Bolin Lai
|
Bolin Lai Hi! I am a 5th-year PhD student in the Machine Learning Program of Georgia Institute of Technology, advised by Prof. James Rehg and co-advised by Prof. Zsolt Kira. Currently, I'm also a visiting student at CS department of UIUC. Prior to my PhD, I got my Master's degree majoring in ECE and Bachelor's degree majoring in Information Engineering from Shanghai Jiao Tong University. I worked with Prof. Ya Zhang during my master. I interned at Meta GenAI (now Meta Superintelligence Labs) for three times working on research of generative models. My projects span multimodal LLMs, image/video diffusion models, autoregressive architectures and fundamental research on tokenizers. Please check my employment experiences and publications below for details. Email / Google Scholar / Github / LinkedIn / Twitter |

|
I'm looking for a full-time Research Scientist / Applied Scientist / ML Engineer position (available starting Dec. 2025). Please drop me an email if you think I'm a good fit in your team.
Research Interests |
|
My research interests lie in Multimodal Learning, including Multimodal Understanding (e.g., VLMs, MLLMs) and Image/Video Generation (e.g., diffusion, flow matching). My career goal is to build omni multimodal systems that can understand, reason, and generate across text, image, video, and audio -- by integrating LLM planning/reasoning agents and high-fidelity diffusion backends into one autoregressive architecture. I'm always looking for self-motivated graduate/ungraduate students to collaborate with. Don't hesitate to reach out to me if you are interested in my research. |
News |
|
Scroll for more news ↓ |
Employment |
|
Publications
(The Selected tab highlights publications that best represent my expertise)
|
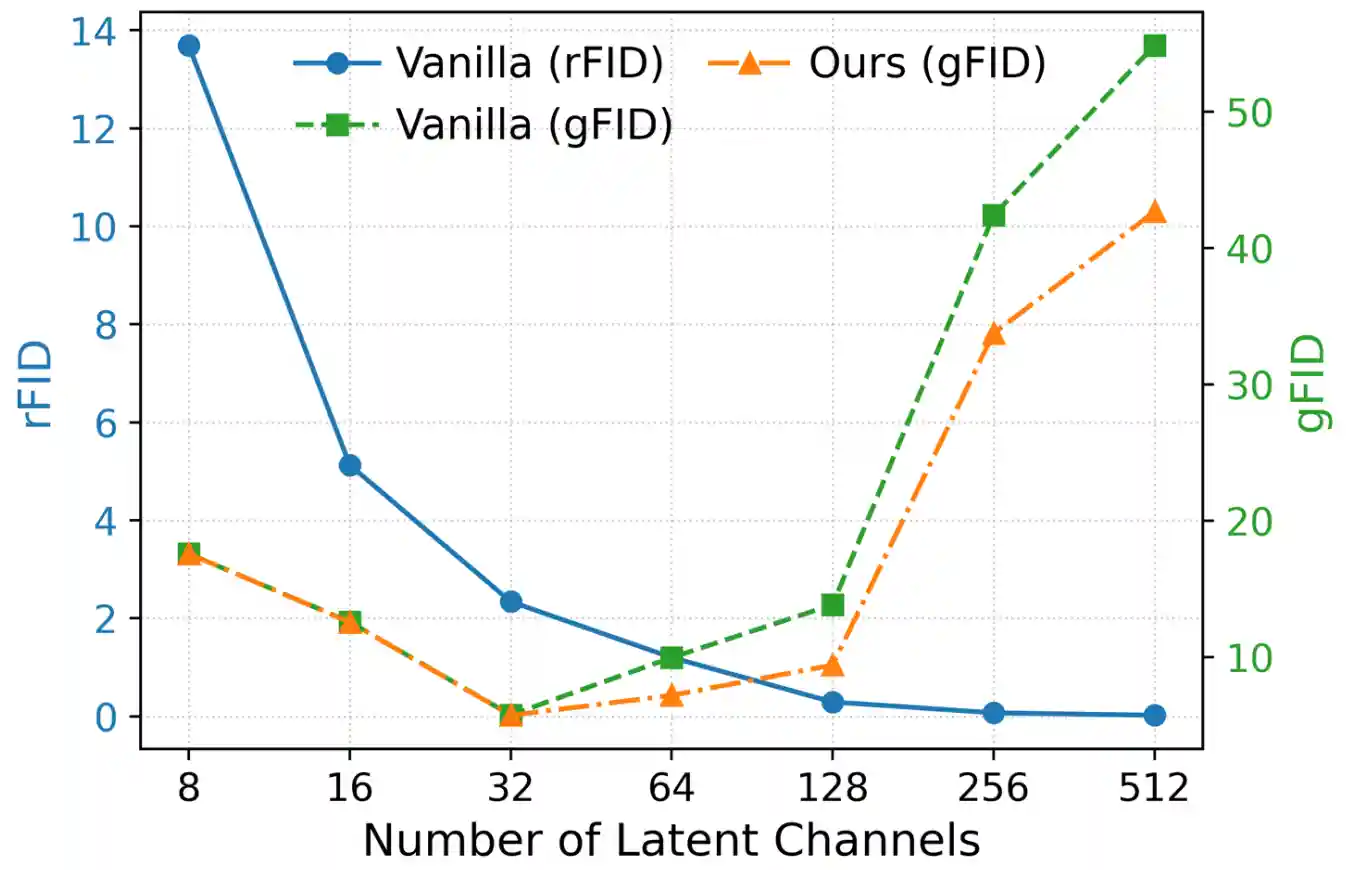
Toward Diffusible High-Dimensional Latent Spaces: A Frequency Perspective
Bolin Lai, Xudong Wang, Saketh Rambhatla, James M. Rehg, Zsolt Kira, Rohit Girdhar, Ishan Misra Under Review, 2025Webpage / Paper |
|
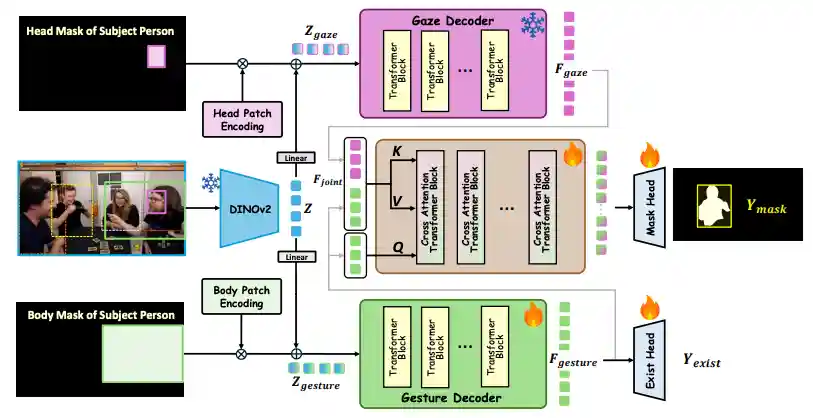
Toward Human Deictic Gesture Target Estimation
Xu Cao, Pranav Virupaksha, Sangmin Lee, Bolin Lai, Wenqi Jia, Jintai Chen, James M. Rehg NeurIPS, 2025Webpage / Paper / Code |

|
Unified Text-Image-to-Video Generation: A Training-Free Approach to Flexible Visual Conditioning
Bolin Lai, Sangmin Lee, Xu Cao, Xiang Li, James M. Rehg Under Review, 2025Webpage / Paper / Code |
|
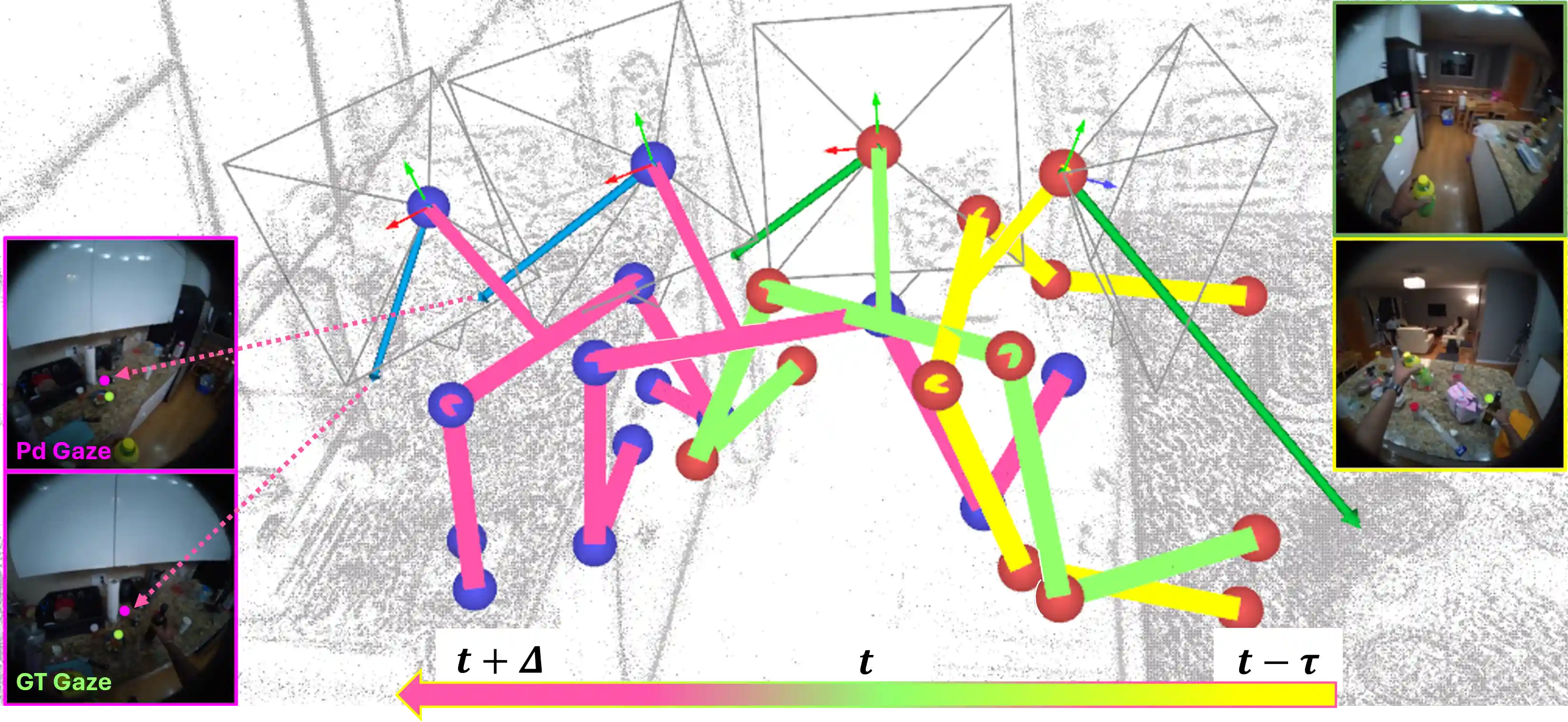
Learning Predictive Visuomotor Coordination
Wenqi Jia, Bolin Lai, Miao Liu, Danfei Xu, James M. Rehg Under Review, 2025Webpage / Paper |
|
Towards Online Multi-Modal Social Interaction Understanding
Xinpeng Li, Shijian Deng, Bolin Lai, Weiguo Pian, James M. Rehg, Yapeng Tian Under Review, 2025Paper / Code |
|
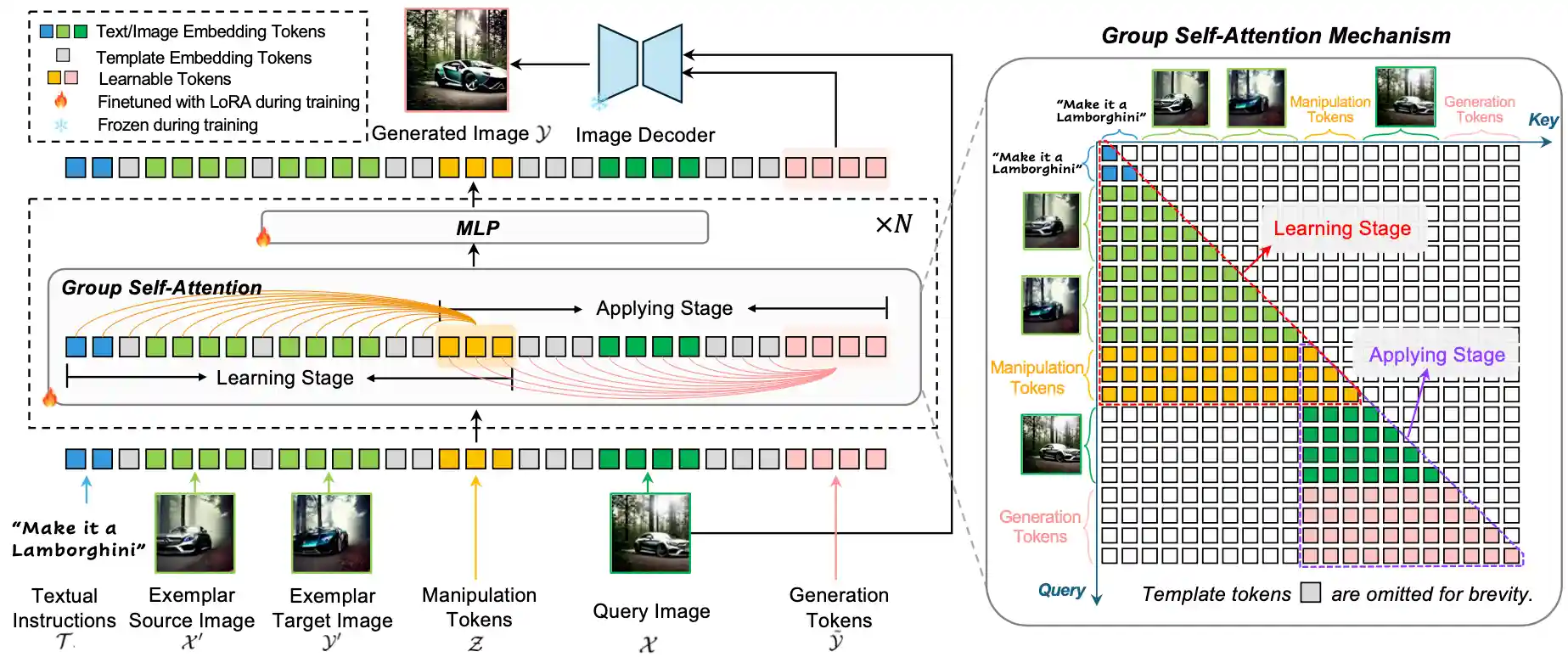
Unleashing In-context Learning of Autoregressive Models for Few-shot Image Manipulation
Bolin Lai, Felix Juefei-Xu, Miao Liu, Xiaoliang Dai, Nikhil Mehta, Chenguang Zhu, Zeyi Huang, James M. Rehg, Sangmin Lee, Ning Zhang, Tong Xiao CVPR, 2025 (Highlight)Webpage / Paper / Code / HuggingFace / Supplementary Video / Poster |
|
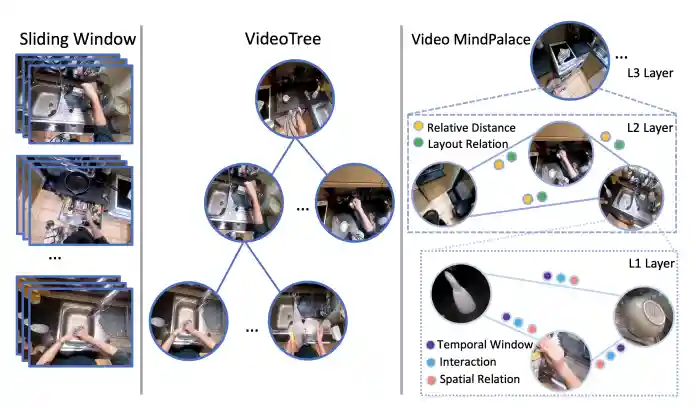
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Zeyi Huang, Yuyang Ji, Xiaofang Wang, Nikhil Mehta, Tong Xiao, Donghyun Lee, Sigmund VanValkenburgh, Shengxin Zha, Bolin Lai, Licheng Yu, Ning Zhang, Yong Jae Lee, Miao Liu CVPR, 2025Webpage / Paper / Code |

|
SocialGesture: Delving into Multi-person Gesture Understanding
Xu Cao, Pranav Virupaksha, Wenqi Jia, Bolin Lai, Fiona Ryan, Sangmin Lee, James M. Rehg CVPR, 2025Webpage / Paper / Dataset |
|
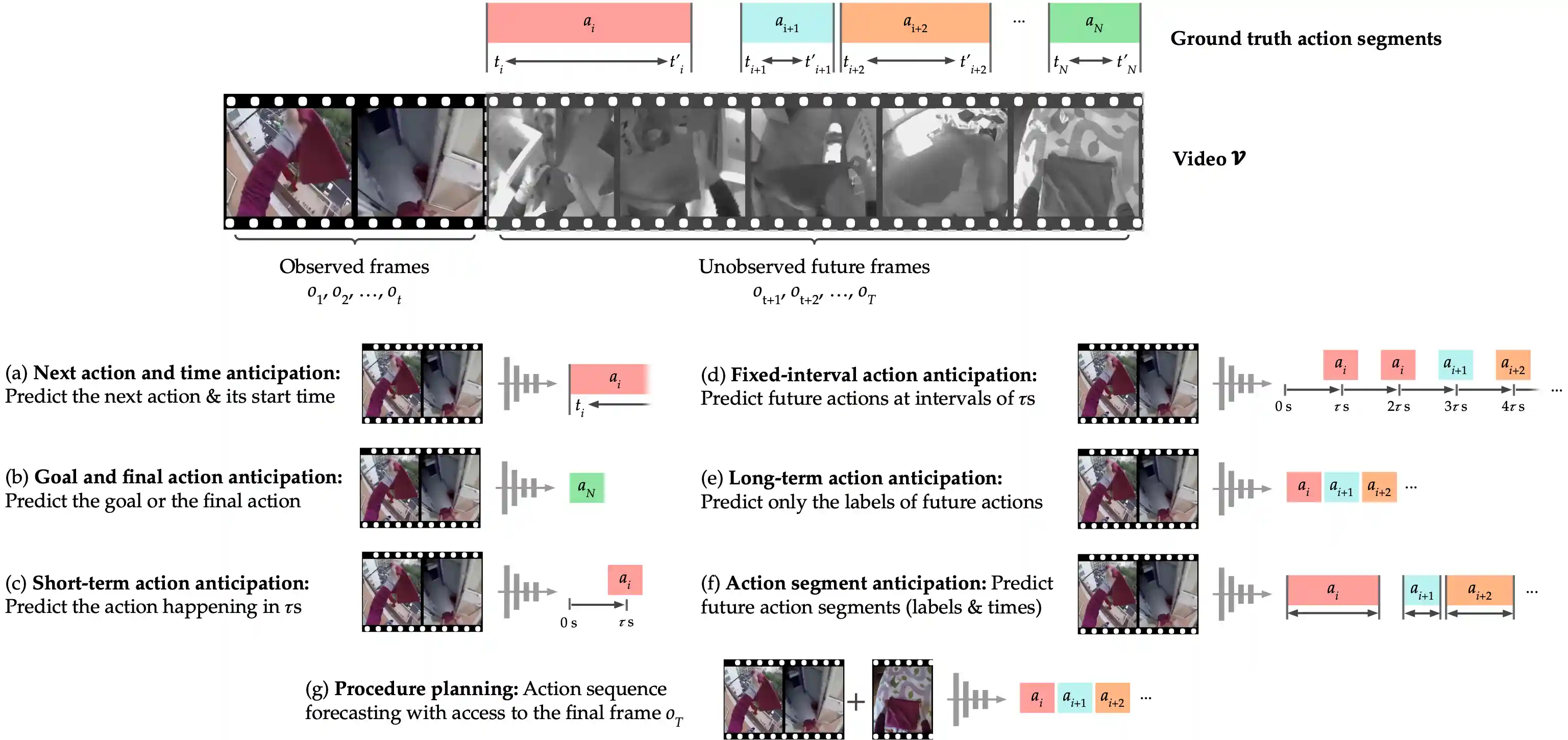
Human Action Anticipation: A Survey
Bolin Lai*, Sam Toyer*, Tushar Nagarajan, Rohit Girdhar, Shengxin Zha, James M. Rehg, Kris Kitani, Kristen Grauman, Ruta Desai, Miao Liu Under Review of IJCV, 2024[Paper] |
|
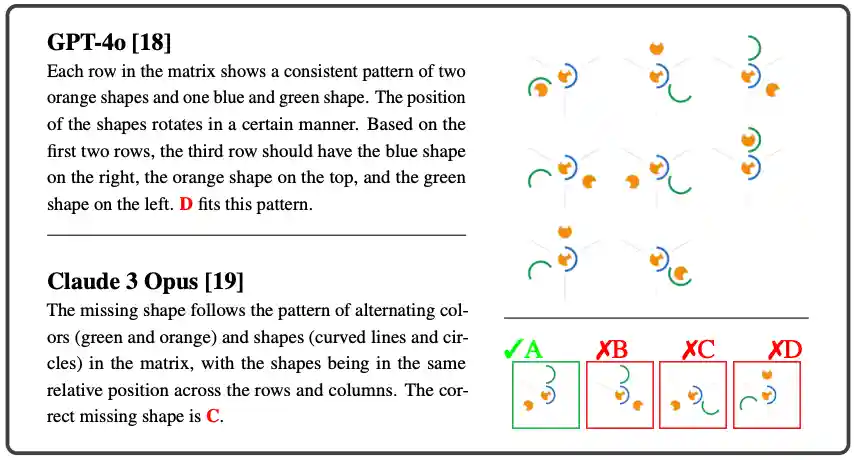
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg COLM, 2025Paper / Data |

|
MM-SPUBENCH: Towards Better Understanding of Spurious Biases in Multimodal LLMs
Wenqian Ye, Guangtao Zheng, Yunsheng Ma, Xu Cao, Bolin Lai, James M. Rehg, Aidong Zhang Under Review, 2024[Paper] |
|
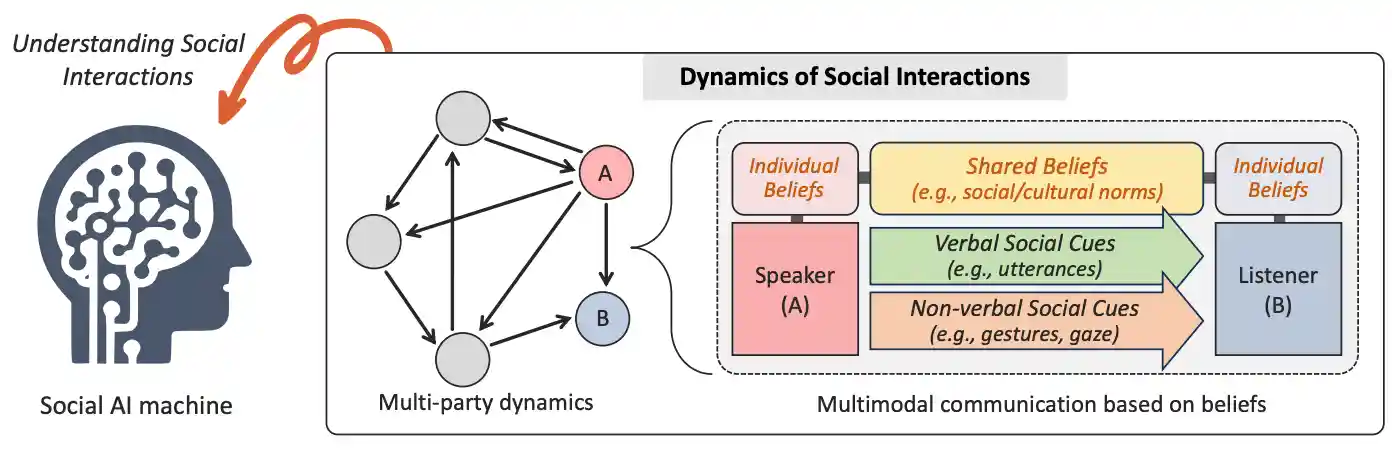
Towards Social AI: A Survey on Understanding Social Interactions
Sangmin Lee, Minzhi Li, Bolin Lai, Wenqi Jia, Fiona Ryan, Xu Cao, Ozgur Kara, Bikram Boote, Weiyan Shi, Diyi Yang, James M. Rehg Under Review of TPAMI, 2024[Paper] |

|
LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning
Bolin Lai, Xiaoliang Dai, Lawrence Chen, Guan Pang, James M. Rehg, Miao Liu ECCV, 2024 (Oral, Best Paper Finalist)EgoVis Distinguished Paper Award Webpage / Paper / Code / Dataset / HuggingFace / Supplementary / Video / Poster / Press: GT News |
|
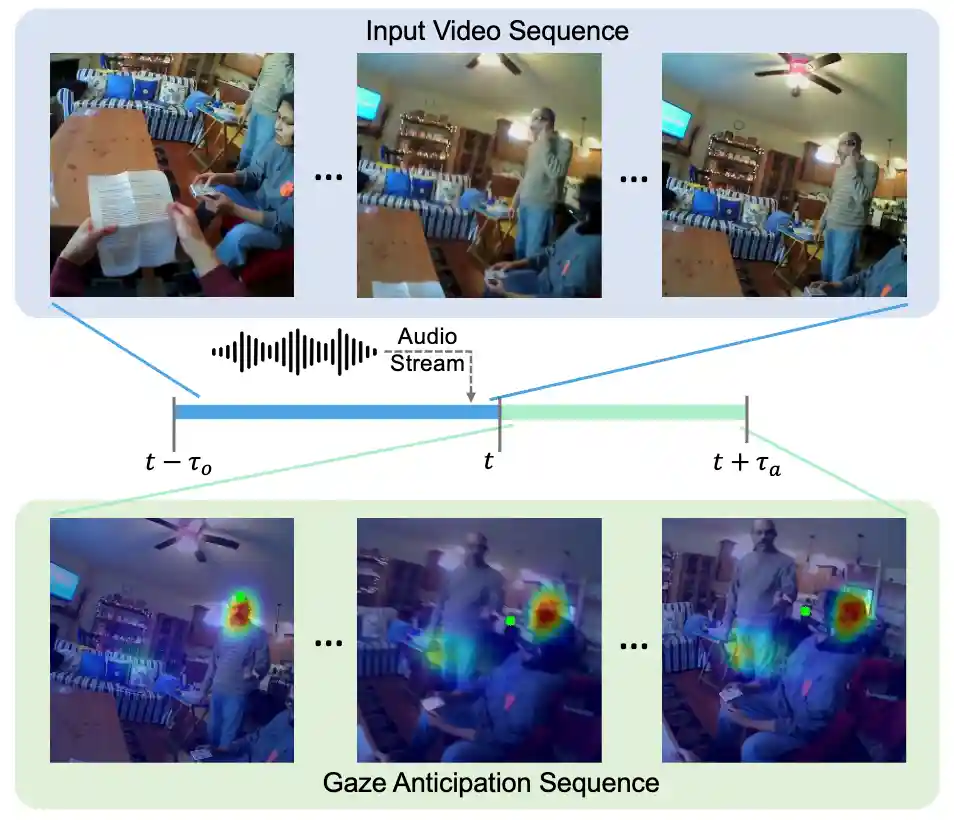
Listen to Look into the Future: Audio-Visual Egocentric Gaze Anticipation
Bolin Lai, Fiona Ryan, Wenqi Jia, Miao Liu*, James M. Rehg* ECCV, 2024Webpage / Paper / Code / Data Split / HuggingFace / Supplementary / Video / Poster |
|
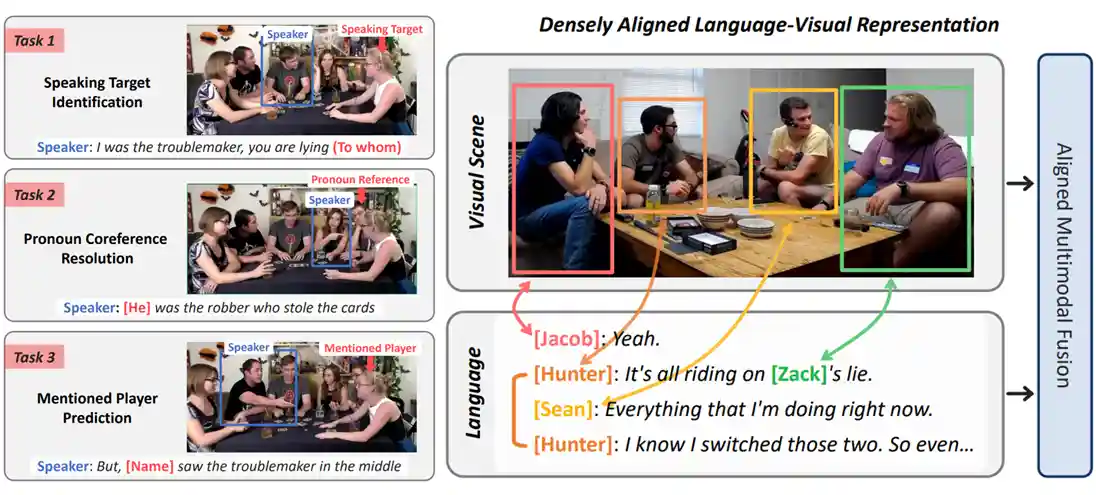
Modeling Multimodal Social Interactions: New Challenges and Baselines with Densely Aligned Representations
Sangmin Lee, Bolin Lai, Fiona Ryan, Bikram Boote, James M. Rehg CVPR, 2024 (Oral)Webpage / Paper / Code / Split & Annotations / Supplementary |

|
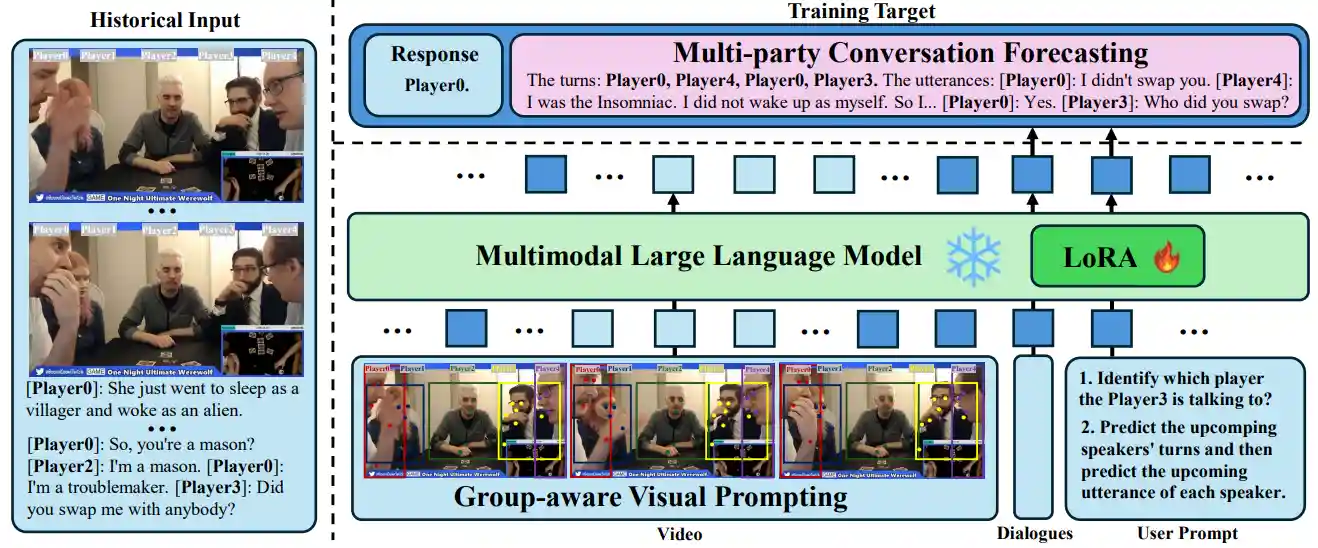
Werewolf Among Us: Multimodal Resources for Modeling Persuasion Behaviors in Social Deduction Games
Bolin Lai*, Hongxin Zhang*, Miao Liu*, Aryan Pariani*, Fiona Ryan, Wenqi Jia, Shirley Anugrah Hayati, James M. Rehg, Diyi Yang ACL Findings, 2023Webpage / Paper / Code / Dataset / Video |

|
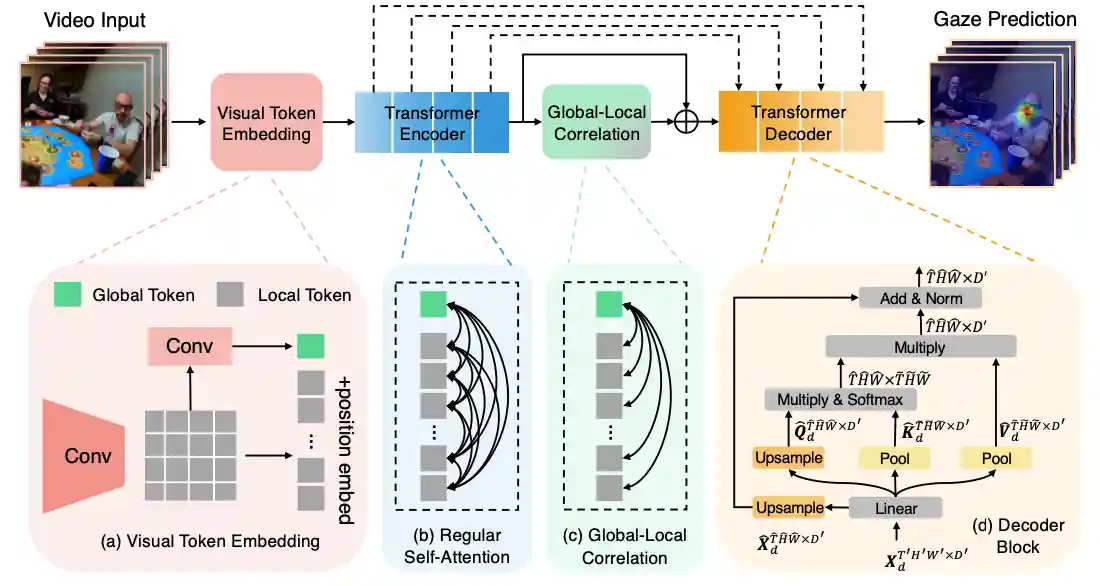
In the Eye of Transformer: Global-Local Correlation for Egocentric Gaze Estimation and Beyond
Bolin Lai, Miao Liu, Fiona Ryan, James M. Rehg International Journal of Computer Vision (IJCV), 2023Webpage / Paper / Code |
|
In the Eye of Transformer: Global-Local Correlation for Egocentric Gaze Estimation
Bolin Lai, Miao Liu, Fiona Ryan, James M. Rehg BMVC, 2022 (Spotlight, Best Student Paper)Webpage / Paper / Code / Data Split / Supplementary / Video / Poster |
{kind=link}
{kind=link}
{kind=link}
Research before my PhD, mainly about medical image analysis
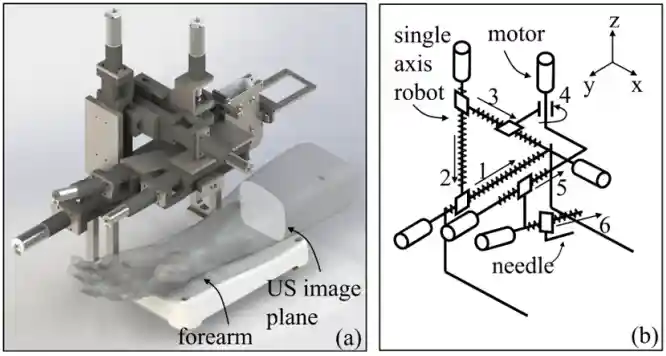
|
Semi-supervised Vein Segmentation of Ultrasound Images for Autonomous Venipuncture
Yu Chen, Yuxuan Wang, Bolin Lai, Zijie Chen, Xu Cao, Nanyang Ye, Zhongyuan Ren, Junbo Zhao, Xiao-Yun Zhou, Peng Qi IROS, 2021[Paper] |

|
Hetero-Modal Learning and Expansive Consistency Constraints for Semi-Supervised Detection from Multi-Sequence Data
Bolin Lai, Yuhsuan Wu, Xiao-Yun Zhou, Peng Wang, Le Lu, Lingyun Huang, Mei Han, Jing Xiao, Heping Hu, Adam P. Harrison Machine Learning in Medical Imaging, 2021[Paper] |
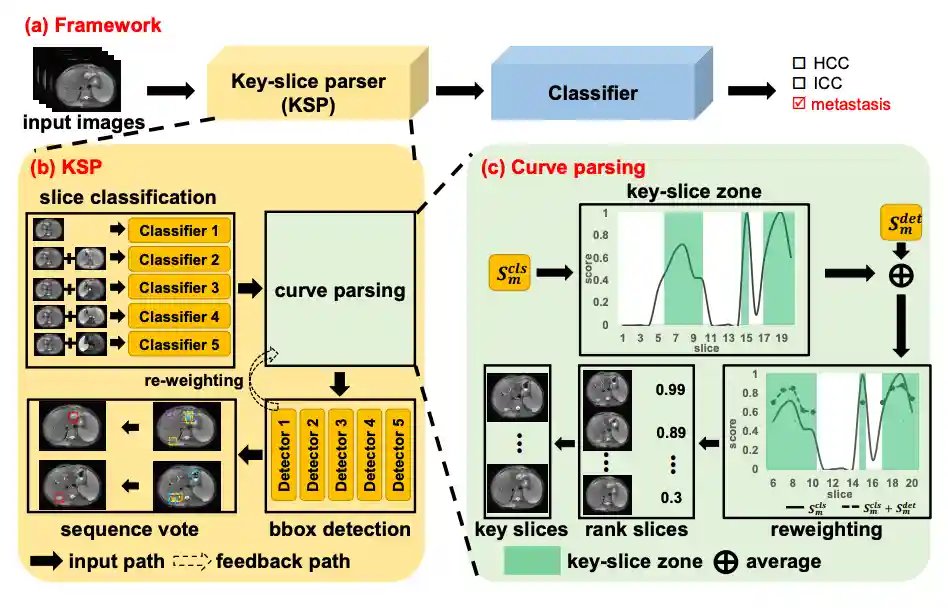
|
Liver Tumor Localization and Characterization from Multi-phase MR Volumes Using Key-Slice Prediction: A Physician-Inspired Approach
Bolin Lai*, Yuhsuan Wu*, Xiaoyu Bai*, Xiao-Yun Zhou, Peng Wang, Jinzheng Cai, Yuankai Huo, Lingyun Huang, Yong Xia, Jing Xiao, Le Lu, Heping Hu, Adam P. Harrison International Workshop on PRedictive Intelligence In MEdicine, 2021[Paper] |

|
Spatial Regularized Classification Network for Spinal Dislocation Diagnosis
Bolin Lai, Shiqi Peng, Guangyu Yao, Ya Zhang, Xiaoyun Zhang, Yanfeng Wang, Hui Zhao Machine Learning in Medical Imaging, 2019[Paper] |
Awards and Service
- EgoVis Distinghuished Paper Award @CVPR2025
- CVPR Outstanding Reviewer (2025)
- ECCV Best Paper Finalist (2024)
- BMVC Best Student Paper Prize (2022)
- Outstanding Graduate of SJTU (2020)
- Taught ECE4871 as a teaching assistant at Georgia Tech in 2021 and 2022.
- Taught CS7643 Deep Learning as a teaching assistant at Georgia Tech in 2024 and 2025.
{kind=link}
- Computer Vision and Pattern Recognition Conference (CVPR)
- International Conference on Computer Vision (ICCV)
- European Conference on Computer Vision (ECCV)
- Conference on Neural Information Processing Systems (NeurIPS)
- The Association for Computational Linguistics (ACL)
- Empirical Methods in Natural Language Processing (EMNLP)
- Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- International Journal of Computer Vision (IJCV)
- Association for the Advancement of Artificial Intelligence (AAAI)
- Transactions on Machine Learning Research (TMLR)
- International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)
- ACM Multimedia (ACM MM)
- Journal of Biomedical and Health Informatics (JBHI)
- IEEE Signal Processing Letters (SPL)