Java Data-structure
精于心,简于形

数组
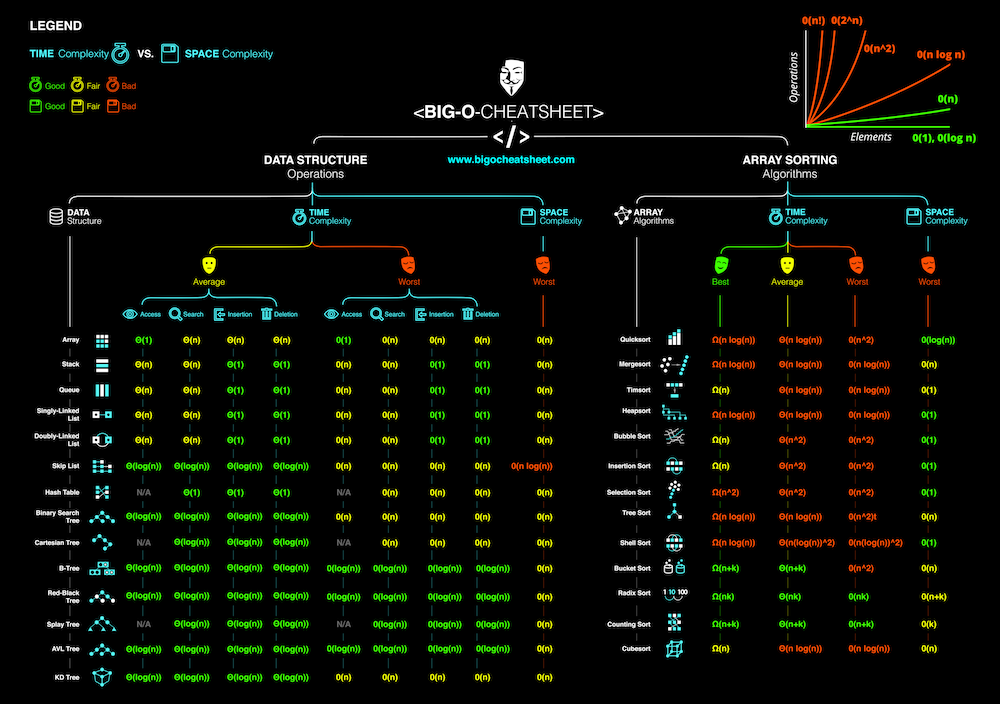
- O(1) access/modify via index
- O(N) iteration (memory friendly)
- O(N) search for a particular value in an unsorted array
- O(logN) search for a value in a sorted array
code
int[] myArray = new int[3];
for (int i = 0; i < myArray.length; i++) {
myArray[i] = i;
}
System.out.println("Items in array:");
for (int i: myArray) {
System.out.println(i + " ");
}
Array List
ArrayList底层是用数组实现的,随着元素添加,其大小是动态增大的;在内存中是连续存放的;如果在集合末尾添加或删除元素,所用时间是一致的,如果在列表中间添加或删除元素,所用时间会大大增加。通过索引查找元素速度很快。适合场合:查询比较多的场景
- O(1) access/modify via index
- O(1) Append
- O(N) iteration (memory friendly)
- O(N) search for a particular value in an unsorted List
ArrayList myArrayList = new ArrayList();
myArrayList.add('a');
myArrayList.add('b');
myArrayList.add('c');
System.out.println("Second char is: " + myArrayList.get(1));
System.out.println("Chars in list:");
for (int i = 0; i < myArrayList.size(); i++) {
System.out.println(myArrayList.get(i));
}
Vector
Vector与ArrayList基本是一致的,不同的是Vector是线程安全的,会在可能出现线程安全的方法前面加上synchronized关键字。 Vector特点是随机访问速度快,插入和移除性能较差。该类可以使用Collections.synchronizedList替换掉。
Linked List
- O(N) access/modify via index
- O(1) Adding to front
- O(N) iteration
- O(N) search for a particular value in an unsorted List
code
LinkedList linkedList = new LinkedList();
//set value
for (int i=0; i<3; i++) {
linkedList.add(i + "");
}
for (String value: linkedList) {
System.out.println(value);
}
Set
- O(1) insert
- O(1) checking whether it contains a value
code
Set mySet = new HashSet();
mySet.add("Book");
mySet.add("Pear");
mySet.add("Apple");
mySet.add("Book");
mySet.add("Class");
mySet.add("Orange");
mySet.add("Class");
System.out.println("My set elements count: " + mySet.size());
for (String item : mySet) {
System.out.println(item);
}
Bitmap
code
BitSet myBitSet = new BitSet(1);
System.out.println(myBitSet.size()); //64
myBitSet = new BitSet(65);
System.out.println(myBitSet.size()); //128
myBitSet = new BitSet(23);
System.out.println(myBitSet.size()); //64
//将数组内容组bitmap
myBitSet.set(1, true);
myBitSet.set(2, true);
myBitSet.set(3, true);
myBitSet.set(0, true);
myBitSet.set(3, true);
System.out.println(myBitSet.get(2));
System.out.println(myBitSet.get(60));
for ( int i = 0; i < myBitSet.size(); i++ ){
System.out.println(myBitSet.get(i));
}
Stack
- O(1) to add to the top of the stack (add)
- O(1) to remove the top of the stack (pop)
- O(N) to iterate
code1
Stack myStack = new Stack<>();
myStack.push("Apple");
myStack.push("Pear");
myStack.push("Grape");
System.out.println(myStack.size() + " items in stack:");
for(String item : myStack){
System.out.println(item);
}
while (!myStack.isEmpty()){
String top = myStack.peek();
System.out.println("Stack Top: " + top);
myStack.pop();
}
code2
Deque myStack2 = new ArrayDeque();
myStack2.push("Apple");
myStack2.push("Pear");
myStack2.push("Grape");
Map
- O(1) insert
- O(1) access & modify via Key
- O(1) check if it contains certain Key
- O(N) to look for a particular value
desc
散列表:插入删除查找都是O(1), 是最常用的,但其缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于那些不需要顺序遍历,数据更新不那么频繁的。code
Map myMap = new HashMap<>();
myMap.put("T.Rex", 100);
myMap.put("Bob", 35);
myMap.put("Jack", 25);
for(String key : myMap.keySet()){
System.out.println(key + " : " + myMap.get(key));
}
Hashtable
线程安全版本 HashMap
LinkedHashMap
可以利用LinkedHashMap实现LRU Cache
code
class LruCache extends LinkedHashMap {
private final int maxEntries;
public LruCache(final int maxEntries) {
super(maxEntries + 1, 1.0f, true);
this.maxEntries = maxEntries;
}
@Override
protected boolean removeEldestEntry(final Map.Entry<A, B> eldest) {
return super.size() > maxEntries;
}
}
Queue
- O(1) to add to the end of the queue (add)
- O(1) to remove the front of the queue (poll)
- O(N) to iterate
code
Queue myQueue = new LinkedList();
myQueue.add("Box");
myQueue.add("T.Rex");
myQueue.add("Jack");
System.out.println();
System.out.println(myQueue.size() + " items in the queue: ");
for(String i : myQueue){
System.out.println(i);
}
while(!myQueue.isEmpty()){
String front = myQueue.peek();
System.out.println("Front of the queue: " + front);
System.out.println(" pop");
myQueue.poll();
}
LinkedBlockingQueue
线程安全版本Queue
Heap
- O(1) Inserting an element
- O(1) Accessing smallest element
- O(log(n)) Removing biggest element
code
Queue logic = new PriorityQueue<>(new Comparator() {
@Override
public int compare(Integer i1, Integer i2){
return i2-i1;
}
});
Queue pq = new PriorityQueue<>(logic);
pq.add(1);
pq.add(2);
pq.add(0);
System.out.println("max element -> "+pq.peek());
Delay Queue
TODO
Skip List
- O(logn) Access complexity
- O(logn) Search complexity
- O(logn) Delete complexity
- O(logn) Insert complexity
desc
跳表:插入删除查找都是O(logn), 并且能顺序遍历。缺点是空间复杂度O(n)。适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便。
下面是一个包含 64 个结点的链表,按照前面讲的这种思路,建立了五级索引。原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点。

code
ConcurrentSkipListMap mySkipListMap = new ConcurrentSkipListMap();
System.out.println(mySkipListMap);
mySkipListMap.put(1, "a");
mySkipListMap.put(2, "b");
mySkipListMap.put(3, "c");
mySkipListMap.put(1, "d");//测试同一个key值
mySkipListMap.put(4, "e");
mySkipListMap.put(6, "f");
mySkipListMap.put(5, "g");
System.out.println(mySkipListMap);
System.out.println(mySkipListMap.size());
Red-black tree
- O(logn) Insert
- O(logn) Search
- O(logn) Deletion
desc
插入删除查找都是O(logn), 中序遍历即是顺序遍历,稳定。缺点是难以实现,code
TreeMap myTreeMap = new TreeMap();
myTreeMap.put(2,"2");
myTreeMap.put(3,"3");
myTreeMap.put(1,"1");
System.out.println(myTreeMap);
Tire-Tree
Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
- O(n) build tree n 表示所有字符串的长度和
- O(k) k 表示查找的字符串长度
code
class Trie
{
// Define the alphabet size (26 characters for `a – z`)
private static final int CHAR_SIZE = 26;
private boolean isLeaf;
private List<Trie> children = null;
// Constructor
Trie()
{
isLeaf = false;
children = new ArrayList<>(Collections.nCopies(CHAR_SIZE, null));
}
// Iterative function to insert a string into a Trie
public void insert(String key)
{
System.out.println("Inserting \"" + key + "\"");
// start from the root node
Trie curr = this;
// do for each character of the key
for (char c: key.toCharArray())
{
// create a new Trie node if the path does not exist
if (curr.children.get(c - 'a') == null) {
curr.children.set(c - 'a', new Trie());
}
// go to the next node
curr = curr.children.get(c - 'a');
}
// mark the current node as a leaf
curr.isLeaf = true;
}
// Iterative function to search a key in a Trie. It returns true
// if the key is found in the Trie; otherwise, it returns false
public boolean search(String key)
{
System.out.print("Searching \"" + key + "\" : ");
Trie curr = this;
// do for each character of the key
for (char c: key.toCharArray())
{
// go to the next node
curr = curr.children.get(c - 'a');
// if the string is invalid (reached end of a path in the Trie)
if (curr == null) {
return false;
}
}
// return true if the current node is a leaf node and the
// end of the string is reached
return curr.isLeaf;
}
}