
aadityaura@gmail.com
Hi there, I’m Aaditya (Ankit), a Senior Research Engineer specializing in NLP, Deep learning, and Machine learning. My research aims to develop machine learning methods in the Healthcare & Life Sciences domain.
I currently work at Saama, conducting research to accelerate clinical trials and reduce drug development timelines. My research interests involve Representation Learning on Graphs, Generative language models, Federated learning, XAI and their applications in Healthcare data.
I’ve been honored to contribute meaningful research and datasets that have been adopted by leading companies like Facebook AI (Galactica), Google AI (Med-PaLM, Med-PaLM-2), Microsoft, and OpenAI (GPT-4) to further responsible advancements in AI.
Recently, I developed OpenBioLLM-70B & 8B, the most capable openly available Medical-domain LLMs to date. These models have demonstrated impressive performance, outperforming industry giants like GPT-4, Gemini, Meditron-70B, Med-PaLM-1, and Med-PaLM-2 in the biomedical domain. It’s been incredibly rewarding to see OpenBioLLM-70B deliver SOTA performance and OpenBioLLM-8B surpass GPT-3.5, Gemini, and Meditron-70B. Notably, OpenBioLLM is the first medical model to trend among the world’s top 10 LLM models on the Hugging Face front page and the first Indian LLM to appear on the trending page.
{kind=link}
I had the honor of spearheading a collaboration with the Hugging Face team and Prof. Pasquale Minervini to develop the open-medical LLM leaderboard, which serves as the standard evaluation benchmark for medical domain LLMs. Additionally, I had the privilege of presenting the first medical domain hallucination benchmark, suggesting methods to identify and mitigate hallucinations in the medical domain.
Currently, my focus is on Multimodal Medical & Genomic LLMs and robust evaluation of LLMs in the medical domain.
I have a deep appreciation for open-source work and contribute to projects including Tensorflow, Pytorch Geometric and HuggingFace. In December 2022, I noticed structured output issues in large language models and developed Promptify, which received encouraging feedback on GitHub. During COVID-19 pandemic in March 2020, I initiated a project to capture cough and breath sounds via phone to classify COVID-19 coughs using deep learning, with the aim of aiding doctors in rapid pre-screening of patients.
If you are still reading, here is more about me: Apart from my research life, I’m drawn to activities like Boxing, Jiu-Jitsu and Chess. I enjoy spending time in nature, Observation, and Philosophy. I have realized to some extent that everything is connected; there is neither good nor bad; there is neither positive nor negative. I often displace myself away from social noise, take a seat, and try to see, observe, rather than just looking at it. In the process, I naturally learn.
Note: I am looking for a funded PhD opportunity, especially if it fits my Responsible Generative AI, Multimodal LLMs, Geometric Deep Learning, and Healthcare AI skillset.
news
| Oct 10, 2023 | Our work on Hallucination Test for Large Language Models was accepted at EMNLP(Conll) 2023. |
|---|---|
| Jul 29, 2023 | We’re thrilled to announce the release of Promptify 2.0 🎉 - to deal with the structured output issue in LLMs. Promptify is trending on GitHub! ✨ |
| Nov 23, 2022 | Our work on Distribution Shift on Question Answering Models was accepted at NeurIPS (Robustness in Sequence Modeling) 2022. |
| Oct 1, 2022 | Our work on Federated Learning in Healthcare domain was accepted at ACM 2022. |
| Apr 7, 2022 | Our work on Open-domain Question Answering in Medical domain was accepted at Conference on Health, Inference, and Learning (CHIL) 2022. |
| Dec 11, 2020 | We worked on ML based discrepancy identification and data reconciliation tool Smart Data Query & Smart Auto Mapper to accelerate COVID vaccine trial. Full details can be found at Pfizer page |
selected publications
-
MAGNET: Multi-Label Text Classification using Attention-based Graph Neural Network
Proceedings of the 12th International Conference on Agents and Artificial Intelligence, 2020
In Multi-Label Text Classification (MLTC), one sample can belong to more than one class. It is observed that most MLTC tasks, there are dependencies or correlations among labels. Existing methods tend to ignore the relationship among labels. In this paper, a graph attention network-based model is proposed to capture the attentive dependency structure among the labels. The graph attention network uses a feature matrix and a correlation matrix to capture and explore the crucial dependencies between the labels and generate classifiers for the task. The generated classifiers are applied to sentence feature vectors obtained from the text feature extraction network (BiLSTM) to enable end-to-end training. Attention allows the system to assign different weights to neighbor nodes per label, thus allowing it to learn the dependencies among labels implicitly. The results of the proposed model are validated on five real-world MLTC datasets. The proposed model achieves similar or better performance compared to the previous state-of-the-art models.
-
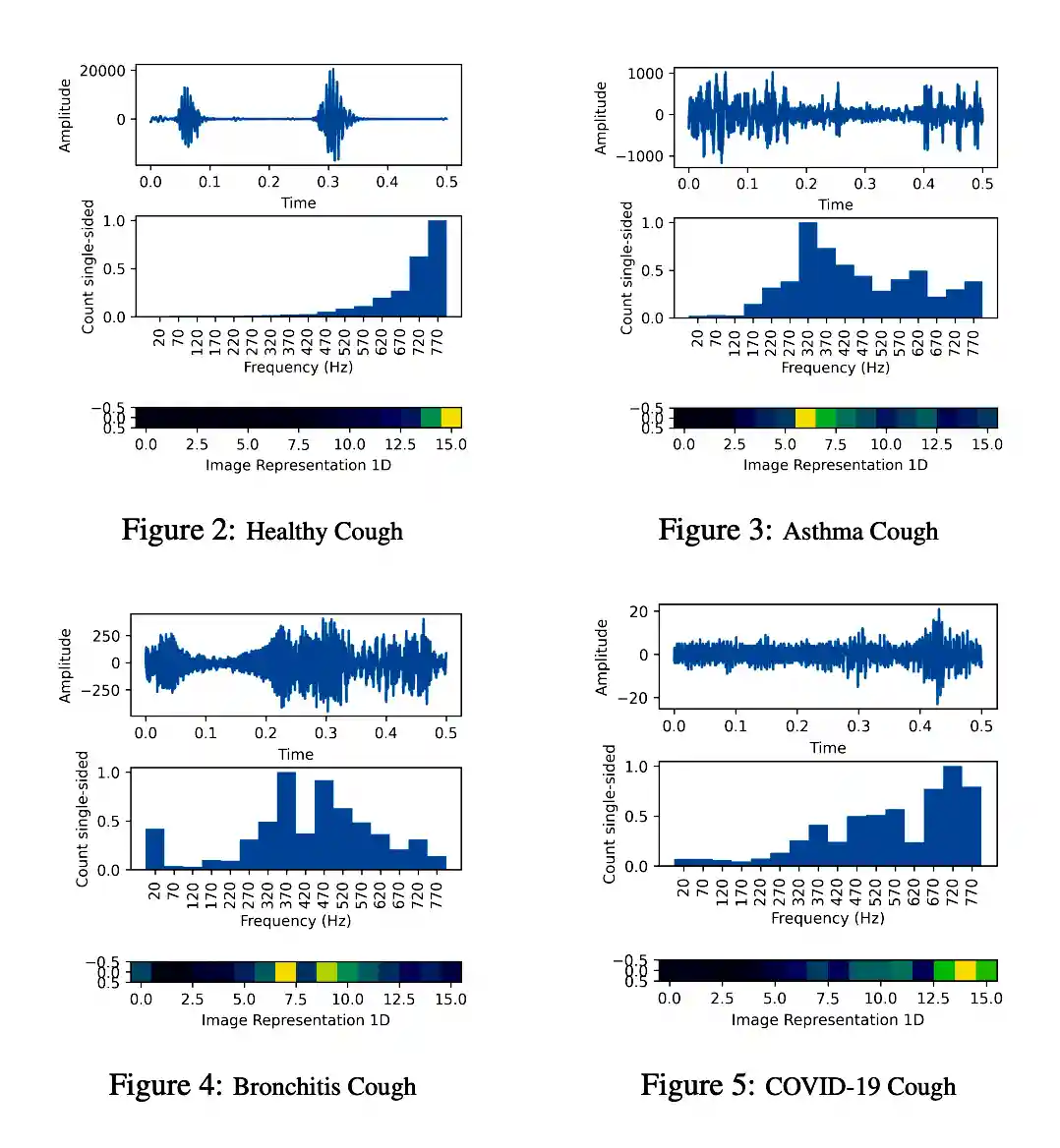
Pay Attention to the cough: Early Diagnosis of COVID-19 using Interpretable Symptoms Embeddings with Cough Sound Signal Processing
Proceedings of the 36th Annual ACM Symposium on Applied Computing, 2021
COVID-19 (coronavirus disease 2019) pandemic caused by SARS-CoV-2 has led to a treacherous and devastating catastrophe for humanity. At the time of writing, no specific antivirus drugs or vaccines are recommended to control infection transmission and spread. The current diagnosis of COVID-19 is done by Reverse-Transcription Polymer Chain Reaction (RT-PCR) testing. However, this method is expensive, time-consuming, and not easily available in straitened regions. An interpretable and COVID-19 diagnosis AI framework is devised and developed based on the cough sounds features and symptoms metadata to overcome these limitations. The proposed framework’s performance was evaluated using a medical dataset containing Symptoms and Demographic data of 30000 audio segments, 328 cough sounds from 150 patients with four cough classes ( COVID-19, Asthma, Bronchitis, and Healthy). Experiments’ results show that the model captures the better and robust feature embedding to distinguish between COVID-19 patient coughs and several types of non-COVID-19 coughs with higher specificity and accuracy of 95.04 ± 0.18% and 96.83± 0.18% respectively, all the while maintaining interpretability.
-
NeurIPS
CLIFT: Analysing Natural Distribution Shift on Question Answering Models in Clinical Domain
Ankit Pal
NeurIPS-2022: Robustness in Sequence Modeling
This paper introduces a new testbed CLIFT (Clinical Shift) for the clinical domain Question Answering task. The testbed includes 7.5k high-quality questionanswering samples to provide a diverse and reliable benchmark. We performed a comprehensive experimental study and evaluated several QA deep-learning models under the proposed testbed. Despite impressive results on the original test set, the performance degrades when applied to new test sets, which shows the distribution shift. Our findings emphasize the need for and the potential for increasing the robustness of clinical domain models under distributional shifts. The testbed offers one way to track progress in that direction. It also highlights the necessity of adopting evaluation metrics that consider robustness to natural distribution shifts. We plan to expand the corpus by adding more samples and model results. The full paper and the updated benchmark are available at openlifescience-ai.github.io/clift
-

MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering
Proceedings of Machine Learning Research(PMLR), 2022
This paper introduces MedMCQA, a new large-scale, Multiple-Choice Question Answering (MCQA) dataset designed to address real-world medical entrance exam questions. More than 194k high-quality AIIMS & NEET PG entrance exam MCQs covering 2.4k healthcare topics and 21 medical subjects are collected with an average token length of 12.77 and high topical diversity. Each sample contains a question, correct answer(s), and other options which requires a deeper language understanding as it tests the 10+ reasoning abilities of a model across a wide range of medical subjects & topics. A detailed explanation of the solution, along with the above information, is provided in this study.
-

Federated learning for healthcare domain - pipeline, applications and challenges
ACM Transactions on Computing for Healthcare, 2022
Federated learning is the process of developing machine learning models over datasets distributed across data centers such as hospitals, clinical research labs, and mobile devices while preventing data leakage. This survey examines previous research and studies on federated learning in the healthcare sector across a range of use cases and applications. Our survey shows what challenges, methods, and applications a practitioner should be aware of in the topic of federated learning. This paper aims to lay out existing research and list the possibilities of federated learning for healthcare industries.
-
EMNLP
DeepParliament: A Legal domain Benchmark & Dataset for Parliament Bills Prediction
Ankit Pal
Empirical Methods in Natural Language Processing(UM-IoS), 2022
This paper introduces DeepParliament, a legal domain Benchmark Dataset that gathers bill documents and metadata and performs various bill status classification tasks. The proposed dataset text covers a broad range of bills from 1986 to the present and contains richer information on parliament bill content. Data collection, detailed statistics and analyses are provided in the paper. Moreover, we experimented with different types of models ranging from RNN to pretrained and reported the results. We are proposing two new benchmarks: Binary and Multi-Class Bill Status classification. Models developed for bill documents and relevant supportive tasks may assist Members of Parliament (MPs), presidents, and other legal practitioners. It will help review or prioritise bills, thus speeding up the billing process, improving the quality of decisions and reducing the time consumption in both houses. Considering that the foundation of the country”s democracy is Parliament and state legislatures, we anticipate that our research will be an essential addition to the Legal NLP community. This work will be the first to present a Parliament bill prediction task. In order to improve the accessibility of legal AI resources and promote reproducibility, we have made our code and dataset publicly accessible at github.com/monk1337/DeepParliament.
-

Med-HALT: Medical Domain Hallucination Test for Large Language Models
Empirical Methods in Natural Language Processing(Conll), 2023
This research paper focuses on the challenges posed by hallucinations in large language models (LLMs), particularly in the context of the medical domain. Hallucination, wherein these models generate plausible yet unverified or incorrect information, can have serious consequences in healthcare applications. We propose a new benchmark and dataset, Med-HALT (Medical Domain Hallucination Test), designed specifically to evaluate and reduce hallucinations. Med-HALT provides a diverse multinational dataset derived from medical examinations across various countries and includes multiple innovative testing modalities. Med-HALT includes two categories of tests reasoning and memory-based hallucination tests, designed to assess LLMs’s problem-solving and information retrieval abilities. Our study evaluated leading LLMs, including Text Davinci, GPT-3.5, LlaMa-2, MPT, and Falcon, revealing significant differences in their performance. The paper provides detailed insights into the dataset, promoting transparency and reproducibility. Through this work, we aim to contribute to the development of safer and more reliable language models in healthcare. Our benchmark can be found at medhalt.github.io