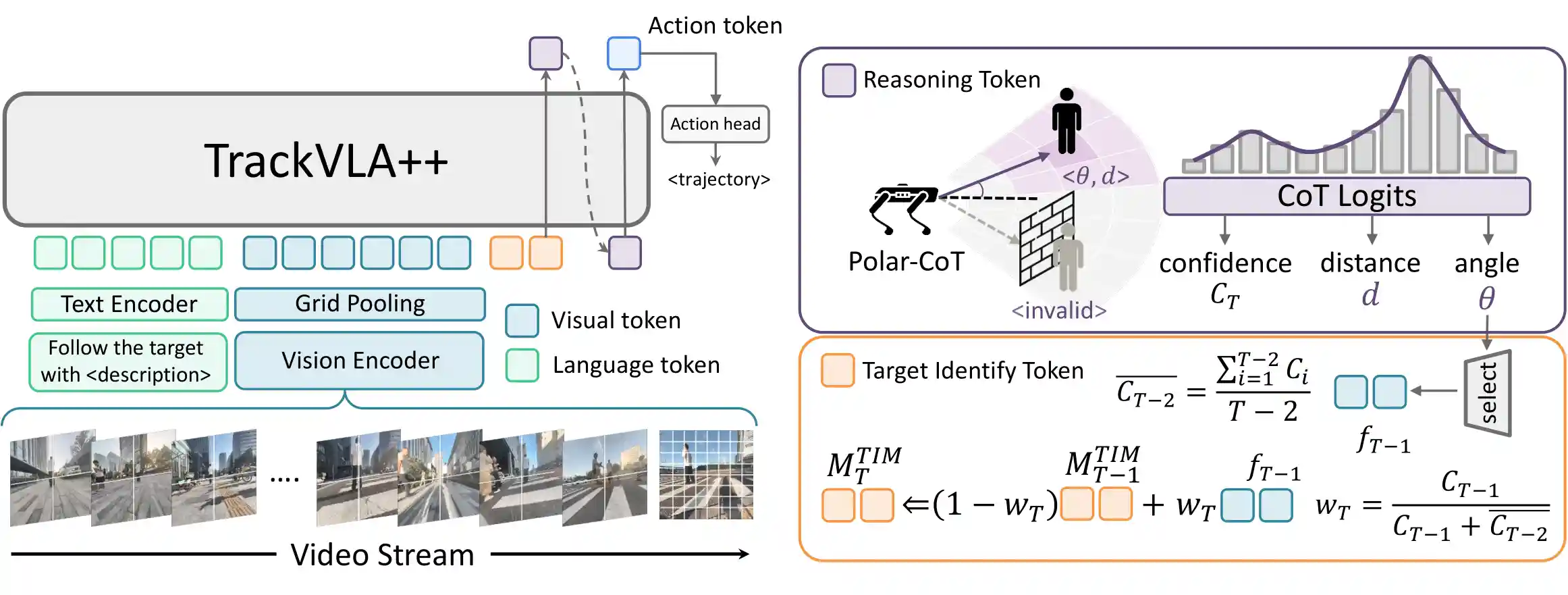
Embodied Visual Tracking (EVT) is a fundamental ability that underpins practical applications, such as companion robots, guidance robots and service assistants, where continuously following moving targets is essential. Recent advances have enabled language-guided tracking in complex and unstructured scenes. However, existing approaches lack explicit spatial reasoning and effective temporal memory, causing failures under severe occlusions or in the presence of similar-looking distractors. To address these challenges, we present TrackVLA++, a novel Vision-Language-Action (VLA) model that enhances embodied visual tracking with two key modules: a spatial reasoning mechanism and a Target Identification Memory (TIM). The reasoning module introduces a Chain-of-Thought paradigm, termed Polar-CoT, which infers the target's relative position and encodes it as a compact polar-coordinate token for action prediction. Guided by these spatial priors, the TIM employs a gated update strategy to preserve long-horizon target memory, ensuring spatiotemporal consistency and mitigating target loss during extended occlusions. Extensive experiments show that TrackVLA++ achieves state-of-the-art performance on public benchmarks across both egocentric and multi-camera settings. On the challenging EVT-Bench DT split, TrackVLA++ surpasses the previous leading approach by 5.1% and 12% respectively. Furthermore, TrackVLA++ exhibits strong zero-shot generalization, enabling robust real-world tracking in dynamic and occluded scenarios.
TrackVLA++ Pipeline
Given a video stream and a language instruction, TrackVLA++ predicts a tracking trajectory by utilizing Polar-CoT reasoning to infer the target's position and continuously updating the Target Identification Memory with CoT-based predictions for long-horizon tracking.
Long Horizon Tracking
TrackVLA++ achieves sustained, long-horizon tracking in complex urban environments, maintaining continuity for over 30 minutes along multi-kilometer trajectories. It remains robust to heavy distractors, multiple barriers, and pronounced illumination changes, demonstrating stable performance in diverse and dynamic settings.
Unstructured Scene Tracking:
TrackVLA++ maintains target identity across complex, unstructured environments, including narrow crosswalks, barrier-dense areas, and wooded scenes; it handles large heading changes, traverses tight corridors into buildings, and continues through constrained spaces such as elevators.
Crowded Scene Tracking
TrackVLA++ exhibits robust performance in crowded scenes with severe occlusions and target disappearance, demonstrating strong spatiotemporal reasoning, consistent re-identification, and long-term memory. It is robust to dynamic distractors common in urban walkways—such as pedestrian flows, crosswalk traffic, and heterogeneous motions—sustaining stable tracking on sidewalks, crosswalks, and related urban settings.
Recognition Ability
TrackVLA++ leverages multi-camera inputs to recognize targets under off-axis views (i.e., non-frontal, oblique perspectives) and reorient toward the target, demonstrating strong spatial understanding and cross-view reasoning capability.
Cross Domain Generalization
TrackVLA++ exhibits cross-domain generalization, enabling robust tracking across diverse scene styles, viewpoints, and camera parameters, while also generalizing beyond human subjects to a broad spectrum of objects, all without additional adaptation.