
Easy, advanced inference platform for large language models on Kubernetes

llmaz (pronounced /lima:z/), aims to provide a Production-Ready inference platform for large language models on Kubernetes. It closely integrates with the state-of-the-art inference backends to bring the leading-edge researches to cloud.
🌱 llmaz is alpha now, so API may change before graduating to Beta.
Overview

Architecture
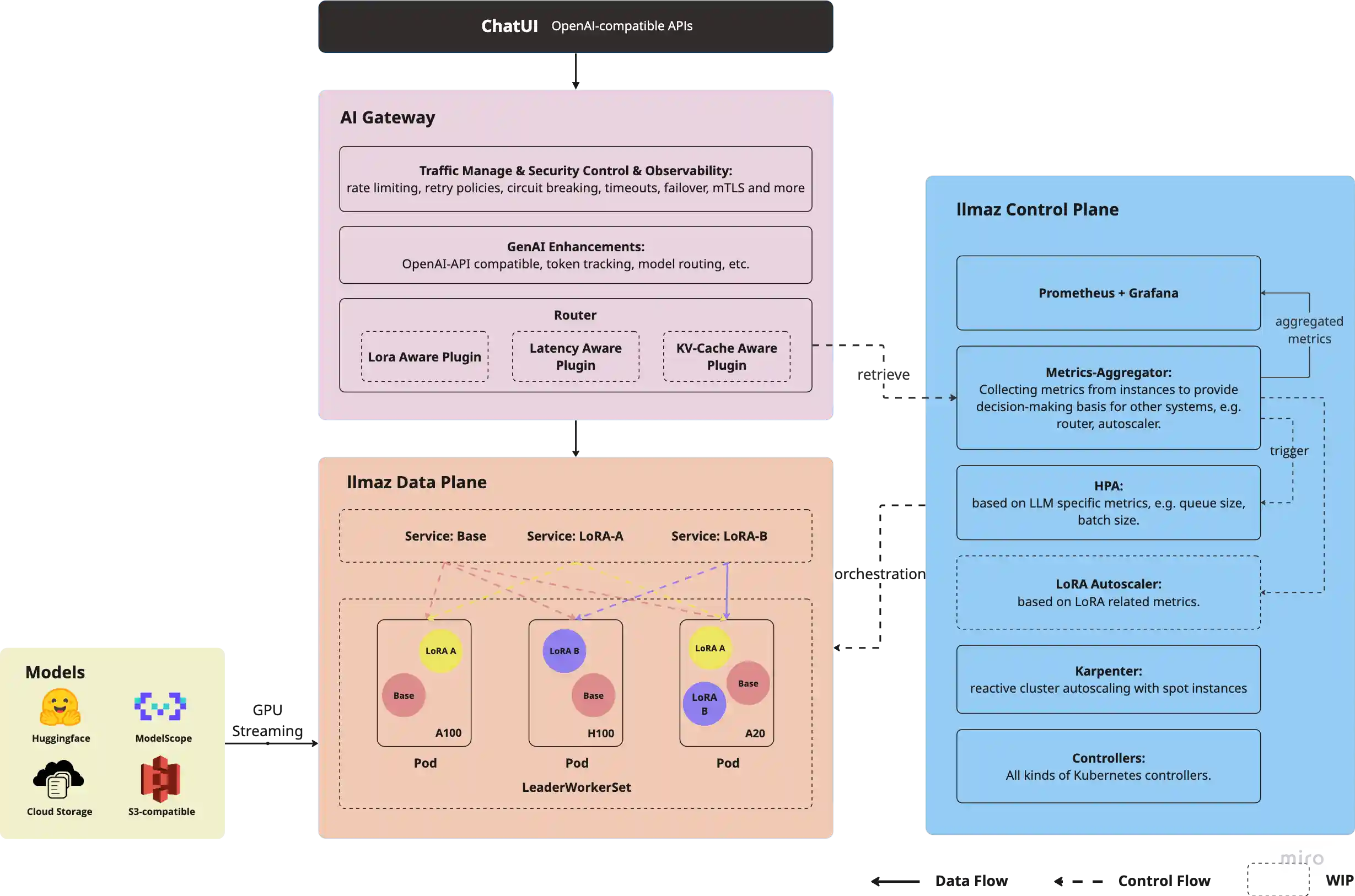
Key Features
- Easy of Use: People can quick deploy a LLM service with minimal configurations.
- Broad Backends Support: llmaz supports a wide range of advanced inference backends for different scenarios, like vLLM, Text-Generation-Inference, SGLang, llama.cpp, TensorRT-LLM. Find the full list of supported backends here.
- Heterogeneous Cluster Support: llmaz supports serving the same LLM with heterogeneous devices together with InftyAI Scheduler for the sake of cost and performance.
- Various Model Providers: llmaz supports a wide range of model providers, such as HuggingFace, ModelScope, ObjectStores. llmaz will automatically handle the model loading, requiring no effort from users.
- Distributed Inference: Multi-host & homogeneous xPyD support with LWS from day 0. Will implement the heterogeneous xPyD in the future.
- AI Gateway Support: Offering capabilities like token-based rate limiting, model routing with the integration of Envoy AI Gateway.
- Scaling Efficiency: Horizontal Pod scaling with HPA with LLM-based metrics and node(spot instance) autoscaling with Karpenter.
- Build-in ChatUI: Out-of-the-box chatbot support with the integration of Open WebUI, offering capacities like function call, RAG, web search and more, see configurations here.
Quick Start
Installation
Read the Installation for guidance.
Deploy
Here's a toy example for deploying facebook/opt-125m, all you need to do
is to apply a Model and a Playground.
If you're running on CPUs, you can refer to llama.cpp.
Note: if your model needs Huggingface token for weight downloads, please run
kubectl create secret generic modelhub-secret --from-literal=HF_TOKEN=<your token>ahead.
Model
apiVersion: llmaz.io/v1alpha1 kind: OpenModel metadata: name: opt-125m spec: familyName: opt source: modelHub: modelID: facebook/opt-125m inferenceConfig: flavors: - name: default # Configure GPU type limits: nvidia.com/gpu: 1
Inference Playground
apiVersion: inference.llmaz.io/v1alpha1 kind: Playground metadata: name: opt-125m spec: replicas: 1 modelClaim: modelName: opt-125m
Verify
Expose the service
By default, llmaz will create a ClusterIP service named like <service>-lb for load balancing.
kubectl port-forward svc/opt-125m-lb 8080:8080
Get registered models
curl http://localhost:8080/v1/models
Request a query
curl http://localhost:8080/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "opt-125m", "prompt": "San Francisco is a", "max_tokens": 10, "temperature": 0 }'
More than quick-start
Please refer to examples for more tutorials or read develop.md to learn more about the project.
Roadmap
- Serverless support for cloud-agnostic users
- Prefill-Decode disaggregated serving
- KV cache offload support
- Model training, fine tuning in the long-term
Community
Join us for more discussions:
Contributions
All kinds of contributions are welcomed ! Please following CONTRIBUTING.md.
We also have an official fundraising venue through OpenCollective. We'll use the fund transparently to support the development, maintenance, and adoption of our project.