Universal 3D Object Understanding for Embodied Interaction
S
h
a
p
e
L
L
M
Universal 3D Object Understanding for Embodied Interaction
ECCV 2024
Pipeline
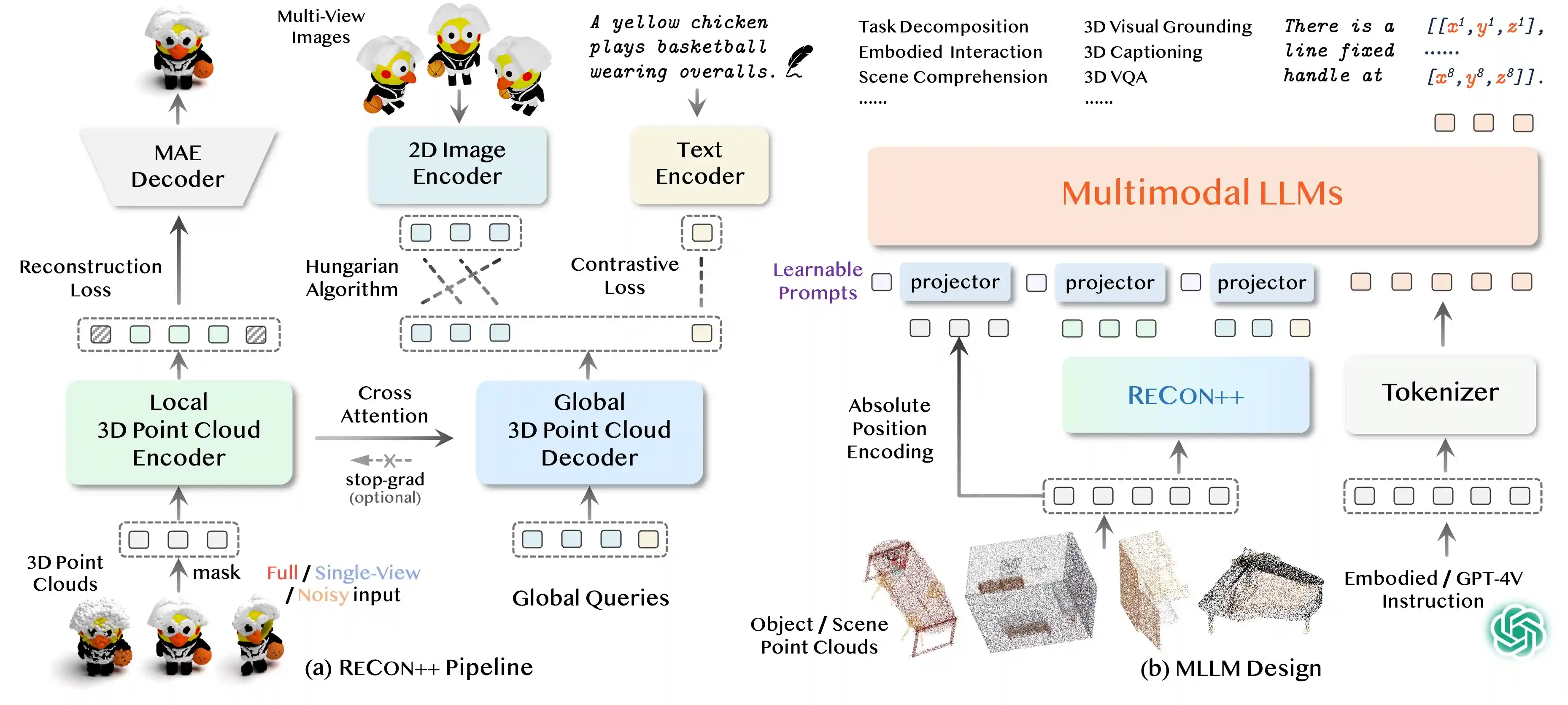
Highlights
- ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction.
- ShapeLLM supports single-view colored point cloud input, which can be effortlessly obtained from RGBD cameras.
- We introduce a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants including single-view, noise jitter, etc.
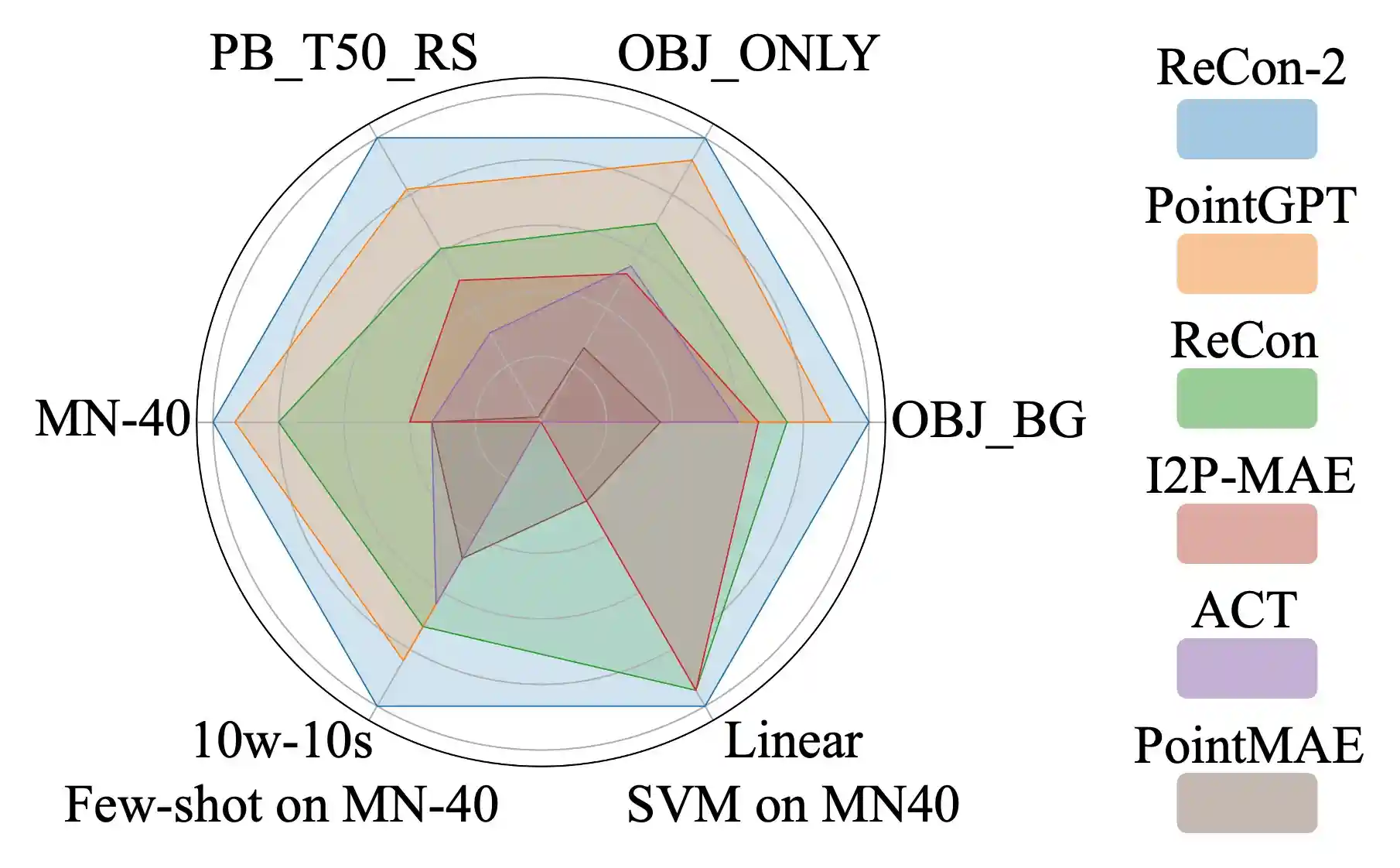
- We extend the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks.
Motivation
What makes better 3D representations that bridge language models and interaction-oriented 3D object understanding?
- 3D Point Clouds as Inputs. Compared to 2D images, 3D point clouds provide a more accurate representation of the physical environment, encapsulating sparse yet highly precise geometric data. Moreover, 3D point clouds are crucial in facilitating embodied interactions necessitating accurate 3D structures like 6-DoF object pose estimation.
- Selective Multi-View Distillation. Interacting with objects typically necessitates an intricate 3D understanding that involves knowledge at various levels and granularities. For instance, a whole-part high-level semantic understanding is needed for interactions like opening a large cabinet, while detailed, high-resolution (i.e., low-level) semantics are crucial for smaller objects like manipulating a drawer handle.
- 3D Visual Instruction Tuning. Instruction tuning has been proven effective in improving LLMs' alignment capability. To realize various 3D understanding tasks with a universal language interface, ShapeLLM is trained through instruction-following tuning on constructed language-output data. We construct ~45K instruction-following data using GPT-4V on the processed Objaverse dataset and 30K embodied part understanding data from GAPartNet for supervised fine-tuning.
Gallery
*Conversations generated with instructions provided by our users

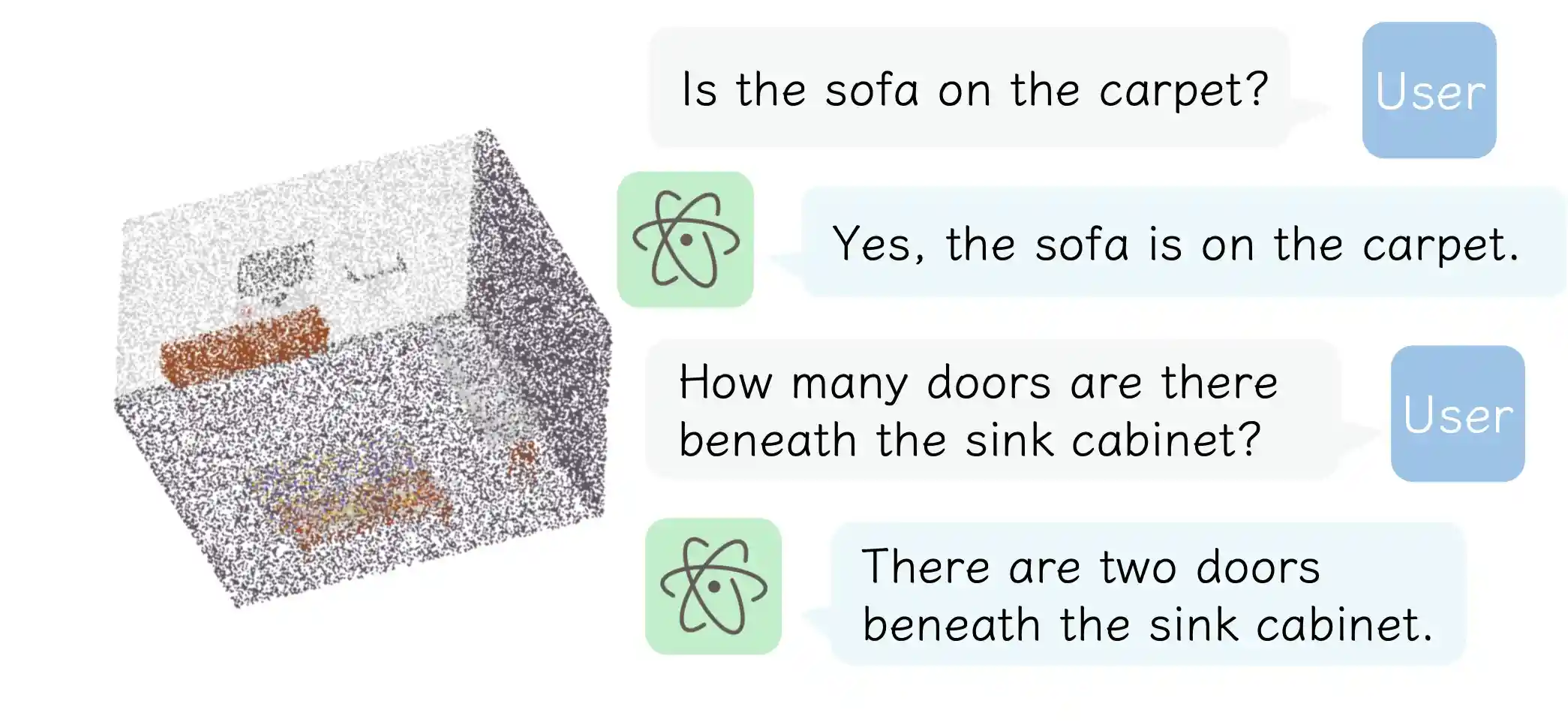
Single-View Point Cloud Understanding

Planning & Task Decomposition
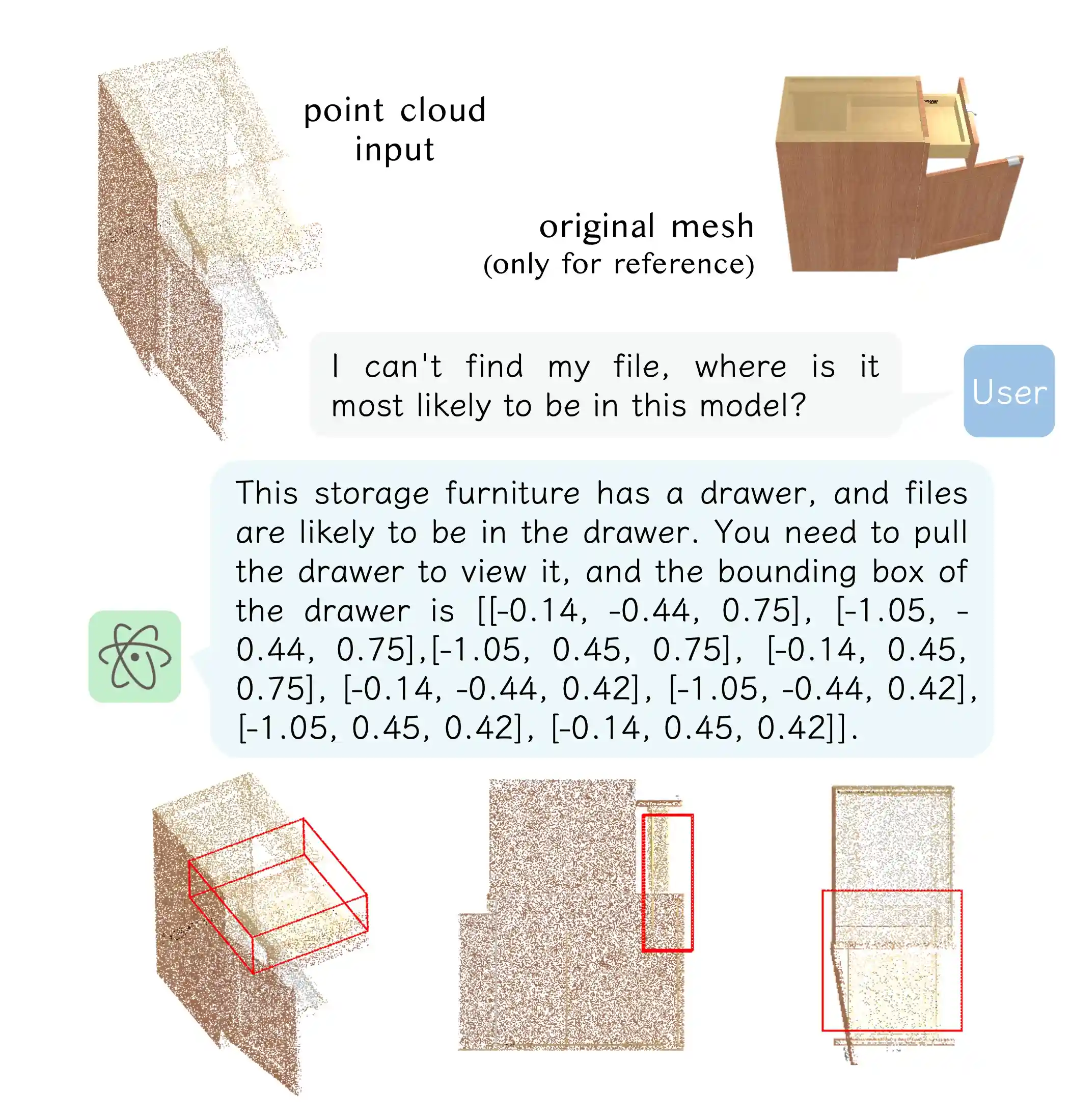
Embodied Visual Grounding
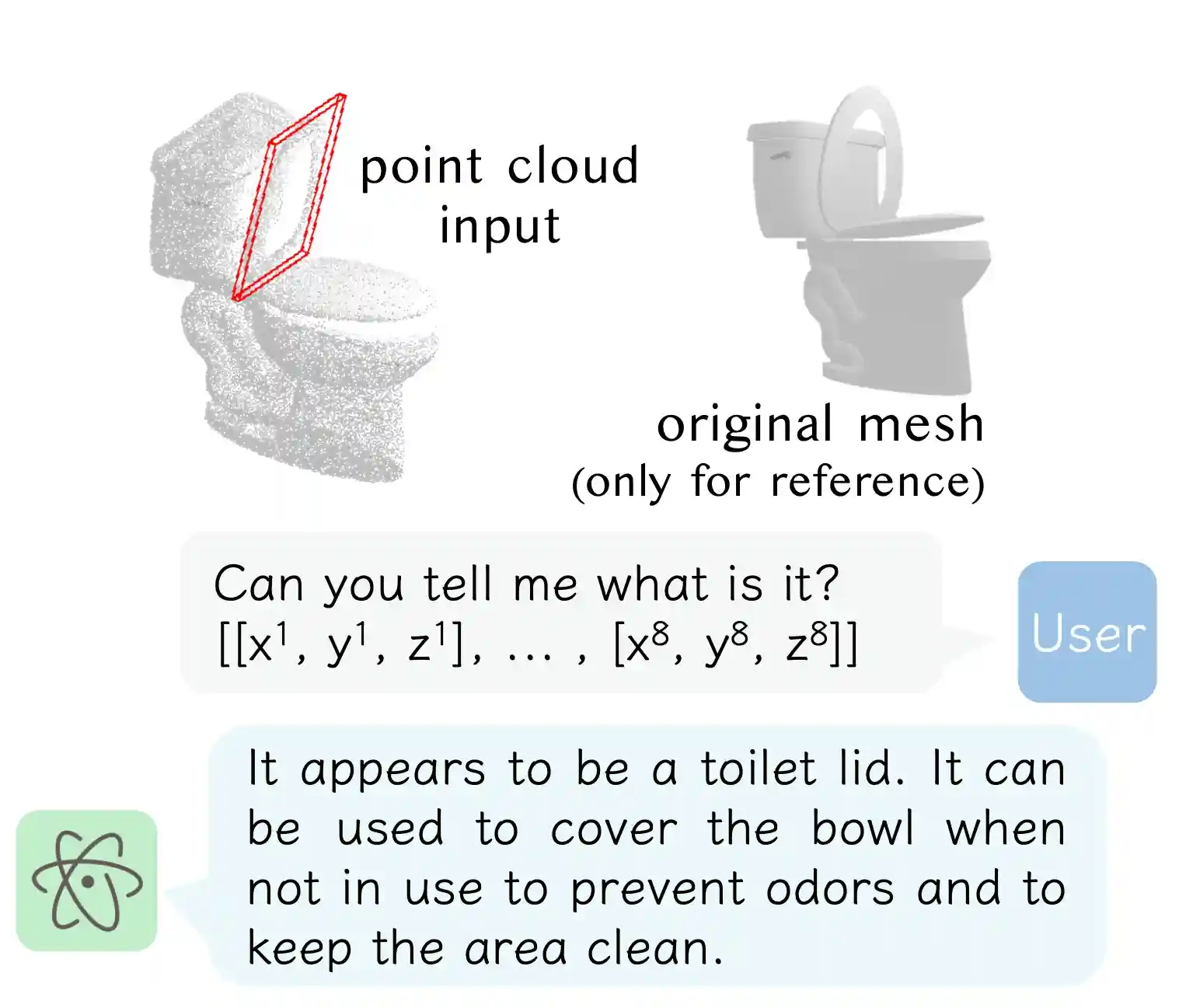
Precise Referring Dialogue


Vision Question Answering
ReCon++
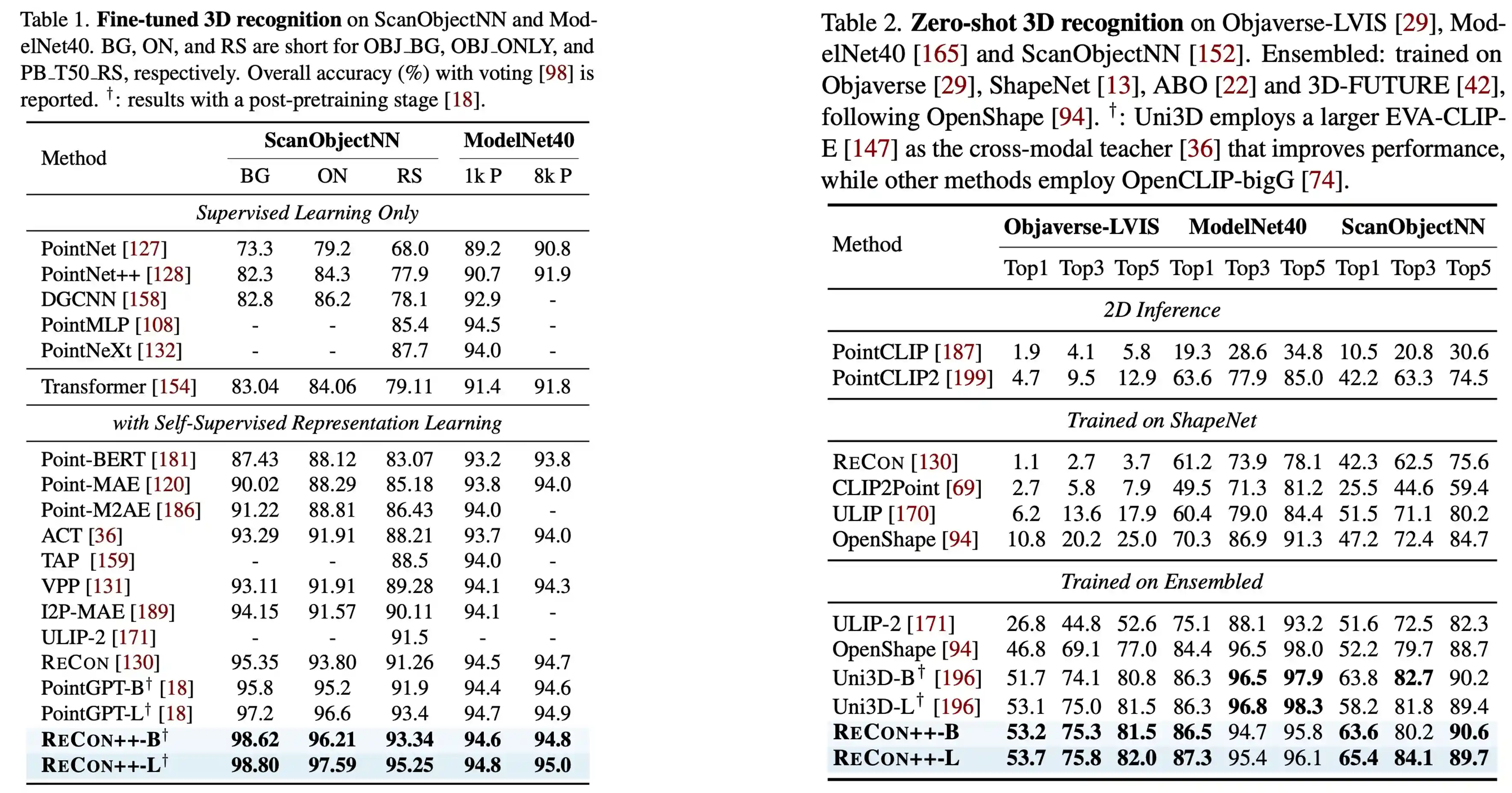
ReCon++ is a powerful point encoder architecture that achieves state-of-the-art performance across a range of representation learning tasks: Fine-tuned 3D recognition, Few-shot 3D recognition, and Zero-shot 3D recognition.
3D MM-Vet
3D MM-Vet is the first 3D multimodal comprehension evaluation benchmark, which includes five different levels of tasks.

Citation
@article{qi2024shapellm,
author = {Qi, Zekun and Dong, Runpei and Zhang, Shaochen and Geng, Haoran and Han, Chunrui and Ge, Zheng and Yi, Li and Ma, Kaisheng},
title = {ShapeLLM: Universal 3D Object Understanding for Embodied Interaction},
journal = {arXiv preprint arXiv:2402.17766},
year = {2024},
}