Chen Zhao
News
2026
- 2026-01-01 I will join Harbin Institute of Technology, Shenzhen (HITSZ) as a Professor in Spring 2026.
2025
- 2025-11-22 I gave a talk on “Invertible Diffusion Models for Inverse Problems” during my visit at Stanford Computational Imaging lab, Stanford. Thanks to Prof. Gordon Wetzstein for the invitation.
- 2025-10-19 We organized the SaFeMM-AI workshop at ICCV 2025, where we invited Prof. Yoshua Bengio as a speaker!
- 2025-04-27 I co-taught the master-level course “Machine Learning” (CS229) for the Ministry of Interior, Saudi Arabia, together with Prof. Marco Canini.
- 2025-04-10 We released SEVERE++, a comprehensive benchmark for studying generalization capabilities in video self-supervised learning.
- 2025-03-12 Ego4D got 1000+ citations!
- 2025-02-27 All 3 papers submitted to CVPR 2025 were accepted: BOLT, SMILE, OSMamba!
- 2025-02-05 IDM is published in TPAMI!
- 2025-01-26 I co-taught the master-level course “Deep Learning for Visual Computing” (CS323) for the Ministry of Interior, Saudi Arabia, together with Prof. Bernard Ghanem.
- 2025-01-14 I gave a talk on “Video Understanding for Embodied AI” virtually at Sun Yat-sen University. Thanks to Prof. Liang Lin for the invitation.
- 2025-01-08 I gave a talk on “Long-form Video Understanding in the 2020s” at Artifical Intelligence Research Institute, Shenzhen MSU-BIT. Thanks to Prof. Runhao Zeng for the invitation.
2024
- 2024-12-05 I gave a talk on “Long-form Video Understanding in the 2020s” at Cyber-Physical Systems Research Center, HITSZ. Thanks to Prof. Jingyong Su for the invitation.
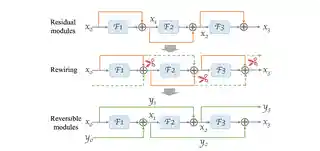
- 2024-10-07 I gave a lecture on “Reversifying Neural Networks: Efficient Memory Optimization Strategies for Finetuning Large Models” in KAUST CS Seminar. Thanks Prof. Di Wang for the invitation.
- 2024-06-18 I gave a talk on “Towards More Realistic Continual Learning at Scale” as an invited speaker in the CLVision Workshop in CVPR 2024, Seattle.
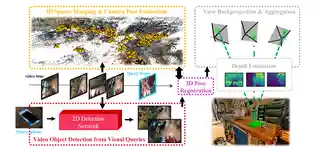
- 2024-06-17 We have won the first place in 4 challenges in CVPR 2024: Epic-kitchens audio-based interaction detection, Epic-kitchens action detection, Epic-kitchens action recognition, Ego4D Visual Queries 3D!
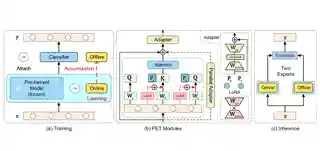
- 2024-06-11 I gave a talk on “Optimizing Memory Efficiency in Pretrained Model Finetuning” in the Berkeley Artificial Intelligence Research Lab (BAIR), UC Berkeley. Thanks to Prof. Jitendra Malik for the invitation.
- 2024-05-05 I gave a lecture in KAUST CEMSE graduate seminar on “Toward Long-form Video Understanding” as part of KAUST Research Open Week!
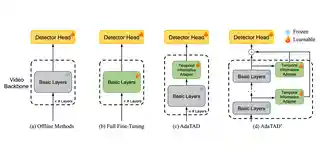
- 2024-03-28 We released OpenTAD, an open-source toolbox for temporal action detection (TAD), comprising 14 methods with 8 datasets.
- 2024-02-27 4 papers are accepted to CVPR 2024: Dr2Net, AdaTAD, TGT, and Ego-Exo4D!
- 2024-02-19 I gave a spotlight talk in the Rising Star in AI Symposium 2024 !
2023
- 2023-12-15 I gave a talk in HIT Webinar on “Challenges and innovation for long-form video understanding: compute, algorithm, and data”. Thanks to Prof. Jiancheng Yang for the invitation.
- 2023-08-24 I served as a judge in the finals of the AI for All Hackathon, organized by KAUST, the Ministry of Communications and Information Technology, and the Saudi Data & AI Authority.
- 2023-08-08 EgoLoc is selected as an ORAL in ICCV'23!
- 2023-08-07 Ego4D was accepted to TPAMI (recommended submission as an CVPR'22 award winner)!
- 2023-07-14 All three papers (LAE, FreeDoM, EgoLoc) submitted to ICCV'23 were accepted!
- 2023-06-22 SMILE won the Best Paper Award in CVPRW'23 CLVision!
- 2023-06-22 We won the first place in CVPR'23 Ego4D VQ3D Challenge!
- 2023-05-04 I was awarded the SDAIA-KAUST AI Fund!
- 2023-04-07 ETAD was accepted to CVPRW'23 ECV!
- 2023-04-04 OWL was accepted to CVPRW'23 L3D-IVU !
- 2023-03-29 SMILE was accepted to CVPRW'23 CLVision!
- 2023-02-27 Re2TAL and LF-VSN were accepted to CVPR'23!
- 2023-02-20 I gave a spotlight talk in the Rising Star in AI Symposium 2023 !
2022
- 2022-12-02 I was the lecturer in the Artificial Intelligence Bootcamp on behalf of KAUST to Saudi Arabia’s smartest undergraduate students!
- 2022-07-04 R-DFCIL and EASEE were accepted into ECCV'22!
- 2022-06-21 Ego4D got into CVPR'22 Best Paper Finalist!
- 2022-04-18 All Ego4D challenges are live now!
- 2022-03-29 Ego4D was accepted to CVPR'22 as ORAL presentation!
- 2022-03-29 MAD was accepted to CVPR'22!
2021
- 2021-11-30 I gave a talk on “Detecting Actions in Videos via Graph Convolutional Networks” virtually at the computer vision group, University of Bristol. Thanks to Prof. Dima Damen for the invitation.
- 2021-10-15 Ego4D was released and paper on arxiv!
- 2021-07-23 VSGN was accepted to ICCV'21!
- 2021-05-20 I was recognized by CVPR’21 as Outstanding Reviewer!
2020
- 2020-07-29 ThumbNet was accepted to ACM MM'20!
- 2020-06-07 We won the 2‑nd place in the HACS’20 Weakly‑supervised action detection Challenge!
- 2020-02-27 G-TAD was accepted to CVPR'20!
2019
- 2019-10-23 Our paper for YouTube-8M challenge got accepted as Oral presentation in ICCV'19 Workshop!
- 2019-10-12 We missed the gold medal by only 0.0004 in Kaggle’s 3rd YouTube‑8M Video Understanding Challenge; rank 9/11 out of 283 teams in the public/private leaderboards!
Publications
(*: equal contributions, †: corresponding author)
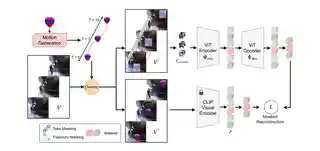
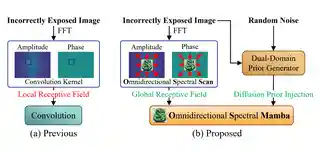
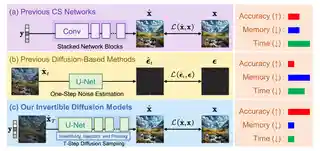
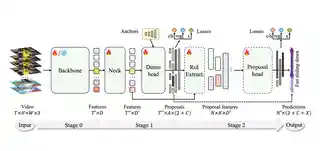
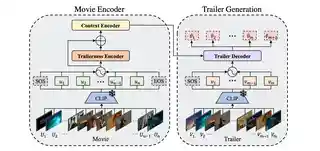
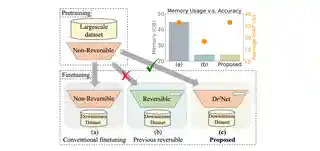
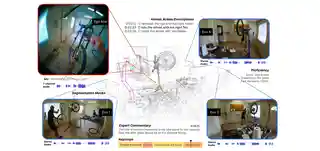

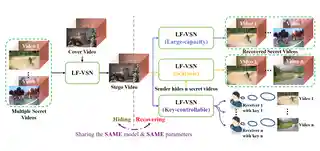
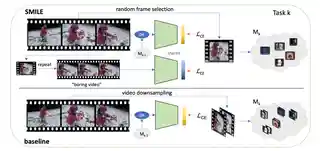
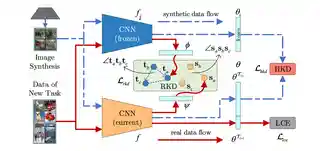


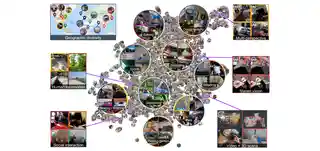
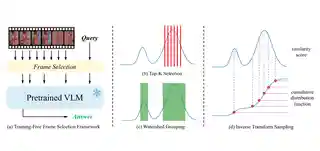
- Nov 2025
Invertible Diffusion Models for Inverse Problems
Talk, Stanford Computational Imaging lab, Stanford University, US
- Jan 2025
Video Understanding for Embodied AI
Online talk, Sun Yat-sen University, China
- Jan 2025
Long-form Video Understanding in the 2020s
Talk, Artificial Intelligence Research Institute, Shenzhen MSU-BIT, China
- Dec 2024
神经网络可逆化:大模型微调的高效显存优化策略
Online Talk, 走进顶尖AI科学家VOL.14, 创业黑马
- Dec 2024
Long-form Video Understanding in the 2020s
Talk, Cyber-Physical Systems Research Center, Harbin Institute of Technology, Shenzhen, China
- Oct 2024
Reversifying Neural Networks: Efficient Memory Optimization Strategies for Finetuning Large Models
Lecture, Computer Science Seminar, KAUST, Saudi Arabia
- Jun 2024
Towards More Realistic Continual Learning at Scale
Invited speaker, CLVision Workshop at CVPR 2024, Seattle, US
- Jun 2024
Optimizing Memory Efficiency in Pretrained Model Finetuning
Talk, OPPO, Seattle, US
- Jun 2024
Optimizing Memory Efficiency in Pretrained Model Finetuning
Talk, Berkeley Artificial Intelligence Research Lab (BAIR), UC Berkeley, US
- May 2024
Toward Long-form Video Understanding
Lecture, CEMSE Graduate Seminar | KAUST Research Open Week, KAUST, Saudi Arabia
- Jan 2024
Challenges and Advances in Long-form Video Understanding
Online talk, International Excellent Young Scholars Forum, School of ECE, Peking University, China
- Jan 2024
Towards Long-form Video Understanding
Talk, SUSTech Global Computer Scientist Forum, Shenzhen, China
- Dec 2023
Challenges and Innovation for Long-form Video Understanding: Compute, Algorithm, and Data
Online talk, Healthcare Intelligence and Technology Webinar
- Dec 2023
Research Highlights at IVUL with a Focus on Video Understanding
Talk, Shenzhen Research Institute of Big Data, Shenzhen, China
- Dec 2023
Towards Long-form Video Understanding
Talk, Global Young Scholars' Forum, CUHK Shenzhen, China
- Feb 2023
A Simple and Effective Approach for Long-form Video Understanding
Spotlight presentation, Rising Star in AI Symposium, KAUST, Saudi Arabia
- Nov 2021
Detecting Actions in Videos via Graph Convolutional Networks
Online talk, the Computer Vision Group, University of Bristol, UK
- Oct 2021
Let the Computer See the World as Humans
Online talk, Tsinghua Shenzhen International Graduate School, China
- Dec 2016
Image/Video Cloud Coding
Talk, School of Software Technology, Dalian University of Technology, China
- Sep 2016
Making a Lighter Encoder: Image/Video Compressive Sensing
Talk, Microsoft Research Asia Ph.D. Forum, Beijing, China
- Apr 2016
Compressive Sensing-based Image/Video Coding
Talk, Sony Company, San Jose, US
- Spring 2025
Machine Learning (CS229), KAUST
Lecturer, Master course for Ministry of Interior, Saudi Arabia
- Winter 2025
Deep Learning for Visual Computing (CS323), KAUST
Lecturer, Master course for Ministry of Interior, Saudi Arabia
- Summer 2024
Video understanding, KAUST
Hands-on instructor, Computer Vision Training Program for Tahakom
- Summer 2024
Machine learning, KAUST
Lecturer, AI Training Program for Tahakom
- Summer 2023
Deep learning, KAUST
Hands-on instructor, AI Training Program for Aramco
- Fall 2022
Deep learning, KAUST
Lecturer, AI Bootcamp program for selected undergraduate students in Saudi Arabia
- Spring 2022
Deep learning, KAUST
Lecturer, AI Bootcamp program for KAUST researchers and students
- 2024 First place, Ego4D Visual Queries 3D - CVPR 2024
- 2024 First place, Epic-Kitchens action detection - CVPR 2024
- 2024 First place, Epic-Kitchens action recognition - CVPR 2024
- 2024 First place, Epic-Kitchens audio-based interaction detection - CVPR 2024
- 2023 Recipient of Grant - the SDAIA-KAUST AI Fund
- 2023 Best Paper Award - CVPR Workshop CLVision
- 2023 First place, Visual Queries 3D Localization Challenge in Ego4D Workshop - CVPR 2023
- 2022 First place, Visual Queries 3D Localization Challenge in Ego4D Workshop - ECCV 2022
- 2021 Outstanding Reviewer - CVPR 2021
- 2020 Finalist - MIT Enterprise Forum Saudi Startup Competition
- 2020 Second place, HACS Temporal Action Localization Challenge - Second place, HACS Temporal Action Localization Challenge
- 2019 Finalist - Taqadam Startup Accelerator, Saudi Arabia
- 2016 Outstanding Graduate - Peking University
- 2016 Scholarship of Outstanding Talent - Peking University
- 2015 Best Paper Award - National Conference on Multimedia Technology (NCMT)
- 2012 First Prize, Qualcomm Innovation Fellowship Contest (QInF) - Only 2 awardees in China
- 2012 Outstanding Individual in the Summer Social Practice - Peking University
- 2010 Outstanding Graduate Leader - Sichuan University
- 2008 Goldman Sachs Global Leaders Award - Only 26 in China mainland and 150 worldwide
- 2007 First-Class Scholarship - Top 1 out of 329 students, Sichuan University
- 2007 National Scholarship - Top 1 out of 329 students, Sichuan University
Contact
Please fill in the following form to leave me a message.
Office No. 3124, Building 13, KAUST
Thuwal, Makkah Province
23955-6900
Saudi Arabia