PICa
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
by Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, and Lijuan Wang
The 36th AAAI Conference on Artificial Intelligence (AAAI), 2022, Oral
Introduction
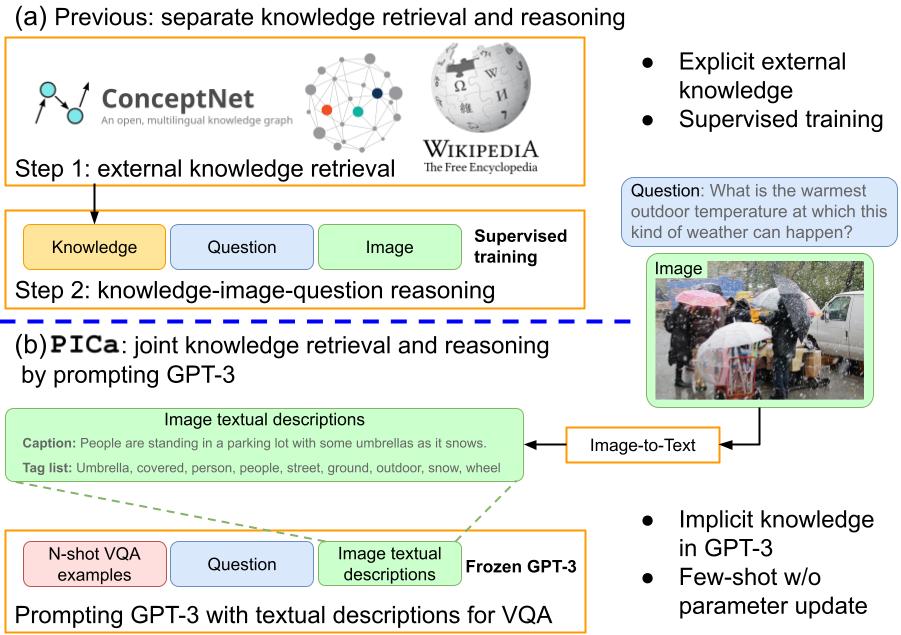
Can GPT-3 benefit multimodal tasks? We provide an empirical study of GPT-3 for knowledge-based VQA, named PICa. We show that prompting GPT-3 via the use of image captions with only 16 examples surpasses supervised sota by an absolute +8.6 points on the OK-VQA dataset (from 39.4 to 48.0).
Citation
@inproceedings{yang2021empirical,
title={An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA},
author={Yang, Zhengyuan and Gan, Zhe and Wang, Jianfeng and Hu, Xiaowei and Lu, Yumao and Liu, Zicheng and Wang, Lijuan},
booktitle={AAAI},
year={2022}
}
Prerequisites
- Obtain the public OpenAI GPT-3 API key and install the API Python bindings.
Installation
-
Clone the repository
git clone https://github.com/microsoft/PICa.git -
Prepare the data The cached files for converted OKVQA data, predicted text representations, and similarity features are in the
coco_annotations,input_text, andcoco_clip_newfolders, respectively.
Running
- We experimented with the older engine
davinciinstead of the current defaulttext-davinci-001that is boosted for instruction tuning, see more discussion here.python gpt3_api_okvqa.py --apikey xxx --output_path output ## for example python gpt3_api_okvqa.py --apikey xxx --output_path output --engine davinci --similarity_metric random --n_ensemble 1 --n_shot 16 python gpt3_api_okvqa.py --apikey xxx --output_path output --engine davinci --similarity_metric imagequestion --n_ensemble 5 --n_shot 16
Results
-
Outputs will be saved to
format_answerandprompt_answerfolders.format_answeris used for final evaluation, following the vqav2 format.prompt_answercontains the input prompt for human interpretation. -
output_savedprovides the cached predictions.