
Explorando y entendiendo Python a través de ejemplos sorprendentes.
Traducciones: Inglés English | Chino 中文 | Vietnamita Tiếng Việt
Otras versiones: Interactivo | CLI
Python, al ser un lenguaje de programación basado en el intérprete y al estar diseñado en alto nivel, nos permite utilizar muchas funcionalidades para nuestra comodidad. Pero, a veces, los resultados de un código de Python pueden parecernos confusos al principio.
Este es un proyecto divertido que tiene como objetivo explicar exactamente qué está ocurriendo bajo el código de funciones confusas y no muy conocidas que vemos en Python.
A pesar de que algunos de los ejemplos que leas abajo no sean "WTF!", te enseñarán algunas partes interesantes del funcionamiento de Python que probablemente no conozcas. Creo que es una buena manera de aprender el funcionamiento interno de un lenguage de programación, ¡y creo que tu también pensarás lo mismo!
Si eres un programador de Python experto, puedes tomar este proyecto como una prueba e intentar adivinar el resultado al primer intento. Puede que ya hallas experimentado algunos de estos códigos antes, ¡y puede que revivan algunos de tus recuerdos! 😅
PD: Si lees este proyecto con frecuencia, puedes enterarte de nuevas modificaciones aquí (los ejemplos marcados con un asterisco son los añadidos en la última versión mayor).
Ahora si, vamos a comenzar...
Contenido
- Estructura de los ejemplos
- Uso
- 👀 Ejemplos
- Sección: ¡ejercita tu cerebro!
- ▶ ¡Primero lo primero! *
- ▶ Los strings pueden ser confusos de vez en cuando
- ▶ Ten cuidado con las operaciones en cadena
- ▶ Como no utilizar el operador
is - ▶ Dulces hash
- ▶ En el fondo, todos somos iguales
- ▶ Desorden en el orden *
- ▶ Sigue intentando... *
- ▶ ¿Para qué?
- ▶ Discrepancia de evaluación de tiempo
- ▶
is not ...no esis (not ...) - ▶ ¡Un tres en raya en donde la X gana la primera jugada!
- ▶ La variable de Schrödinger *
- ▶ El problema del huevo de gallina *
- ▶ Relaciones entre subclases
- ▶ Equidad e identidad de métodos
- ▶ Siempre verdadero *
- ▶ La coma extraña
- ▶ Strings y barras invertidas
- ▶ ¡Ahora no!
- ▶ Strings con medias tres comillas
- ▶ ¿Cuál es el problema con los booleanos?
- ▶ Atributos de clase y de instancia
- ▶ Devolviendo
None - ▶ ¡Usando
yielddesde return! * - ▶ Reflexividad NAN *
- ▶ ¡Mutando lo inmutable!
- ▶ La variable de alcance exterior que desaparece
- ▶ La misteriosa conversión de la llave
- ▶ Veamos si puedes adivinar esto...
- Sección: pendientes resbaladizas
- ▶ Modificando un diccionario a la vez que iteramos por él
- ▶ El rebelde operador
del - ▶ La variable fuera de alcance
- ▶ Borrar un elemento de una lista al iterar sobre ella
- ▶ Pérdidas en los iteradores *
- ▶ ¡Fuga de variables en bucles!
- ▶ ¡Ten cuidado con los argumentos mutables predeterminados!
- ▶ Detectando las excepciones
- ▶ ¡Mismos operandos, cuestiones diferentes!
- ▶ Resolución de nombres ignorando el alcance de la clase
- ▶ Agujas en un pajar *
- ▶ Separando valores *
- ▶ Importes "wild" *
- ▶ ¿Todo ordenado? *
- ▶ ¿No existe la medianoche?
- Sección: ¡tesoros ocultos!
- Sección: ¡las apariencias engañan!
- Sección: varios
- Sección: ¡ejercita tu cerebro!
- Contribuir
- Reconocimientos
- 🎓 Licencia
Estructura de los ejemplos
Todos los ejemplos están estructurados de la siguiente manera:
▶ Título
# Comienzo del código. # Preparándose para la magia...Output (version(es) de Python):
>>> triggering_statement Output inesperado(Opcional): Una línea describiendo el output inesperado.
💡 Explicación:
- Explicación corta de qué está ocurriendo y por qué está ocurriendo.
# Comienzo del código # Más ejemplos para entender mejor (si es necesario)Output (version(es) de Python):
>>> trigger # algún ejemplo que haga que sea fácil ver la magia # output justificado
Nota: Todos los ejemplos están probados en el intérprete interactivo en Python 3.5.2 y deberían funcionar en todas las otras versiones de Python a menos que se haya indicado explícitamente lo contrario en el output.
Uso
Una buena manera de obtener el mayor conocimiento de estos ejemplos, en mi opinión, es leerlos cronológicamente, y para cada ejemplo hacer lo siguiente:
- Leer el código inicial del comienzo del código cuidadosamente. Si eres un programador de Python experimentado seguramente anticiparás correctamente lo que pasará luego.
- Lee el output y,
- Revisa si el output es igual al que te imaginabas.
- Asegúrate de que conoces la razón exacta de que el output sea ese.
- Si la respuesta es "no" (lo cual está bien), toma un suspiro y lee la explicación de nuevo. Si aun no entiendes, ¡no te preocupes! puedes crear un Issue aquí.
- Si la respuesta es "si", puedes darte una palmadita en la espalda y leer el siguiente ejemplo.
PD: También puedes leer WTFPython en la línea de comandos usando el paquete pypi,
$ pip install wtfpython -U $ wtfpython
👀 Ejemplos
Sección: ¡ejercita tu cerebro!
▶ ¡Primero lo primero! *
Por alguna razón, el operador "Walrus" de Python 3.8+ (:=) se ha vuelto popular. Vamos a verlo,
1.
# versión de Python: 3.8+ >>> a = "wtf_walrus" >>> a 'wtf_walrus' >>> a := "wtf_walrus" File "<stdin>", line 1 a := "wtf_walrus" ^ SyntaxError: invalid syntax >>> (a := "wtf_walrus") # Esto sí funciona 'wtf_walrus' >>> a 'wtf_walrus'
2 .
# versión de Python: 3.8+ >>> a = 6, 9 >>> a (6, 9) >>> (a := 6, 9) (6, 9) >>> a 6 >>> a, b = 6, 9 # Desempaquetado común >>> a, b (6, 9) >>> (a, b = 16, 19) # Oops File "<stdin>", line 1 (a, b = 6, 9) ^ SyntaxError: invalid syntax >>> (a, b := 16, 19) # Esto devuelve un tuple extraño de 3 elementos (6, 16, 19) >>> a # ¿permanece "a" sin cambios todavía? 6 >>> b 16
💡 Explicación:
Resumen rápido del operador Walrus
El operador Walrus (:=) fue introducido en Python 3.8, y puede ser útil cuando quieras asignar valores a variables dentro de una expresión.
def some_func(): # Asume una computación grande aquí # time.sleep(1000) return 5 # Así que, en vez de, if some_func(): print(some_func()) # Lo cual es una mala práctica porque la operación está ocurriendo dos veces # o a = some_func() if a: print(a) # Ahora puedes escribir con seguridad if a := some_func(): print(a)
Output (> 3.8):
Esto nos salvó una línea de código e implícitamente previno la invocación de some_func dos veces.
-
Una expresión de asignación sin parénteris (uso del operador Walrus) está restringida al nivel superior, por eso se devuelve el error
SyntaxErroren la declaracióna := "wtf_walrus"en el primer código. Al poner paréntesis a la declaración hacemos que funcione correctamente y se asigne el valor a la variablea. -
Como siempre, al ponerle paréntesis a una expresión que contiene el operador
=no está permitido. Es por eso que se devuelve el error en(a, b = 6, 9). -
La sintaxis del operador Walrus está en la forma
NOMBRE := expresión, dondeNOMBREes un identificador válido yexpresiónes una expresión válida. Por eso, el empaquetamiento y desempaquetamiento no está permitido, lo que significa que,-
(a := 6, 9)es equivalente a((a := 6), 9)y en consecuencia a(a, 9)(donde el valor deaes 6)>>> (a := 6, 9) == ((a := 6), 9) True >>> x = (a := 696, 9) >>> x (696, 9) >>> x[0] is a # Ambos hacen referencia al mismo espacio en memoria True
-
Similarmente,
(a, b := 16, 19)es equivalente a(a, (b := 16), 19)el cual no es más que un tuple de 3 elementos.
-
▶ Los strings pueden ser confusos de vez en cuando
1.
>>> a = "some_string" >>> id(a) 140420665652016 >>> id("some" + "_" + "string") # Ambas IDs son las mismas 140420665652016
2.
>>> a = "wtf" >>> b = "wtf" >>> a is b True >>> a = "wtf!" >>> b = "wtf!" >>> a is b False
3.
>>> a, b = "wtf!", "wtf!" >>> a is b # Todas las versiones excepto 3.7.x True >>> a = "wtf!"; b = "wtf!" >>> a is b # Esto devolverá True o False dependiendo de en dónde lo estés invocando (consola Python / iPython / en un archivo) False
# Ahora en un archivo llamado some_file.py a = "wtf!" b = "wtf!" print(a is b) # ¡Devuelve True cuando el módulo es invocado!
4.
Output (< Python3.7)
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa' True >>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa' False
Tiene sentido, ¿cierto?
💡 Explicación:
- El comportamiento en la primera y segunda porción de código es debido a una optimización de CPython (llamada "string interning (internado)") que intenta usar objetos inmutables en algunos casos en vez de crear un nuevo objeto cada vez.
- Luego de ser "internado" muchas variables pueden hacer referencia al mismo objeto string en memoria (salvando así memoria).
- En las porciones de código de arriba, los strings son internados implícitamente. La decisión de cuando internar un string implícitamente depende de la implementación. Hay algunas reglas que se pueden usar para averiguar si un string será internado o no:
- Todos los strings con longitud 0 y 1 son internados.
- Los strings son internados en el tiempo de compilación (
wtfserá internado pero''.join(['w', 't', 'f'])no será internado). - Los strings que no están compuestos de letras ASCII, dígitos o pisos bajos no son internados. Esto explica porqué
'wtf!'no fue internado debido al!. La implementación de esta regla en CPython puede ser encontrada aquí.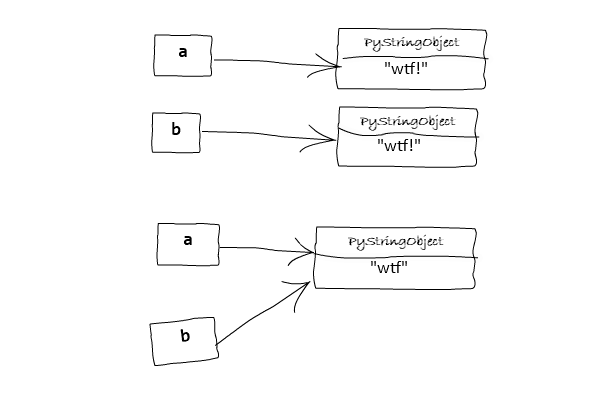
- Cuando
aybson asignadas a"wtf!en la misma línea, el intérprete de Python crea un nuevo objeto, para luego hacer referencia a la segunda variable al mismo tiempo. Si lo haces en líneas separadas, Python "no sabe" que ya existe"wft!"como un objeto (porque"wtf!"no está implícitamente internado debido a lo mencionado arriba). Es una optimización en el tiempo de compilación. Esta optimización no aplica a las versiones 3.7.x de CPython (clickea este [Issue])(satwikkansal#100) para ver una discusión sobre esto). - Una unidad de compilación en un ambiente interactivo (como IPython) consiste en una sola declaración, donde consiste en un módulo entero en caso de módulos.
a, b = "wtf!", "wtf!"es una sola declaración, mientras quea = "wtf!"; b = "wtf!"son dos declaraciones en una misma línea. Esto explica por qué las identidades son diferentes ena = "wtf!"; b = "wtf!", y también explica por qué son las mismas cuando son invocadas ensome_file.py. - El cambio abrupto en el output de la cuarta porción de código es debido a la optimización peephole, técnica conocida como "Constant folding". Esto significa que la expresión
'a'*20es reemplazada por'aaaaaaaaaaaaaaaaaaaa'durante la compilación para salvar algunos ciclos de reloj durante el tiempo de ejecución. "Constant folding" solo ocurre en strings que tienen una longitud menor a 21. (¿Por qué? Imagina el tamaño del archivo.pycgenerado como resultado de la expresión'a'*10**10). Aquí está la implementación para esto mismo. - Nota: En Python 3.7, "Constant folding" fue movido del optimizador peephole al optimizador AST con algún cambio en la lógica, haciendo que la cuarta porción de código no funcione en Python 3.7. Puedes leer más acerca de este cambio aquí.

▶ Ten cuidado con las operaciones en cadena
>>> (False == False) in [False] # tiene sentido False >>> False == (False in [False]) # tiene sentido False >>> False == False in [False] # ¿ahora qué? True >>> True is False == False False >>> False is False is False True >>> 1 > 0 < 1 True >>> (1 > 0) < 1 False >>> 1 > (0 < 1) False
💡 Explicación:
Según https://docs.python.org/3/reference/expressions.html#membership-test-operations
Formalmente, si a, b, c, ..., y, z son expresiones y op1, op2, ..., opN son operadores de comparación, entonces op1 b op2 c ... y opN z es equivalente a a op1 b y b op2 c y ... y opN z, excepto que cada expresión es evaluada al menos una vez.
Aunque puedas considerar tonto este comportamiento en los ejemplso de arriba, es fantástico cuando se aplica a cosas como a == b == c y 0 <= x <= 100.
False is False is Falsees equivalente a(False is False) and (False is False)True is False == Falsees equivalente aTrue is False and False == Falsey debido a que la primera parte de la declaración (True is False) devuelveFalse, la expresión completa devuelveFalse.1 > 0 < 1es equivalente a1 > 0 and 0 < 1, la cual devuelveTrue.- La expresión
(1 > 0) < 1es equivalente aTrue < 1ySo,>>> int(True) 1 >>> True + 1 # no es relevante para este ejemplo 2
1 < 1devuelveFalse
▶ Como no utilizar el operador is
El código siguiente es un ejemplo muy famoso en el internet.
1.
>>> a = 256 >>> b = 256 >>> a is b True >>> a = 257 >>> b = 257 >>> a is b False
2.
>>> a = [] >>> b = [] >>> a is b False >>> a = tuple() >>> b = tuple() >>> a is b True
3. Output
>>> a, b = 257, 257 >>> a is b True
Output (Python 3.7.x específicamente)
>>> a, b = 257, 257 >> a is b False
💡 Explicación:
La diferencia entre is y ==
- El operador
isrevisa si ambos operandos hacen referencia al mismo objeto (revisa si la identidad de los operandos combinan o no). - El operador
==compara los valores de ambos operandos y prueba si son iguales. - Entonces,
ises para la equidad de referencia y==para la equidad de valor. A continuación un ejemplo para hacer más clara la explicación,>>> class A: pass >>> A() is A() # Estos son dos objetos diferentes en dos espacios de memoria diferentes. False
256 es un objeto existente, pero 257 no lo es
Cuando abres Python, los números desde el -5 hasta el 256 son alocados. Estos números son usados un montón; es por esto que Python los prepara al comienzo.
Nota de https://docs.python.org/3/c-api/long.html
La implementación actual mantiene un array de objetos de enteros para todos los enteros entre -5 y 256. Cuando creas un entero en ese rango, simplemente obtienes la referencia a ese objeto existente. Así que, debería ser posible cambiar el valor de 1. Creo que el comportamiento de Python en este caso es indefinido. :-)
>>> id(256) 10922528 >>> a = 256 >>> b = 256 >>> id(a) 10922528 >>> id(b) 10922528 >>> id(257) 140084850247312 >>> x = 257 >>> y = 257 >>> id(x) 140084850247440 >>> id(y) 140084850247344
Aquí el intérprete no es tan inteligente al ejecutar y = 257 para reconocer que ya hemos creado un entero con el valor 257 y crea un objeto nuevo y lo aloja en la memoria.
Una optimización similar ocurre a otros objetos inmutables, como tuples vacíos. Ya que las listas son mutables, [] is [] devolverá False y () is () devolverá True. Esto explica la segunda porción del código.
Ahora, veamos la tercera,
Tanto a como b hacen referencia al mismo objeto cuando son inicializadas con el mismo valor en la misma línea.
Output
>>> a, b = 257, 257 >>> id(a) 140640774013296 >>> id(b) 140640774013296 >>> a = 257 >>> b = 257 >>> id(a) 140640774013392 >>> id(b) 140640774013488
-
Cuando se le asigna el valor
257aayben la misma línea el intérprete de Python crea un nuevo objeto y hace referencia a la segunda variable al mismo tiempo. Si lo haces en líneas diferentes, el intérprete "no sabe" que ya existe257como un objeto. -
Es una optimización del compilador y específicamente aplica al ambiente interactivo. Cuando escriber dos líneas en un intérprete vivo, estas son compiladas por separado, lo que hace que sean optimizadas por separado. Si intentas escribir este ejemplo en un archivo
.pyverás que el comportamiento no es el mismo, ya las líneas en los archivos son compiladas de una sola vez. Esta optimización no se limita a enteros, también funciona para otros tipos de datos inmutables como strings (lee "Los strings son confusos") y tuples,>>> a, b = 257.0, 257.0 >>> a is b True
-
¿Por qué no funciona en Python 3.7? La razón abstracta es que estas optimizaciones del compilador son específicas a la implementación (ej: varían según la versión, el sistema operativo, etc.). Todavía estoy investigando qué implementación causa este error. Puedes ver este Issue para más información.
▶ Dulces hash
1.
some_dict = {} some_dict[5.5] = "JavaScript" some_dict[5.0] = "Ruby" some_dict[5] = "Python"
Output:
>>> some_dict[5.5] "JavaScript" >>> some_dict[5.0] # ¿"Python" destruyó la existencia de "Ruby"? "Python" >>> some_dict[5] "Python" >>> complex_five = 5 + 0j >>> type(complex_five) complex >>> some_dict[complex_five] "Python"
¿Por qué está "Python" por todos lados?
💡 Explicación:
-
Las llaves en los diccionarios de Python funcionan por equivalencia, no por identidad. Aunque
5,5.0y5 + 0json objetos diferentes de tipos diferentes, ya que son iguales, no pueden estar en el mismodict(oset). Cuando insertes cualquiera de ellos, al intentar tomar una llave distinta pero equivalente tomará en realidad un valor mapeado (en vez de devolver unKeyError):>>> 5 == 5.0 == 5 + 0j True >>> 5 is not 5.0 is not 5 + 0j True >>> some_dict = {} >>> some_dict[5.0] = "Ruby" >>> 5.0 in some_dict True >>> (5 in some_dict) and (5 + 0j in some_dict) True
-
Esto también aplica al declarar un elemento. Cuando escribes
some_dict[5] = "Python", Python encuentra el elemento existente con una llave equivalente5.0 -> "Ruby", los reemplaza en el lugar y deja la llave original sin tocar.>>> some_dict {5.0: 'Ruby'} >>> some_dict[5] = "Python" >>> some_dict {5.0: 'Python'}
-
Entonces, ¿cómo podemos actualizar la llave a
5(en vez de5.0)? No podemos hacer esto en el lugar, pero lo que podemos hacer es: primero, borrar la llave (del some_dict[5.0]); luego, actualizarla (some_dict[5]) para obtener el entero5como la llave en vez del decimal5.0(aun así, esto no será necesario en la mayoría de los casos). -
¿Cómo Python encontró
5en un diccionario que contiene5.0? Python hace esto constantemente sin la necesidad de escanear cada uno de los elementos usando funciones hash. Por ejemplo, cuando Python busca una llave llamadafooen un diccionario, primero ejecutahash(foo)(constantemente). Ya que en Python para que los objetos que se comparan por igual necesitan tener el mismo valor hash (documentación),5,5.0y5 + 0jtienen el mismo valor hash.>>> 5 == 5.0 == 5 + 0j True >>> hash(5) == hash(5.0) == hash(5 + 0j) True
Nota: lo contrario no es necesariamente cierto: los objetos con el mismo valor hash pueden ser desiguales. (Esto causa lo que es conocido como una colisión hash) y degrada el tiempo de rendimiento que el hash provee).
▶ En el fondo, todos somos iguales
Output:
>>> WTF() == WTF() # dos instancias diferentes no pueden ser iguales False >>> WTF() is WTF() # las identidades también son diferentes False >>> hash(WTF()) == hash(WTF()) # los hash también deberían ser diferentes True >>> id(WTF()) == id(WTF()) True
💡 Explicación:
-
Cuando
ides llamada, Python crea un objeto de la claseWTFy la pasa a la funciónid. La funciónidtoma suid(su espacio en memoria) y desecha el objeto (lo destruye). -
Cuando hacemos estos dos veces en una sucesión, Python asigna el mismo espacio en memoria al segundo objeto también. Ya que
idusa el espacio de memoria como la identificación del objeto (en CPython), la identificación de ambos objetos es la misma. -
Es por esto que la identificación del objeto es única solo mientras el objeto existe. Cuando el objeto es destruido o antes de que sea creado, cualquier otro objeto puede tener la misma identificación.
-
Pero, ¿por qué el operador
isdevolvióFalse? Veamos la respuesta en esta porción de código.class WTF(object): def __init__(self): print("I") def __del__(self): print("D")
Output:
>>> WTF() is WTF() I I D D False >>> id(WTF()) == id(WTF()) I D I D True
Como puedes ver, el orden en el que los objetos son destruidos es la causa de la diferencia ocurrida.
▶ Desorden en el orden *
from collections import OrderedDict dictionary = dict() dictionary[1] = 'a'; dictionary[2] = 'b'; ordered_dict = OrderedDict() ordered_dict[1] = 'a'; ordered_dict[2] = 'b'; another_ordered_dict = OrderedDict() another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a'; class DictWithHash(dict): """ Un diccionario que también implementa la magia de __hash__. """ __hash__ = lambda self: 0 class OrderedDictWithHash(OrderedDict): """ Un diccionario ordenado (OrderedDict) que también implementa la magia de __hash__. """ __hash__ = lambda self: 0
Output
>>> dictionary == ordered_dict # Si a == b True >>> dictionary == another_ordered_dict # y b == c True >>> ordered_dict == another_ordered_dict # entonces, ¿por qué c no es igual a a (c == a)? False # Sabemos que un set consiste en elementos únicos. # Intentemos crear un set de estos diccionarios a ver qué ocurre... >>> len({dictionary, ordered_dict, another_ordered_dict}) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'dict' # Tiene sentido, ya que "dict" no tiene __hash__ implementado. Usemos # nuestras clases anidadas. >>> dictionary = DictWithHash() >>> dictionary[1] = 'a'; dictionary[2] = 'b'; >>> ordered_dict = OrderedDictWithHash() >>> ordered_dict[1] = 'a'; ordered_dict[2] = 'b'; >>> another_ordered_dict = OrderedDictWithHash() >>> another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a'; >>> len({dictionary, ordered_dict, another_ordered_dict}) 1 >>> len({ordered_dict, another_ordered_dict, dictionary}) # cambiando el orden 2
¿Qué está ocurriendo aquí?
💡 Explicación:
-
La razón por la cual la equidad intransitiva no es soportada entre
dictionary,ordered_dictyanother_ordered_dictradica en la forma en que el método__eq__está implementado en la claseOrderedDict. Información de la documentación.Las pruebas de equidad entre los objetos OrderedDict dependen del orden y son implementados como
list(od1.items())==list(od2.items()). Estas pruebas aplicadas a estos objetos (al igual que a otros objetos de mapeo) no dependen del orden (al igual que los diccionarios regulares). -
La razón de esta equidad en el comportamiento permite a los objetos
OrderedDicta ser sustituidos directamente en cualquier lugar del código en donde un diccionario regular sea usado. -
Entonces, ¿por qué al cambiar el orden se afecta la longitud del objeto
setgenerado? La respuesta es que solo está presenta la equidad intransitiva. Ya que los sets son colecciones "desordenadas" de elementos únicos, el orden en el que los elementos son insertados no debería importar. Pero, en este caso si importa. Veamos el porqué,>>> some_set = set() >>> some_set.add(dictionary) # estos son los objetos de mapeo de las porciones de código de arriba >>> ordered_dict in some_set True >>> some_set.add(ordered_dict) >>> len(some_set) 1 >>> another_ordered_dict in some_set True >>> some_set.add(another_ordered_dict) >>> len(some_set) 1 >>> another_set = set() >>> another_set.add(ordered_dict) >>> another_ordered_dict in another_set False >>> another_set.add(another_ordered_dict) >>> len(another_set) 2 >>> dictionary in another_set True >>> another_set.add(another_ordered_dict) >>> len(another_set) 2
La inconsistencia se debe a que
another_ordered_dict in another_setdevuelveFalseporqueordered_dictya estaba presente enanother_sety, como vimos anteriormente,ordered_dict == another_ordered_dictesFalse.
▶ Sigue intentando... *
def some_func(): try: return 'from_try' finally: return 'from_finally' def another_func(): for _ in range(3): try: continue finally: print("Finally!") def one_more_func(): # ¡Lo tenemos! try: for i in range(3): try: 1 / i except ZeroDivisionError: # Vamos a dejar esto aquí y manejarlo fuera del loop raise ZeroDivisionError("A trivial divide by zero error") finally: print("Iteration", i) break except ZeroDivisionError as e: print("Zero division error occurred", e)
Output:
>>> some_func() 'from_finally' >>> another_func() Finally! Finally! Finally! >>> 1 / 0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero >>> one_more_func() Iteration 0
💡 Explicación:
- Cuando una declaración
return,breakocontinuees ejecutada entrydentro de una declaración "try...finally", la cláusulafinallytambién está siendo ejecutada al terminar la operación. - El valor que devuelve una función es determinado por la última declaración
returnejecutada. Ya que la cláusulafinallysiempre se ejecuta, una declaraciónreturnejecutada en una cláusulafinallysiempre será la última en ser ejecutada. - El problema aquí es que si la cláusula
finallyejecuta una declaraciónreturnobreak, la excepción temporal guardada es descartada.
▶ ¿Para qué?
some_string = "wtf" some_dict = {} for i, some_dict[i] in enumerate(some_string): i = 10
Output:
>>> some_dict # Un diccionario indexado aparece. {0: 'w', 1: 't', 2: 'f'}
💡 Explicación:
-
La declaración
forestá definida en la gramática de Python como:for_stmt: 'for' exprlist 'in' testlist ':' suite ['else' ':' suite]Donde
exprlistes la asignación. Esto significa que el equivalente de{exprlist} = {next_value}es ejecutado por cada elemento en el bucle. Este es un ejemplo interesante que muestra lo anterior escrito:for i in range(4): print(i) i = 10
Output:
¿Esperabas que el bucle iterara solo una vez?
💡 Explicación:
- La declaración de asignación
i = 10nunca afecta a las iteraciones del bucle debido a la forma en la que los bucles funcionan en Python. Antes de comenzar cada iteración, el siguiente elemento seleccionado por el bucle (range(4)en este caso) es desempaquetado y asignado a las variables (ien este caso).
- La declaración de asignación
-
La función
enumerate(some_string)devuelve un nuevo valori(un contador que incrementa) y un caracter desome_stringen cada iteración. Luego asigna la llaveidel diccionariosome_dicta ese caracter. El bucle puede ser simplificado como:>>> i, some_dict[i] = (0, 'w') >>> i, some_dict[i] = (1, 't') >>> i, some_dict[i] = (2, 'f') >>> some_dict
▶ Discrepancia de evaluación de tiempo
1.
array = [1, 8, 15] # Una expresión generadora típica gen = (x for x in array if array.count(x) > 0) array = [2, 8, 22]
Output:
>>> print(list(gen)) # ¿A dónde fueron los otros valores? [8]
2.
array_1 = [1,2,3,4] gen_1 = (x for x in array_1) array_1 = [1,2,3,4,5] array_2 = [1,2,3,4] gen_2 = (x for x in array_2) array_2[:] = [1,2,3,4,5]
Output:
>>> print(list(gen_1)) [1, 2, 3, 4] >>> print(list(gen_2)) [1, 2, 3, 4, 5]
3.
array_3 = [1, 2, 3] array_4 = [10, 20, 30] gen = (i + j for i in array_3 for j in array_4) array_3 = [4, 5, 6] array_4 = [400, 500, 600]
Output:
>>> print(list(gen)) [401, 501, 601, 402, 502, 602, 403, 503, 603]
💡 Explicación:
-
En un generador, la cláusula
ines evaluada cuando es declarada, pero la cláusula condicional es evaluada cuando se ejecuta el archivo. -
Antes de la ejecución,
arrayes reasignado a la lista[2, 8, 22]y debido a que entre los valores1,8y15solo la cuenta del8es mayor a0, el generador solo devuelve8. -
La diferencia en el output de
g1yg2de la segunda parte se debe a la forma en la que las variablesarray_1yarray_2son reasignadas. -
En el primer caso,
array_1es agregado al nuevo objeto[1,2,3,4,5]y como la cláusulaines evaluada cuando es declarada todavía hace referencia al objeto antiguo[1,2,3,4](el cual no es destuido). -
En el segundo caso, la asignación de
array_2actualiza el mismo objeto antiguo[1,2,3,4]a[1,2,3,4,5]. Es por esto que ambosg2yarray_2todavía hacen referencia al mismo objeto (el cual ha sido actualizado a[1,2,3,4,5]). -
Siguiendo la lógica que hemos estado discutiendo hasta ahora, te preguntarás, ¿no debería ser el valor de
list(g)en la tercera porción de código ser[11, 21, 31, 12, 22, 32, 13, 23, 33]? (porquearray_3yarray_4se comportarán al igual quearray_1). La razón por la cual solo se actualizaron los valores dearray_4se explica en PEP-289Solo la expresión
fordel exterior será evaluada inmediatamente. Las otras expresiones son aplazafas hasta que el generador sea ejecutado.
▶ is not ... no es is (not ...)
>>> 'something' is not None True >>> 'something' is (not None) False
💡 Explicación:
is notes un operador binario singular y su comportamiento es diferente que al usarisynotseparados.is notdevuelveFalsesi las variables de cualquiera de los lados hacen referencia al mismo objeto. Lo contrario devuelveTrue.- En el ejemplo,
(not None)devuelveTruedebido a que el valorNoneesFalseen un contexto boleano. Entonces, la expresión se vuelve'something' is True.
▶ ¡Un tres en raya en donde la X gana la primera jugada!
# Inicializamos una fila row = [""] * 3 # fila i['', '', ''] # Hacemos una tabla board = [row] * 3
Output:
>>> board [['', '', ''], ['', '', ''], ['', '', '']] >>> board[0] ['', '', ''] >>> board[0][0] '' >>> board[0][0] = "X" >>> board [['X', '', ''], ['X', '', ''], ['X', '', '']]
No asignamos tres "X", ¿cierto?
💡 Explicación:
Cuando inicializamos la variable row, ocurre esto en la memoria (explicado en la ilustración):

Y cuando board es inicializada multiplicando row, esto es lo que ocurre dentro de la memoria (cada elemento board[0], board[1] y board[2] hacen referencia a la misma lista referida por row).

Podemos evitar este escenario si no utilizamos la variable row para generar board. (Preguntado en este Issue).
>>> board = [['']*3 for _ in range(3)] >>> board[0][0] = "X" >>> board [['X', '', ''], ['', '', ''], ['', '', '']]
▶ La variable de Schrödinger *
funcs = [] results = [] for x in range(7): def some_func(): return x funcs.append(some_func) results.append(some_func()) # llamamos a la función aquí funcs_results = [func() for func in funcs]
Output (versión de Python):
>>> results [0, 1, 2, 3, 4, 5, 6] >>> funcs_results [6, 6, 6, 6, 6, 6, 6]
Los valores de x eran diferentes en cada iteración anterior a la asignación de some_func a funcs, pero todas las funciones devuelven 6 cuando son evaluadas luego de que el bucle finaliza.
>>> powers_of_x = [lambda x: x**i for i in range(10)] >>> [f(2) for f in powers_of_x] [512, 512, 512, 512, 512, 512, 512, 512, 512, 512]
💡 Explicación:
- Cuando se define una función dentro de un bucle que usa la variable del bucle, la cláusula de la función del bucle es agregada a la variable, no al valor. La función busca
xen el contexto en vez de usar el valor dexcuando la función es creada. Todas las funciones usan el último valor asignado a la variable. Podemos ver que está usando laxdel contexto (no es una variable local):
>>> import inspect >>> inspect.getclosurevars(funcs[0]) ClosureVars(nonlocals={}, globals={'x': 6}, builtins={}, unbound=set())
Ya que x es un valor global. Por eso, podemos cambiar el valor que funcs buscará y devolverlo actualizando x:
>>> x = 42 >>> [func() for func in funcs] [42, 42, 42, 42, 42, 42, 42]
- Para obtener el comportamiento deseado puedes pasar la variable en el bucle como una variable con nombre a la función. ¿Por qué funciona esto? Funciona porque esto definirá la variable dentro del alcance de la función. Ya no buscará en el alcance global las los valores de las variables pero creará una variable local que almacena el valor de
xen ese mismo momento.
funcs = [] for x in range(7): def some_func(x=x): return x funcs.append(some_func)
Output:
>>> funcs_results = [func() for func in funcs] >>> funcs_results [0, 1, 2, 3, 4, 5, 6]
Ya no está usando x en el alcance local:
>>> inspect.getclosurevars(funcs[0]) ClosureVars(nonlocals={}, globals={}, builtins={}, unbound=set())
▶ El problema del huevo de gallina *
1.
>>> isinstance(3, int) True >>> isinstance(type, object) True >>> isinstance(object, type) True
Así que, ¿cual es la clase base "definitiva"? Hay más que añadir a esta pregunta,
2.
>>> class A: pass >>> isinstance(A, A) False >>> isinstance(type, type) True >>> isinstance(object, object) True
3.
>>> issubclass(int, object) True >>> issubclass(type, object) True >>> issubclass(object, type) False
💡 Explicación:
typees una metaclase en Python.- Todo es un objeto (
object) en Python. Esto incluye también a las clases y sus objetos (isntancias). - La clase
typees la metaclase de la claseobject, y cada clase (incluyendotype) hereda directamente o indirectamente deobject. - Realmente, no hay una clase base entre
objectytype. La confusión en las porciones de código de arriba existe porque estamos pensando en estas relaciones (issubclasseisinstance) en términos de clases de Python. La relación entreobjectytypeno puede ser reproducida en Python puro. Para ser más preciso, las siguientes relaciones no pueden ser reproducidas en Python puro,- la clase A es una instancia de la clase B, y la clase B es una instancia de la clase A.
- la clase A es una instancia de sí misma.
- Estas relaciones entre
objectytype(ambas siendo instancias de la otra al igual que de ellas mismas) existen en Python debido a "hacer trampa" en el nivel de implementación.
▶ Relaciones entre subclases
Output:
>>> from collections import Hashable >>> issubclass(list, object) True >>> issubclass(object, Hashable) True >>> issubclass(list, Hashable) False
Se suponía que las relacioens entre subclases fueran transitivas, ¿no? (si A es una subclase de B y B es una subclase de C, A debe ser una subclase de C)
💡 Explicación:
- Las relaciones entre subclases en Python no son necesariamente transitivas. Todos pueden definiar las suyas propias. Arbitrariamente
__subclasscheck__es una metaclase. - Cuando
issubclass(cls, Hashable)es llamada, simplemente revisa si el método "__hash__" está enclso cualquier otra de donde hereda. - Ya que
objectes "hashable" perolistno es "hashable", rompe la relación de la transitividad. - Puedes encontrar una explicación más detallada aquí.
▶ Equidad e identidad de métodos
class SomeClass: def method(self): pass @classmethod def classm(cls): pass @staticmethod def staticm(): pass
Output:
>>> print(SomeClass.method is SomeClass.method) True >>> print(SomeClass.classm is SomeClass.classm) False >>> print(SomeClass.classm == SomeClass.classm) True >>> print(SomeClass.staticm is SomeClass.staticm) True
Al acceder a classm dos veces, ¿obtenemos un objeto igual pero no el mismo? Veamos qué ocurre con isntancias de SomeClass:
o1 = SomeClass() o2 = SomeClass()
Output:
>>> print(o1.method == o2.method) False >>> print(o1.method == o1.method) True >>> print(o1.method is o1.method) False >>> print(o1.classm is o1.classm) False >>> print(o1.classm == o1.classm == o2.classm == SomeClass.classm) True >>> print(o1.staticm is o1.staticm is o2.staticm is SomeClass.staticm) True
Al acceder a classm o method dos veces se crean objetos iguales pero no los mismos de la misma instancia de SomeClass.
💡 Explicación:
- Las funciones son descriptivas. Cuando se accede a una función como atributo, la descripción es invocada y se crea un objeto de método que junta la función son el objeto que tiene el atributo. Si es llamada, el método llama a la función y pasa implícitamente el objeto como primer argumento (de esta manera es que obtenemos
selfcomo primer argumento a pesar de no pasarlo explícitamente).
>>> o1.method <bound method SomeClass.method of <__main__.SomeClass object at ...>>
- Al acceder al atributo muchas veces se crea un objeto método cada vez. Es por eso que
o1.method is o1.methodnunca es verdadero. Al acceder a funciones como atributos de clase (opuesto a la instancia) no se crean métodos. Así que,SomeClass.method is SomeClass.methodes verdadero.
>>> SomeClass.method <function SomeClass.method at ...>
classmethodtransforma functiones en métodos de clase, Los métodos de clase son descriptores que, al ser accedidos, crean un objeto método que una la clase (tipo) del objeto en vez del objeto en sí mismo.
>>> o1.classm <bound method SomeClass.classm of <class '__main__.SomeClass'>>
classmethod, a diferencia de las funciones, también creará un método cuando sea accedido como un atributo de clase (en este caso unen la clase, no su tipo). Esto hace queSomeClass.classm is SomeClass.classmse falso.
>>> SomeClass.classm <bound method SomeClass.classm of <class '__main__.SomeClass'>>
- Un objeto método devuelve verdadero cuando ambas funciones son iguales y los objetos son los mismos. Es por esto que
o1.method == o1.methodes verdadero (aunque no es el mismo objeto en memoria). staticmethodtransforma funciones en un descriptor, el cual devuelve la función tal cual como es. No se crea ningún objeto método, haciendo que al compararse conisdevuelva verdadero.
>>> o1.staticm <function SomeClass.staticm at ...> >>> SomeClass.staticm <function SomeClass.staticm at ...>
- Crear nuevos objetos "método" cada vez que Python llama a las intancias y tener que modificar los argumentos para pasar
selfafecta el rendimiento de una mala manera. Esto se resolvió en CPython 3.7 al introducir nuevos códigos que controlan las llamadas a métodos sin tener que crear objetos de métodos temporales. Esto ocurre solo cuando la función con la que se trabaja es llamada, por lo que las porciones de código del ejemplo no son afectadas y aun generan métodos :)
▶ Siempre verdadero *
>>> all([True, True, True]) True >>> all([True, True, False]) False >>> all([]) True >>> all([[]]) False >>> all([[[]]]) True
¿Por qué ocurre esta alteración de booleans?
💡 Explicación:
-
La implementación de la función
alles equivalente a -
def all(iterable): for element in iterable: if not element: return False return True
-
all([])devuelveTrueya que el iterable está vacío. -
all([[]])devuelveFalseporquenot [] is Truees equivalente anot Falseya que la lista de dentro del iterable está vacía. -
all([[[]]])y variantes recursivas de alto nivel siempre sonTruedebido a quenot [[]],not [[[]]]y demás son equivalentes anot True. -
all([[[]]])and higher recursive variants are alwaysTruesincenot [[]],not [[[]]], and so on are equivalent tonot True.
▶ La coma extraña
Output (< 3.6):
>>> def f(x, y,): ... print(x, y) ... >>> def g(x=4, y=5,): ... print(x, y) ... >>> def h(x, **kwargs,): File "<stdin>", line 1 def h(x, **kwargs,): ^ SyntaxError: invalid syntax >>> def h(*args,): File "<stdin>", line 1 def h(*args,): ^ SyntaxError: invalid syntax
💡 Explicación:
- Adjuntar una coma al final no siempre es legal en parámetros formales de una función de Python.
- En Python, la lista de argumentos está definida parcialmente con comas al principio y parcialmente con comas al final. Este conflicto causa situaciones en las que una coma está atrapada en el medio y ninguna regla la acepta.
- Nota: el problema de la coma al final está resuelto en Python 3.6. En las notas de este artículo se discuten los diferentes usos de las comas al final en Python.
▶ Strings y barras invertidas
Output:
>>> print("\"") " >>> print(r"\"") \" >>> print(r"\") File "<stdin>", line 1 print(r"\") ^ SyntaxError: EOL while scanning string literal >>> r'\'' == "\\'" True
💡 Explicación:
- En un string de Python, la barra invertida es utilizada para escribir caracteres que tengan un significado especial (como las comillas y las barras invertidas).
- En un raw-string (indicado por el prefijo 'r') las barras invertidas se pasan a ellas mismas al igual que el comportamiento de escribir los caracteres que le siguen.
>>> r'wt\"f' == 'wt\\"f' True >>> print(repr(r'wt\"f') 'wt\\"f' >>> print("\n") >>> print(r"\\n") '\\n'
- Esto significa que cuando un linter se encuentra una barra invertida en un raw-string, espera encontrar otro caracter que le siga. En nuestro caso (
print(r"\")) la barra ivertida escribe unas comillas al final, dejando al linter sin terminar el string (devuelveSyntaxError). Es por eso que las barras invertidas no funcionan al final de un raw-string.
▶ ¡Ahora no!
Output:
>>> not x == y True >>> x == not y File "<input>", line 1 x == not y ^ SyntaxError: invalid syntax
💡 Explicación:
- La precedencia de los operadores afecta a cómo la expresión es evaluada. El operador
==tiene mayor precedencia que el operadornoten Python. not x == yes equivalente anot (x == y)el cual a su vez es equivalente anot (True == False), devolviendo finalmenteTrue.x == not ydevuelveSyntaxErrorporque se cree que es equivalente a(x == not) yy no ax == (not y), lo que tal vez esperabas al principio.- El intérprete esperaba que la palabra
notforme parte del operadornot in(porque ambos operadores==ynot intienen la misma precedencia), pero, al no encontrar la palabrainluego denot, devuelveSyntaxError
▶ Strings con medias tres comillas
Output:
>>> print('wtfpython''') wtfpython >>> print("wtfpython""") wtfpython >>> # Lo siguiente devuelve `SyntaxError` >>> # print('''wtfpython') >>> # print("""wtfpython") File "<input>", line 3 print("""wtfpython") ^ SyntaxError: EOF while scanning triple-quoted string literal
💡 Explicación:
- Python soporta la concatenación literal de strings implícitamente. Ejemplo,
>>> print("wtf" "python") wtfpython >>> print("wtf" "") # or "wtf""" wtf '''y"""también son delimitadores de strings en Python, los cuales devuelvenSyntaxErrorporque el intérprete de Python esperaba otras tres comillas al final para delimitar el string.
▶ ¿Cuál es el problema con los booleanos?
1.
# Un simple ejemplo para contar el número de booleans y # enteros en un iterable de tipos de datos mixtos. mixed_list = [False, 1.0, "some_string", 3, True, [], False] integers_found_so_far = 0 booleans_found_so_far = 0 for item in mixed_list: if isinstance(item, int): integers_found_so_far += 1 elif isinstance(item, bool): booleans_found_so_far += 1
Output:
>>> integers_found_so_far 4 >>> booleans_found_so_far 0
2.
>>> some_bool = True >>> "wtf" * some_bool 'wtf' >>> some_bool = False >>> "wtf" * some_bool ''
3.
def tell_truth(): True = False if True == False: print("I have lost faith in truth!")
Output (< 3.x):
>>> tell_truth() I have lost faith in truth!
💡 Explicación:
-
booles una subclase deinten Python.>>> issubclass(bool, int) True >>> issubclass(int, bool) False
-
Por eso,
TrueyFalseson instancias deint.>>> isinstance(True, int) True >>> isinstance(False, int) True
-
El valor entero de
Truees1y el deFalsees0.>>> int(True) 1 >>> int(False) 0
-
Puedes leer esta respuesta de StackOverflow para entender la lógica detrás.
-
Inicialmente, Python no tenía un tipo de dato
bool(los programadores usaban 0 para indicar falso y un valor desigual a cero para indicar verdadero. Generalmente el 1). Los tiposTrue,Falseyboolfueron añadidos en las versiones 2.x pero, por cuestiones de compatibilidad,TrueyFalseno podían ser constantes. Ambos eran tan solo variables, permitiendo al programador reasignar su valor. -
En Python 3 el error se solucionó; ¡la última porción de código no funcionaría sin Python 3.x!
▶ Atributos de clase y de instancia
1.
class A: x = 1 class B(A): pass class C(A): pass
Output:
>>> A.x, B.x, C.x (1, 1, 1) >>> B.x = 2 >>> A.x, B.x, C.x (1, 2, 1) >>> A.x = 3 >>> A.x, B.x, C.x # C.x cambió, pero B.x no (3, 2, 3) >>> a = A() >>> a.x, A.x (3, 3) >>> a.x += 1 >>> a.x, A.x (4, 3)
2.
class SomeClass: some_var = 15 some_list = [5] another_list = [5] def __init__(self, x): self.some_var = x + 1 self.some_list = self.some_list + [x] self.another_list += [x]
Output:
>>> some_obj = SomeClass(420) >>> some_obj.some_list [5, 420] >>> some_obj.another_list [5, 420] >>> another_obj = SomeClass(111) >>> another_obj.some_list [5, 111] >>> another_obj.another_list [5, 420, 111] >>> another_obj.another_list is SomeClass.another_list True >>> another_obj.another_list is some_obj.another_list True
💡 Explicación:
- Las variables de clase y de instancia son controladas internamente como diccionarios de un objeto de clase. Si no se encuentra un nombre de variable en el diccionario de una clase, se busca en las clases padres.
- El operador
+=modifica el objeto mutable en el lugar, sin la necesidad de crear un nuevo objeto. Si se cambia el atributo de una instancia se afecta a los atributos de otras clases e instancias.
▶ Devolviendo None
some_iterable = ('a', 'b') def some_func(val): return "something"
Output (<= 3.7.x):
>>> [x for x in some_iterable] ['a', 'b'] >>> [(yield x) for x in some_iterable] <generator object <listcomp> at 0x7f70b0a4ad58> >>> list([(yield x) for x in some_iterable]) ['a', 'b'] >>> list((yield x) for x in some_iterable) ['a', None, 'b', None] >>> list(some_func((yield x)) for x in some_iterable) ['a', 'something', 'b', 'something']
💡 Explicación:
- Esto es un bug en la forma en que CPython maneja
yielden generadores y comprensiones. - Puedes encontrar el código fuente junto con una explicación aquí: https://stackoverflow.com/questions/32139885/yield-in-list-comprehensions-and-generator-expressions
- Reporte de bug relacionado: https://bugs.python.org/issue10544
- Python 3.8+ ya no acepta
yielddentro de comprensiones de listas, por lo que devolveráSyntaxError.
▶ ¡Usando yield desde return! *
1.
def some_func(x): if x == 3: return ["wtf"] else: yield from range(x)
Output (> 3.3):
>>> list(some_func(3)) []
¿A dónde se fue el "wtf"? ¿Está ocurriendo algún extraño efecto en yield from? Veamos,
2.
def some_func(x): if x == 3: return ["wtf"] else: for i in range(x): yield i
Output:
>>> list(some_func(3)) []
Mismo resultado. Tampoco funcionó.
💡 Explicación:
- Desde Python 3.3 en adelante es posible usar
returncon valores dentro de generadores (ve el PEP380). En la documentación oficial se escribe que,
"...
return expren un generador devuelveStopIteration(expr)al final del generador."
-
En el caso de
some_func(3), se devuelveStopIterational principio debido a la declaraciónreturn. La excepciónStopIterationse guarda automáticamente dentro delist(...)y el buclefor. Por lo tanto, las dos porciones de código de arriba resultan en una lista vacía. -
Para obtener
["wtf"]del generadorsome_funcnecesitamos tomar la excepciónStopIteration,try: next(some_func(3)) except StopIteration as e: some_string = e.value
▶ Reflexividad NAN *
1.
a = float('inf') b = float('nan') c = float('-iNf') # Estos strings no distinguen entre minúsculas y mayúsculas d = float('nan')
Output:
>>> a inf >>> b nan >>> c -inf >>> float('some_other_string') ValueError: could not convert string to float: some_other_string >>> a == -c # inf == inf True >>> None == None # None == None True >>> b == d # pero nan != nan False >>> 50 / a 0.0 >>> a / a nan >>> 23 + b nan
2.
>>> x = float('nan') >>> y = x / x >>> y is y # identidad True >>> y == y # equidad False >>> [y] == [y] # pero la equidad es verdadera cuando "y" está en una lista True
💡 Explicación:
-
'inf'y'nan'son strings especiales (sin distinguir entre minúsculas y mayúsculas), lo cual, cuando se convierte explícitamente a tipofloat, se utiliza para representar el "infinito" y "no un número (NAN)" en matemática. -
Según los estándares IEEE
NaN != NaN, seguir esta regla rompe la suposición de reflexividad de una colección de elementos en Python (por ejemplo, sixes parte de una colecciónlist, las implementaciones como comparación están basadas en la suposiciónx == x). Debido a esta suposición, primero se compara la identidad (al ser más rápida) a la vez que se comparan los dos elementos y los valores comparadas cuando las identidades no son iguales. La siguiente porción de código hará las cosas más fáciles de entender,>>> x = float('nan') >>> x == x, [x] == [x] (False, True) >>> y = float('nan') >>> y == y, [y] == [y] (False, True) >>> x == y, [x] == [y] (False, False)
Como las identidades de
xyyson diferentes, los valores son considerados diferentes. Esta compración devuelveFalse. -
Un artículo interesante para leer: "Reflexivity, and other pillars of civilization"
▶ ¡Mutando lo inmutable!
Esto puede parecerte trivial si sabes cómo funcionan las referencias en Python.
some_tuple = ("A", "tuple", "with", "values") another_tuple = ([1, 2], [3, 4], [5, 6])
Output:
>>> some_tuple[2] = "change this" TypeError: 'tuple' object does not support item assignment >>> another_tuple[2].append(1000) # Esto no devuelve error >>> another_tuple ([1, 2], [3, 4], [5, 6, 1000]) >>> another_tuple[2] += [99, 999] TypeError: 'tuple' object does not support item assignment >>> another_tuple ([1, 2], [3, 4], [5, 6, 1000, 99, 999])
Pero, pensé que los tuples eran inmutables...
💡 Explicación:
-
Según https://docs.python.org/3/reference/datamodel.html
Secuencias inmutables: un objeto no puede cambiar en una secuencia inmutable luego de ser creado (si el objeto hace referencia a otros objetos estos otros objetos pueden ser mutables y pueden ser cambiados; sin embargo, la colección de objetos a la que se hace referencia directamente por un objeto inmutable no puede cambiar).
-
El operador
+=cambia la lista en el lugar. No puedes cambiar un valor con la asignación de elementos, pero cuando la excepción ocurre el elemento ya ha sido cambiado en el lugar. -
Hay una explicación sobre esto en las preguntas frecuentes de Python.
▶ La variable de alcance exterior que desaparece
e = 7 try: raise Exception() except Exception as e: pass
Output (Python 2.x):
>>> print(e) # no devuelve nada
Output (Python 3.x):
>>> print(e) NameError: name 'e' is not defined
💡 Explicación:
-
Fuente: https://docs.python.org/3/reference/compound_stmts.html#except
Cuando se asigna una excepción utilizando
as, es borrada al final de la cláusulaexcept. Esto es,se traduce en
except E as N: try: foo finally: del N
Esto quiere decir que la excepción debe ser asignada a un nombre diferente para poder hacerle referencia luego de la cláusula de excepción. Las excepciones son borradas porque forman un ciclo de referencias haciendo que todos los locales en el código estén disponibles hasta que ocurra la siguiente colleción.
-
Las cláusulas no tienen alcance en Python. Todo en el ejemplo está en el mismo alcance y se eliminó la variable
edebido a la ejecución de la cláusulaexcept. Esto no ocurre en funciones que tienen alcances interiores separados. El siguiente ejemplo muestra este caso:def f(x): del(x) print(x) x = 5 y = [5, 4, 3]
Output:
>>>f(x) UnboundLocalError: local variable 'x' referenced before assignment >>>f(y) UnboundLocalError: local variable 'x' referenced before assignment >>> x 5 >>> y [5, 4, 3]
-
En Python 2.x el nombre de variable
ees asignado a la instanciaException(), por lo que, cuando se intenta devolver el valor, esto no ocurre.Output (Python 2.x):
>>> e Exception() >>> print e # Nothing is printed!
▶ La misteriosa conversión de la llave
class SomeClass(str): pass some_dict = {'s': 42}
Output:
>>> type(list(some_dict.keys())[0]) str >>> s = SomeClass('s') >>> some_dict[s] = 40 >>> some_dict # Se esparaban dos pares de valores diferentes {'s': 40} >>> type(list(some_dict.keys())[0]) str
💡 Explicación:
-
Ambos objetos
sy"s"hacen referencia al mismo valor porqueSomeClassherede del método__hash__de la clasestr. -
SomeClass("s") == "s"devuelveTrueporqueSomeClasstambién hereda del método__eq__de la clasestr. -
Ya que ambos objetos hacen referencia al mismo valor y son iguales, son presentados con la misma llave en el diccionario.
-
Para obtener el comportamiento deseado podemos redefinir el método
__eq__enSomeClassclass SomeClass(str): def __eq__(self, other): return ( type(self) is SomeClass and type(other) is SomeClass and super().__eq__(other) ) # Cuando definimos el método __eq__ por nuestra cuenta Python deja de heredar # automáticamente el método __hash__, por lo cual necesitamos redefinir este método también __hash__ = str.__hash__ some_dict = {'s':42}
Output:
>>> s = SomeClass('s') >>> some_dict[s] = 40 >>> some_dict {'s': 40, 's': 42} >>> keys = list(some_dict.keys()) >>> type(keys[0]), type(keys[1]) (__main__.SomeClass, str)
▶ Veamos si puedes adivinar esto...
Output:
💡 Explicación:
-
Según la referencia de lenguaje de Python, las declaraciones de asignación tienen la forma
(target_list "=")+ (expression_list | yield_expression)
Una declaración de asignación evalúa la lista (recuerda que esta puede ser de solo una expresión o tener valores separados por comas, este último devolviendo un tuple) y asigna el objeto único de cada lista, de izquierda a derecha.
-
El símbolo
+en(target_list "=")+significa que pueden haber una o más listas. En este caso, las listas sona, bya[b](date cuenta que solo hay una expresión; en nuestro caso,{}, 5). -
Luego de que la expresión es evaluada su valor se desempaqueta a las listas de izquierda a derecha. En nuestro caso, el tuple
{}, 5es desempaquetado aa, b. Ahora, tenemosa = {}yb = 5. -
ase asigna a{}, el cual es un objeto mutable. -
La segunda lista es
a[b](tal vez pensabas que esto devolvería un error ya que ambasaybno han sido definidas en las declaraciones anteriores. Pero recuerda, acabamos de asignaraa{}yba5). -
Ahora estamos asignando la llave
5del diccionario al tuple({}, 5), formando una referencia cíclica ({...}en el output hace referencia al mismo objeto al queahace referencia). Otro simple ejemplo de una referencia cíclica podría ser,>>> some_list = some_list[0] = [0] >>> some_list [[...]] >>> some_list[0] [[...]] >>> some_list is some_list[0] True >>> some_list[0][0][0][0][0][0] == some_list True
El caso de nuestro ejemplo es similar:
a[b][0]es el mismo objeto quea) -
Para resumir, puedes separar el ejemplo de abajo de esta manera:
Y la referencia cíclica es justificada porque
a[b][0]es el mismo objeto quea.
Sección: pendientes resbaladizas
▶ Modificando un diccionario a la vez que iteramos por él
x = {0: None} for i in x: del x[i] x[i+1] = None print(i)
Output (Python 2.7- Python 3.5):
Si, es ejecutado exactamente ocho veces antes de detenerse.
💡 Explicación:
- Iterar por un diccionario al mismo tiempo que lo editas no es soportado.
- Es ejecutado exactamente ocho veces porque ese es el punto en el que el diccionario cambia su tamaño para almacenar más llaves (tenemos ocho entradas de eliminación, por lo cual se necesita cambiar el tamaño). Este es un detalle en la implementación.
- La forma en la que las llaves borradas son manejadas y cuándo ocurre en cambio de tamaño difiere dependiendo de las implementaciones de Python
- En versiones de Python que no sean la 2.7 o 3.5, la cuenta puede ser diferente a 8 (aunque, sea cual sea la cuenta, será la misma cada vez que ejecutes el código). Puedes encontrar una discución sobre esto aquí o en esta pregunta de StackOverflow.
- Desde Python 3.7.6 en adelante verás la excepción
RuntimeError: dictionary keys changed during iterationsi intentas hacer esto.
▶ El rebelde operador del
class SomeClass: def __del__(self): print("Deleted!")
Output: 1.
>>> x = SomeClass() >>> y = x >>> del x # debería imprimir "Deleted!" >>> del y Deleted!
Al final si devolvió eso. Seguramente adivinaste qué hizo que __del__ no fuera llamado en nuestro primer intento de borrar x. Añadémosle más complejidad al asunto.
2.
>>> x = SomeClass() >>> y = x >>> del x >>> y # revisa si "y" existe <__main__.SomeClass instance at 0x7f98a1a67fc8> >>> del y # Al igual que antes, esto debería imprimir "Deleted!" >>> globals() # Uh, parece que no fue así... Veamos nuestras variables globales para confirmar Deleted! {'__builtins__': <module '__builtin__' (built-in)>, 'SomeClass': <class __main__.SomeClass at 0x7f98a1a5f668>, '__package__': None, '__name__': '__main__', '__doc__': None}
Ahora sí está eliminada... 😕
💡 Explicación:
del xno llama directamentex.__del__().- Cuando Python encuentra
del xborra el nombrexdel alcance actual y decrementa por 1 la cuenta del objetox.__del__()es llamada solo cuando la cuenta del objeto llega a cero. - En el output de la segunda porción de código,
__del__()no fue llamada porque la declaración previa (>>> y) en el intérprete interactivo creó otra referencia al mismo objeto (específicamente, la variable mágica_que hace referencia al valor de la última expresión que no esNone), lo cual prevee que la cuenta no llegue a cero cuando Python se encuentra condel y. - Al llamar
globals(o, realmente, al llamar cualquier cosa que no devuelvaNone) hace que_haga referencia al nuevo resultado, descartando la referencia existente. La cuenta finalmente llegó a 0 y podemos ver "Deleted!" impreso en la terminal.
▶ La variable fuera de alcance
1.
a = 1 def some_func(): return a def another_func(): a += 1 return a
2.
def some_closure_func(): a = 1 def some_inner_func(): return a return some_inner_func() def another_closure_func(): a = 1 def another_inner_func(): a += 1 return a return another_inner_func()
Output:
>>> some_func() 1 >>> another_func() UnboundLocalError: local variable 'a' referenced before assignment >>> some_closure_func() 1 >>> another_closure_func() UnboundLocalError: local variable 'a' referenced before assignment
💡 Explicación:
-
Cuando asignas una variable en un alcance esta se vuelve de alcance local.
aes local según el alcance deanother_func, pero no ha sido inicializada previamente en el mismo alcance, devolviendo un error. -
Para modificar la variable
ade alcance exterior enanother_func, tenemos que usar la palabra reservadaglobal.def another_func() global a a += 1 return a
Output:
-
En
another_closure_func,ase vuelve local según el alcance deanother_inner_func, pero no ha sido inicializada previamente en el mismo alcance, devolviendo un error. -
Para modificar la variable
ade alcance exterior enanother_inner_func, usa la palabra reservadanonlocal. La declaraciónnonlocales utilizada para hacer referencia a variables definidas en el alcance exterior más cercano (exluyendo el alcance global).def another_func(): a = 1 def another_inner_func(): nonlocal a a += 1 return a return another_inner_func()
Output:
-
Las palabras reservadas
globalynonlocalle dicen al intérprete de Python que no declare nuevas variables y que las busque en el alcance exterior. -
Lee esta corta pero increíble guía para aprender más sobre cómo funcionan los namespaces y las resoluciones de alcance en Python.
▶ Borrar un elemento de una lista al iterar sobre ella
list_1 = [1, 2, 3, 4] list_2 = [1, 2, 3, 4] list_3 = [1, 2, 3, 4] list_4 = [1, 2, 3, 4] for idx, item in enumerate(list_1): del item for idx, item in enumerate(list_2): list_2.remove(item) for idx, item in enumerate(list_3[:]): list_3.remove(item) for idx, item in enumerate(list_4): list_4.pop(idx)
Output:
>>> list_1 [1, 2, 3, 4] >>> list_2 [2, 4] >>> list_3 [] >>> list_4 [2, 4]
¿Puedes determinar por qué el output es [2, 4]?
💡 Explicación:
-
Nunca es una buena idea cambiar el objeto mientras estás iterando sobre él. La forma correcta de hacerlo es iterar sobre una copia del objeto.
list_3[:]hace esto.>>> some_list = [1, 2, 3, 4] >>> id(some_list) 139798789457608 >>> id(some_list[:]) # Notice that python creates new object for sliced list. 139798779601192
Diferencia entre del, remove y pop:
del var_nameremuevevar_namedel namespace local o global (es por esto quelist_1no es afectada).removeremueve el primer valor que coincide, no un index específico. DevuelveValueErrorsi no se encuentra el valor.popremueve el elemento en un index específico y lo devuelve. Si un index inválido es especificado, devuelveIndexError.
¿Por qué el output es [2, 4]?
- La iteración sobre la lista ocurre index por index. Cuando se remueve
1delist_2olist_4, los contenidos de las listas cambian a[2, 3, 4]. Los elementos restantes se mueven un espacio atrás (2al index 0 y3al index 1). Ya que la siguiente iteración buscará por el index 1 (valor3) se salta el valor2. Algo similar ocurre en una secuencia alterna sobre una lista.
- Puedes ir a esta pregunta de StackOverflow para ver un ejemplo.
- También, puedes ir a esta otra pregunta de StackOverflow para ver un ejemplo relacionado a los diccionarios en Python.
▶ Pérdidas en los iteradores *
>>> numbers = list(range(7)) >>> numbers [0, 1, 2, 3, 4, 5, 6] >>> first_three, remaining = numbers[:3], numbers[3:] >>> first_three, remaining ([0, 1, 2], [3, 4, 5, 6]) >>> numbers_iter = iter(numbers) >>> list(zip(numbers_iter, first_three)) [(0, 0), (1, 1), (2, 2)] # so far so good, let's zip the remaining >>> list(zip(numbers_iter, remaining)) [(4, 3), (5, 4), (6, 5)]
¿A dónde fue el elemento 3 de la lista numbers?
💡 Explicación:
-
Según la documentación de Python, esta es una implementación aproximada a la función "zip",
def zip(*iterables): sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)
-
La función toma un número arbitrario de iterables, añade cada uno de sus elementos a la lista
resultal llamar a la funciónnexty se detiene cuando un iterable está exhausto. -
El problema en todo esto es cuando un iterable está exhausto: los elementos de la lista
resultson descartados. Eso es lo que ocurrió con3ennumbers_iter. -
La manera correcta de hacer lo de la porción de código de arriba utilizando la función
zipsería,>>> numbers = list(range(7)) >>> numbers_iter = iter(numbers) >>> list(zip(first_three, numbers_iter)) [(0, 0), (1, 1), (2, 2)] >>> list(zip(remaining, numbers_iter)) [(3, 3), (4, 4), (5, 5), (6, 6)]
El primer argumento de zip debería ser el que tiene menos elementos.
▶ ¡Fuga de variables en bucles!
1.
for x in range(7): if x == 6: print(x, ': for x inside loop') print(x, ': x in global')
Output:
6 : for x inside loop 6 : x in global
Pero... nunca se definió x fuera del alcance del bucle...
2.
# Esta vez vamos a inicializar "x" primero x = -1 for x in range(7): if x == 6: print(x, ': for x inside loop') print(x, ': x in global')
Output:
6 : for x inside loop 6 : x in global
3.
Output (Python 2.x):
>>> x = 1 >>> print([x for x in range(5)]) [0, 1, 2, 3, 4] >>> print(x) 4
Output (Python 3.x):
>>> x = 1 >>> print([x for x in range(5)]) [0, 1, 2, 3, 4] >>> print(x) 1
💡 Explicación:
-
En Python, los bucles "for" usan el alcance en el que están y dejan la variable dentro de ellos atrás. Sería lo mismo si aplicásemos explícitamente la variable del bucle en el namespace global. En este caso, volverá a enlazar la variable existente.
-
Las diferencias entre los intérpretes de Python 2.x y 3.x en relación a las comprensiones de listas son explicadas en el documento "What's New In Python 3.0". Citando el documento:
"Las comprensiones de listas ya no soportan la sintaxis
[... fir var in item1, item2, ...]. Utiliza[... for var in (item1, item2, ...)]. Además, ten en cuenta que las comprensiones de listas tienen una semántica diferente: son como funcionalidades extra para un generador dentro de un constructorlist()y, en particular, el bucle controla que las variables no se fuguen en el siguiente alcance."
▶ ¡Ten cuidado con los argumentos mutables predeterminados!
def some_func(default_arg=[]): default_arg.append("some_string") return default_arg
Output:
>>> some_func() ['some_string'] >>> some_func() ['some_string', 'some_string'] >>> some_func([]) ['some_string'] >>> some_func() ['some_string', 'some_string', 'some_string']
💡 Explicación:
-
Los argumentos mutables predeterminados de funciones no son inicializados cada vez que llamas a la función. En vez de ese comportamiento, el valor asignado más reciente es utilizado como el valor predeterminado. Cuando pasamos explícitamente
[]asome_funccomo argumento, el valor predeterminado de la variabledefault_argno se utilizó, por lo que la función devolvió lo esperado.def some_func(default_arg=[]): default_arg.append("some_string") return default_arg
Output:
>>> some_func.__defaults__ # Estó imprimirá los valores de los argumentos predeterminados de la función ([],) >>> some_func() >>> some_func.__defaults__ (['some_string'],) >>> some_func() >>> some_func.__defaults__ (['some_string', 'some_string'],) >>> some_func([]) >>> some_func.__defaults__ (['some_string', 'some_string'],)
-
Una práctica común para evitar errores de argumentos mutables es asignar
Nonecomo valor predeterminado y luego revisar si algún valor corresponde al valor pasado a la función. Ejemplo:def some_func(default_arg=None): if default_arg is None: default_arg = [] default_arg.append("some_string") return default_arg
▶ Detectando las excepciones
some_list = [1, 2, 3] try: # Esto debería devolver ``IndexError`` print(some_list[4]) except IndexError, ValueError: print("Caught!") try: # Esto debería devolver ``ValueError`` some_list.remove(4) except IndexError, ValueError: print("Caught again!")
Output (Python 2.x):
Caught! ValueError: list.remove(x): x not in list
Output (Python 3.x):
File "<input>", line 3 except IndexError, ValueError: ^ SyntaxError: invalid syntax
💡 Explicación:
-
Para añadir varias excepciones a la cláusula "except" necesitas pasarlas dentro de un tuple como el primer argumento. El segundo argumento es un nombre opcional que enlazará la instancia de la excepción que ha sido devuelta. Por ejemplo,
some_list = [1, 2, 3] try: # Esto debería devolver ``ValueError`` some_list.remove(4) except (IndexError, ValueError), e: print("Caught again!") print(e)
Output (Python 2.x):
Caught again! list.remove(x): x not in listOutput (Python 3.x):
File "<input>", line 4 except (IndexError, ValueError), e: ^ IndentationError: unindent does not match any outer indentation level
-
La práctica de separar la excepción de la variable con una coma ya no está en uso y no funciona en Python3; la forma correcta de hacerlo es usar
as. Por ejemplo,some_list = [1, 2, 3] try: some_list.remove(4) except (IndexError, ValueError) as e: print("Caught again!") print(e)
Output:
Caught again! list.remove(x): x not in list
▶ ¡Mismos operandos, cuestiones diferentes!
1.
a = [1, 2, 3, 4] b = a a = a + [5, 6, 7, 8]
Output:
>>> a [1, 2, 3, 4, 5, 6, 7, 8] >>> b [1, 2, 3, 4]
2.
a = [1, 2, 3, 4] b = a a += [5, 6, 7, 8]
Output:
>>> a [1, 2, 3, 4, 5, 6, 7, 8] >>> b [1, 2, 3, 4, 5, 6, 7, 8]
💡 Explicación:
-
a += bno siempre se comporta igual quea = a + b. Las clases podrían implementar los operadoresop=de una manera diferente, al igual que lo hacen las listas. -
La expresión
a = a + [5,6,7,8]genera una nueva lista y asigna la referencia deaa esa nueva lista, dejando absin modificar. -
La expresión
a += [5,6,7,8]es asignada a una función "extendida" que opera en la lista haciendo queaybhagan referencia a la misma lista que ha sido modificada en el lugar.
▶ Resolución de nombres ignorando el alcance de la clase
1.
x = 5 class SomeClass: x = 17 y = (x for i in range(10))
Output:
>>> list(SomeClass.y)[0] 5
2.
x = 5 class SomeClass: x = 17 y = [x for i in range(10)]
Output (Python 2.x):
Output (Python 3.x):
💡 Explicación:
- El alcance dentro de una definición de una clase ignora los nombres en ese nivel.
- Un generador tiene su propio alcance.
- Desde Python 3.x, las comprensiones de listas también tienen su propio alcance.
▶ Agujas en un pajar *
Hasta ahora no he conocido a ningún Pythonista experimentado que no se haya encontrado con los siguientes panoramas,
1.
x, y = (0, 1) if True else None, None
Output:
>>> x, y # se espera (0, 1) ((0, 1), None)
2.
t = ('one', 'two') for i in t: print(i) t = ('one') for i in t: print(i) t = () print(t)
Output:
3.
ten_words_list = [
"some",
"very",
"big",
"list",
"that"
"consists",
"of",
"exactly",
"ten",
"words"
]
Output
>>> len(ten_words_list) 9
4. No se afirma con suficiente determinación
a = "python" b = "javascript"
Output:
# Una declaración "assert" con un mensaje de error. >>> assert(a == b, "Both languages are different") # No se devuelve ningún error "AssertionError".
5.
some_list = [1, 2, 3] some_dict = { "key_1": 1, "key_2": 2, "key_3": 3 } some_list = some_list.append(4) some_dict = some_dict.update({"key_4": 4})
Output:
>>> print(some_list) None >>> print(some_dict) None
6.
def some_recursive_func(a): if a[0] == 0: return a[0] -= 1 some_recursive_func(a) return a def similar_recursive_func(a): if a == 0: return a a -= 1 similar_recursive_func(a) return a
Output:
>>> some_recursive_func([5, 0]) [0, 0] >>> similar_recursive_func(5) 4
💡 Explicación:
-
Para 1, la declaración correcta según el comportamiento esperado es
x, y = (0, 1) is True else (None, None). -
Para 2, la declaración correcta según el comportamiento esperado es
t = ('one',)ort = 'one',(le falta una coma). Si no, el intérprete considera atcomo unstre itera sobre el caracter por caracter. -
()son caracteres especiales denotados por untuplevacío. -
Para 3, como seguramente ya hayas imaginado, falta una coma luego del quinto elemento (
"that") en la lista. Podemos ejecutar una concatenación de strings,>>> ten_words_list ['some', 'very', 'big', 'list', 'thatconsists', 'of', 'exactly', 'ten', 'words']
-
No se devuelve ningún error
AssertionErroren la cuarta porción de código porque en vez de afirmar la expresión individuala == b, estamos afirmando un tuple entero. La siguiente porción de código hará las cosas más claras,>>> a = "python" >>> b = "javascript" >>> assert a == b Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError >>> assert (a == b, "Values are not equal") <stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses? >>> assert a == b, "Values are not equal" Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: Values are not equal
-
En la quinta porción de código la mayoría de los métodos que modifican los elementos en una secuencia (como
list.append,dict.update,list.sort, etc.) modifican los objetos en el lugar y devuelvenNone. La lógica detrás de esto es que así se mejora el rendimiento al evitar tener que crear una copia del objeto ya que la operación puede ejecutarse en el lugar (referencia aquí). -
El último es bastante obvio: los objetos mutables (como
list) pueden ser alterados en la función y la reasignación de un inmutable (a -= 1) no es una alteración del valor. -
Estar pendiente de estos comportamientos puede ayudarte a salvar horas y esfuerzo a la hora de hacer debug.
▶ Separando valores *
>>> 'a'.split() ['a'] # is same as >>> 'a'.split(' ') ['a'] # but >>> len(''.split()) 0 # isn't the same as >>> len(''.split(' ')) 1
💡 Explicación:
-
Al principio puede parecer que el separador predeterminado de
splites un espacio' ', pero, segpun la documentación:Si "sep" no es especificado o es
Nonese utiliza un algoritmo diferente a la hora de separar: las series de espacios en blanco consecutivos son consideradas como un separador único y el resultado contendrá strings no vacíos al comienzo o al final si el string tiene espacios en blanco al comienzo o al final. Consecuentemente, al separar un string vacío o un string que consiste solo de espacios en blanco con un separadorNonedevuelve[]. Si "sep" es pasado, los delimitadores consecutivos no son agrupados y son considerados como delimitadores de strings vacíos (por ejemplo,'1,,2.split(',') devuelve['1', '', '2']). Separar un string con un separador especificado devuelve['']. -
Ver cómo los espacios en blanco al comienzo y al final son manejados en la siguiente porción de código hace las cosas más fáciles de entender,
>>> ' a '.split(' ') ['', 'a', ''] >>> ' a '.split() ['a'] >>> ''.split(' ') ['']
▶ Importes "wild" *
# File: module.py def some_weird_name_func_(): print("works!") def _another_weird_name_func(): print("works!")
Output
>>> from module import * >>> some_weird_name_func_() "works!" >>> _another_weird_name_func() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name '_another_weird_name_func' is not defined
💡 Explicación:
-
A menudo se acoseja no utilizar importes salvajes. La primera razón (y la más obvia) es que en los importes salvajes los nombres con un piso bajo al principio no son importados. Esto puede acarrear algunos errores en la ejecución.
-
Si hubiésemos usado
from ... import a, b, c, el errorNameErrorno hubiese ocurrido.>>> from module import some_weird_name_func_, _another_weird_name_func >>> _another_weird_name_func() works!
-
Si realmente quieres usar importes salvajes tendrás que definir una lista
__all__en tu módulo que contendrá una lista de objetos públicos disponibles a la hora de importar de manera salvaje.__all__ = ['_another_weird_name_func'] def some_weird_name_func_(): print("works!") def _another_weird_name_func(): print("works!")
Output
>>> _another_weird_name_func() "works!" >>> some_weird_name_func_() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'some_weird_name_func_' is not defined
▶ ¿Todo ordenado? *
>>> x = 7, 8, 9 >>> sorted(x) == x False >>> sorted(x) == sorted(x) True >>> y = reversed(x) >>> sorted(y) == sorted(y) False
💡 Explicación:
-
El método
sortedsiempre devuelve una lista y, al comparar listas con tuples, el resultado es siempreFalseen Python -
>>> [] == tuple() False >>> x = 7, 8, 9 >>> type(x), type(sorted(x)) (tuple, list)
-
A diferencia del método
sorted, el métodoreverseddevuelve un iterador. ¿Por qué? porque para ordenarla el iterador necesita ser modificado en el lugar o usar un contenedor (lista) extra, mientras que para revertir el orden de los elementos simplemente se necesita iterar desde el último index hasta el primero. -
Durante la comparación
sorted(y) == sorted(y)cuando se llama por primera vezsorted()se consume el iteradoryy cuando se llama por segunda vez devolverá una lista vacía.>>> x = 7, 8, 9 >>> y = reversed(x) >>> sorted(y), sorted(y) ([7, 8, 9], [])
▶ ¿No existe la medianoche?
from datetime import datetime midnight = datetime(2018, 1, 1, 0, 0) midnight_time = midnight.time() noon = datetime(2018, 1, 1, 12, 0) noon_time = noon.time() if midnight_time: print("Time at midnight is", midnight_time) if noon_time: print("Time at noon is", noon_time)
Output (< 3.5):
('Time at noon is', datetime.time(12, 0))
No se ha impreso en pantalla el tiempo de medianoche.
💡 Explicación:
Antes de Python 3.5 el valor boolean del objeto datetime.time era considerado False si representaba la medianoche en la zona horaria UTC. Pueden haber errores al usar if obj: para revisar si obj es nulo o algún otro valor equivalente (vacío).
Sección: ¡tesoros ocultos!
Esta sección contiene cosas menos populares pero interesantes sobre Python que la mayoría de los principiantes como yo no sabemos (bueno, ahora las sabremos 😁).
▶ Python, ¿puedes hacerme volar?
Well, here you go
Output: Sshh... It's a super-secret.
💡 Explicación:
- El módulo
antigravityes un easter-egg colocado por los desarrolladores de Python. import antigravityabre una ventana en el navegador que muestra un clásico cómic XKCD sobre Python.- Bueno, en realidad hay más sobre esto. Hay otro easter-egg dentro del easter-egg. Si ves el código notarás que hay una función definida que pretender implementar el algoritmo "geohashing" de XKCD.
▶ goto, pero, ¿por qué?
from goto import goto, label for i in range(9): for j in range(9): for k in range(9): print("I am trapped, please rescue!") if k == 2: goto .breakout # rompiendo el bucle profundo label .breakout print("Freedom!")
Output (Python 2.3):
I am trapped, please rescue! I am trapped, please rescue! Freedom!
💡 Explicación:
- Se anunció una versión funcional de
gotoen Python como una broma de los inocentes el 1 de Abril de 2004. - Las versiones actuales de Python no tienen este módulo.
- A pesar de que funciona, por favor, no lo uses. Hay una razón por la cual el módulo
gotoya no está en Python.
▶ ¡Prepárate!
Si eres una de las personas a las que no le gusta usar espacios en blanco en Python para definir alcances, puedes usar {} (como en C) para importar,
from __future__ import braces
Output:
File "some_file.py", line 1 from __future__ import braces SyntaxError: not a chance
¿Llaves? ¡Imposible! Si crees que eso es decepcionante, usa Java. Hay otra cosa impresionante: ¿puedes encontrar dónde está SyntaxError definido en el módulo __future__ código?
💡 Explicación:
- El módulo
__future__es usado normalmente para hacer que las futuras características de Python estén disponibles. Sin embargo, la palabra "future (futuro)" en este contexto es irónica. - Este es un easter-egg relacionado con los sentimientos de la comunidad sobre este tema.
- Puedes encontrar el código aquí, en el archivo
future.c. - Cuando el compilador de CPython encuentra una declaración futura primero ejecuta el código apropiado de
future.cantes de tratarlo como una declaración de importe común.
▶ Conozcamos a Lenguaje Amistoso, tío de por vida
Output (Python 3.x)
>>> from __future__ import barry_as_FLUFL >>> "Ruby" != "Python" # there's no doubt about it File "some_file.py", line 1 "Ruby" != "Python" ^ SyntaxError: invalid syntax >>> "Ruby" <> "Python" True
Ahí vamos.
💡 Explicación:
-
Esto tiene relación al PEP-401, lanzado el 1 de Abril de 2009 (ahora sabes qué significa).
-
Citando el PEP-401:
Reconociendo que el operador "!=" de inequidad en Python 3.0 era un error horrible, FLUFL dicta el uso del operador "diamante (<>)" como la manera de escribirlo.
-
Hay más cosas que Uncle Barry compartió en este PEP, las cuales puedes leer aquí.
-
Funciona bien en un ambiente interactivo, pero devolverá
SyntaxErrorsi lo ejecutas a través de un archivo de Python (ve este Issue). Sin embargo, puedes envolver la declaración dentro deevalocompilepara hacer que funcione,from __future__ import barry_as_FLUFL print(eval('"Ruby" <> "Python"'))
▶ Incluso Python sabe que el amor es complicado
Espera, ¿qué es "this"? this es amor ❤️
Output:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
¡Es el Zen de Python!
>>> love = this >>> this is love True >>> love is True False >>> love is False False >>> love is not True or False True >>> love is not True or False; love is love # El amor es complicado True
💡 Explicación:
- El módulo
thises un easter-egg en Python que corresponde al Zen de Python (PEP-20). - Y si crees que eso es interesante, ve la implementación de this.py. Curiosamente, el código del Zen se infringe a sí mismo (y ese es probablemente el único lugar en donde esto ocurre).
- Según la declaración
love is not True or False; love is love, irónicamente, se explica a sí misma (si no lo entiendes, por favor ve los ejemplos relacionados a los operadoresisynot).
▶ ¡Si, existe!
La cláusula else para bucles. Un ejemplo típico podría ser:
def does_exists_num(l, to_find): for num in l: if num == to_find: print("Exists!") break else: print("Does not exist")
Output:
>>> some_list = [1, 2, 3, 4, 5] >>> does_exists_num(some_list, 4) Exists! >>> does_exists_num(some_list, -1) Does not exist
** La cláusula else manejando una excepción.** Por ejemplo:
try: pass except: print("Exception occurred!!!") else: print("Try block executed successfully...")
Output:
Try block executed successfully...
💡 Explicación:
- La cláusula
elseluego de un bucle es ejecutada solo cuando no hay unbreakexplícito luego de las iteraciones. Una manera de verlo es como si fuera una cláusula "nobreak". - La cláusula
elseluego de un bloquetrytambién es llamada "cláusula de finalización" ya que llegar a la cláusulaelseen una declaracióntrysignifica que el bloquetryse completó satisfactoriamente.
▶ Elipsis *
def some_func(): Ellipsis
Output
>>> some_func() # Sin output, sin errores >>> SomeRandomString Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'SomeRandomString' is not defined >>> Ellipsis Ellipsis
💡 Explicación:
-
En Python,
Ellipsises un objeto interno disponible globalmente, equivalente a.... -
Las elipsis pueden ser utilizadas para diferentes propósitos,
-
Para llenar el código que todavía no se ha escrito (al igual que la declaración
pass). -
Al partir un iterable para representar todos los elementos en la dirección restante.
>>> import numpy as np >>> three_dimensional_array = np.arange(8).reshape(2, 2, 2) array([ [ [0, 1], [2, 3] ], [ [4, 5], [6, 7] ] ])
three_dimensional_arrayes un array que consiste en otro array con otros arrays. Imaginemos que queremos imprimir el segundo elemento (con index1) de todos los arrays internos. Para esto, podemos utilizar "Ellipsis" para saltar todas las dimensiones anteriores.>>> three_dimensional_array[:,:,1] array([[1, 3], [5, 7]]) >>> three_dimensional_array[..., 1] # using Ellipsis. array([[1, 3], [5, 7]])
Nota: esto funcionará para cualquier número de dimensiones. Puedes incluso, seleccionar la partición en la primera y última dimensión e ignorar las del medio haciendo lo siguiente: (
n_dimensional_array[firs_dim_slice, ..., last_dim_slice]). -
Puedes usarlo en alias de tipo para indicar solo una parte del tipo (como
(Callable[..., int]orTuple[str, ...])). -
También puedes usarlo como un argumento predeterminado de una función (en casos en los que quieras diferenciar entre "ningún argumento pasado" y "valor
Nonepasado).
▶ "Inpinity"
La falta ortográfica es a propósito. Por favor, no lo edites.
Output (Python 3.x):
>>> infinity = float('infinity') >>> hash(infinity) 314159 >>> hash(float('-inf')) -314159
💡 Explicación:
- El hash de infinito es 10⁵ x π.
- Curiosamente,
float('-inf')es "-10⁵ x π" en Python 3, mientras que en Python 2 es "-10⁵ x e".
▶ Vamos a mangonear
1.
class Yo(object): def __init__(self): self.__honey = True self.bro = True
Output:
>>> Yo().bro True >>> Yo().__honey AttributeError: 'Yo' object has no attribute '__honey' >>> Yo()._Yo__honey True
2.
class Yo(object): def __init__(self): # Intentemos algo simétrico esta vez self.__honey__ = True self.bro = True
Output:
>>> Yo().bro True >>> Yo()._Yo__honey__ Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Yo' object has no attribute '_Yo__honey__'
¿Por qué funcionó Yo()._Yo__honey?
3.
_A__variable = "Some value" class A(object): def some_func(self): return __variable # aun no se ha inicializado
Output:
>>> A().__variable Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'A' object has no attribute '__variable' >>> A().some_func() 'Some value'
💡 Explicación:
- "Name Mangling" se utiliza para evitar problemas de identificación entre namespaces diferentes.
- En Python, el intérprete modifica los nombres del miembro de la clase que comienzan con
__(dos pisos bajos, también llamado "dunder") y que no terminan con otros pisos bajos añadiendo_NameOfTheClassen frente. - Para acceder al atributo
__honeyde la primera porción de código, tuvimos que añadir__Yoal principio, lo cual previene errores si el mismo nombre del atributo está definido en otra clase. - Pero, entonces, ¿por qué no funcionó en la segunda porción de código? Porque este proceso ignora los nombres que terminan en pisos bajos.
- En la tercera porción de código también ocurre algo similar. El nombre
__variableen la declaraciónreturn __variablefue asignado a_A__variable, el cual es el mismo nombre de la variable que declaramos en el alcance exterior. - Además, si el nombre tiene más de 255 caracteres, éste se recortará.
Sección: ¡las apariencias engañan!
▶ ¿Saltando líneas?
Output:
>>> value = 11 >>> valuе = 32 >>> value 11
¿Qué?
Nota: La manera más fácil de reproducir esto es simplemente copiar las declaraciones de la porción de código de arriba y pegarlas en tu archivo/terminal.
💡 Explicación:
Algunos caracteres no occidentales se ven iguales a algunos en el alfabeto Inglés, pero el intérprete los considera distintos.
>>> ord('е') # 'e' cirílica (Ye) 1077 >>> ord('e') # 'e' latina, usada en Inglés e impresa usando un teclado estándar 101 >>> 'е' == 'e' False >>> value = 42 # 'e' latina >>> valuе = 23 # 'e' cirílica. El intérprete de Python 2.x devolverá `SyntaxError` en esta parte. >>> value 42
La función integrada ord() devuelve un punto de código de un caracter Unicode y posiciones diferentes de código para la 'e' cirílica y la 'e' latina, justificando así el comportamiento del ejemplo anterior.
▶ Teletransportación
# Primero, `pip install numpy`. import numpy as np def energy_send(x): # Inicializando un array numpy np.array([float(x)]) def energy_receive(): # Return an empty numpy array return np.empty((), dtype=np.float).tolist()
Output:
>>> energy_send(123.456) >>> energy_receive() 123.456
¿Dónde está el premio Nobel?
💡 Explicación:
- Ten en cuenta que el array numpy creado en la función
energy_sendno es devuelto, permitiendo que el espacio en memoria cambie libremente. numpy.empty()devuelve el siguiente espacio de memoria libre sin reinicializar. Este espacio en memoria es el mismo que acaba de ser liberado (usualmente, aunque no siempre).
▶ Hm... algo es sospechoso...
def square(x): """ A simple function to calculate the square of a number by addition. """ sum_so_far = 0 for counter in range(x): sum_so_far = sum_so_far + x return sum_so_far
Output (Python 2.x):
¿El resultado no debería ser "100"?
Nota: si no puedes reproducir este código intenta ejecutar el archivo "mixed_tabs_and_spaces.py" a través de la terminal.
💡 Explicación:
-
**¡No confundas los tabs con los espacios! El caracter que le precede a "return" es un "tab", y el código es indentado por un múltiplo de 4 espacios en el ejemplo.
-
Así es como Python controla las tabs:
Primero, las tabs son reemplazadas (de izquierda a derecha) de 1 a 8 espacios hasta que el número total de caracteres es un múltiplo de 8 ...
-
Entonces, "tab" en la última línea de la función
squarees reemplazada con ocho espacios, haciendo que pertenezca al bucle. -
Python 3 es lo suficientemente amable para devolver un error automáticamente en casos como estos,
Output (Python 3.x):
TabError: inconsistent use of tabs and spaces in indentation
Sección: varios
▶ += es más rápido
# Usando "+", tres strings: >>> timeit.timeit("s1 = s1 + s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100) 0.25748300552368164 # Usando "+=", tres strings: >>> timeit.timeit("s1 += s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100) 0.012188911437988281
💡 Explicación:
+=es más rápido que+para concatenar más de dos strings porque el primer string (por ejemplo,s1as1 += s2 + s3) no es eliminado cuando se calcula el string completo.
▶ ¡Hagamos un string super largo!
def add_string_with_plus(iters): s = "" for i in range(iters): s += "xyz" assert len(s) == 3*iters def add_bytes_with_plus(iters): s = b"" for i in range(iters): s += b"xyz" assert len(s) == 3*iters def add_string_with_format(iters): fs = "{}"*iters s = fs.format(*(["xyz"]*iters)) assert len(s) == 3*iters def add_string_with_join(iters): l = [] for i in range(iters): l.append("xyz") s = "".join(l) assert len(s) == 3*iters def convert_list_to_string(l, iters): s = "".join(l) assert len(s) == 3*iters
Output:
# Ejecutado en la terminal de Python usando %timeit para leer mejor los resultados. # También puedes usar el módulo timeit en una terminal de Python o en un archivo. Ejemplo más abajo. # timeit.timeit('add_string_with_plus(10000)', number=1000, globals=globals()) >>> NUM_ITERS = 1000 >>> %timeit -n1000 add_string_with_plus(NUM_ITERS) 124 µs ± 4.73 µs por loop (promedio ± std. dev. de 7 ejecuciones, 100 loops cada una) >>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS) 211 µs ± 10.5 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> %timeit -n1000 add_string_with_format(NUM_ITERS) 61 µs ± 2.18 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> %timeit -n1000 add_string_with_join(NUM_ITERS) 117 µs ± 3.21 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> l = ["xyz"]*NUM_ITERS >>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS) 10.1 µs ± 1.06 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops por cada una)
Aumentemos el número de iteraciones por factor 10.
>>> NUM_ITERS = 10000 >>> %timeit -n1000 add_string_with_plus(NUM_ITERS) # Incremento linear en el tiempo de ejecución 1.26 ms ± 76.8 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS) # Incremento cuadrático 6.82 ms ± 134 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> %timeit -n1000 add_string_with_format(NUM_ITERS) # Incremento linear 645 µs ± 24.5 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> %timeit -n1000 add_string_with_join(NUM_ITERS) # Incremento linear 1.17 ms ± 7.25 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loops cada una) >>> l = ["xyz"]*NUM_ITERS >>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS) # Incremento linear 86.3 µs ± 2 µs por loop (promedio ± std. dev. de 7 ejecuciones, 1000 loop cada una)
💡 Explicación:
-
Puedes leer más sobre timeit or %timeit en estos links. Son utilizados para calcular el tiempo de ejecución de una porción de código.
-
No uses
+para generar strings largos. En Python,stres inmutable, por lo que los strings de la derecha e izquierda tienen que ser copiados en un nuevo string por cada par de concatenaciones. Si concatenas cuatro strings de longitud 10, estarás copiando (10+10) + ((10+10)+10) + (((10+10)+10)+10) = 90 caracteres en vez de tan solo 40. Las cosas se complican de manera cuadrática cada vez que el número y el tamaño del string incrementa (justificado por el tiempo de ejecución de la funciónadd_bytes_with_plus). -
Se recomienda utilizar la sintaxis
.format.o%(sin embargo, son un poco mas lentas que+para cada string corto). -
O, aun mejor, si ya tienes contenidos disponibles en forma de objetos iterables, puedes usar
''.join(iterable_object)(lo cual es mucho más rápido). -
A diferencia de
add_bytes_with_plus,add_string_with_plusno devolvió un incremento cuadrático en el tiempo de ejecución debido a las optimizaciones de+=discutidas en el ejemplo anterior. Si la declaración fueses = s + "x" + "y" + "z"en vez des += "xyz"el incremento hubiese sido cuardrático.def add_string_with_plus(iters): s = "" for i in range(iters): s = s + "x" + "y" + "z" assert len(s) == 3*iters >>> %timeit -n100 add_string_with_plus(1000)
388 µs ± 22.4 µs por bucle (promedio ± std. dev. de 7 ejecuciones, 1000 bucles cada una)
>>> %timeit -n100 add_string_with_plus(10000) # Incremento cuadrático en el tiempo de ejecución
9 ms ± 298 µs por bucle (promedio ± std. dev. de 7 ejecuciones, 100 bucles cada una)
- Tantas maneras de crear un string gigante contrastan con el Zen de Python, según el cual,
Debería haber una --y preferiblemente solo una-- manera obvia de hacerlo.
▶ Ralentizando revisiones de dict *
some_dict = {str(i): 1 for i in range(1_000_000)} another_dict = {str(i): 1 for i in range(1_000_000)}
Output:
>>> %timeit some_dict['5'] 28.6 ns ± 0.115 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) >>> some_dict[1] = 1 >>> %timeit some_dict['5'] 37.2 ns ± 0.265 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) >>> %timeit another_dict['5'] 28.5 ns ± 0.142 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) >>> another_dict[1] # Trying to access a key that doesn't exist Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 1 >>> %timeit another_dict['5'] 38.5 ns ± 0.0913 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
¿Por qué se están ralentizando las mismas revisiones?
💡 Explicación:
- CPython tiene una función de revisión a diccionarios genérica que controla todos los tipos de llaves (
str,int, cualquier objeto ...) y una función especializada para los casos comunes de diccionarios que contienen solo llavesstr. - La función especial (llamada
lookdict_unicodeen el código de Python) sabe que todas las llaves existentes (incluyendo la llave revisada) son strins y utiliza la comparación de strings más rápida y simple para comparar las llaves, en vez de llamar al método__eq__- - Cuando se accede a la instancia de un
dictpor primera vez con una llave que no esstresta se modifica para que las revisiones futuras usen la función genérica. - Este proceso no es reversible para la instancia particular de
dicty la llave ni siquiera tiene que existir en el diccionario. Es por eso que intentar revisar de manera fallida devuelve el mismo resultado.
▶ Instancias de dict *
import sys class SomeClass: def __init__(self): self.some_attr1 = 1 self.some_attr2 = 2 self.some_attr3 = 3 self.some_attr4 = 4 def dict_size(o): return sys.getsizeof(o.__dict__)
Output: (Python 3.8. Puede variar dependiendo de la versión de Python 3)
>>> o1 = SomeClass() >>> o2 = SomeClass() >>> dict_size(o1) 104 >>> dict_size(o2) 104 >>> del o1.some_attr1 >>> o3 = SomeClass() >>> dict_size(o3) 232 >>> dict_size(o1) 232
Intentémoslo de nuevo, ahora en un nuevo intérprete:
>>> o1 = SomeClass() >>> o2 = SomeClass() >>> dict_size(o1) 104 # as expected >>> o1.some_attr5 = 5 >>> o1.some_attr6 = 6 >>> dict_size(o1) 360 >>> dict_size(o2) 272 >>> o3 = SomeClass() >>> dict_size(o3) 232
¿Qué hace que los diccionarios se inflen? Y, ¿por qué se crearon objetos inflados?
💡 Explicación:
- CPython puede reusar las mismas llaves del objeto en multiples diccionarios. Esta funcionalidad fue añadida en PEP 412 con la motivación de reducir el uso de memoria, específicamente en instancias de diccionarios donde las llaves tienden a ser comunes en todas las instancias.
- Esta optimización es perfecta para diccionarios de instancia, pero es deshabilitada si se rompen ciertas suposiciones.
- Los diccionarios que comparten llaves no soportan ser eleminados; si un atributo de instancia es eliminado, el diccionario se "deja de compartir" y se deshabilita la transferencia de llaves para todas las instancias futuras de la misma clase.
- Adicionalmente, si las llaves del diccionario cambiaron de tamaño (porque se añadieron más llaves) son reservadas solo si son usadas exactamente en un solo diccionario (esto permite añadir muchos atributos en el método
__init__de cada instancia sin "dejar de compartir"). Si múltiples instancias existen cuando se cambia de tamaño se deshabilita la transferencia de llaves para todas las instancias futuras de la misma clase: CPython no puede determinar si tus instancias usan el mismo conjunto de atributos, por lo que decide omitir la transferencia de llaves. - Un pequeño consejo: si quieres dismunuir el uso de memoria de tu programa, no borres los atributos de instancia y asegúrate de inicializar todos tus atributes en el método
__init__.
▶ Cambios menores *
join()es un método de string en vez de un método de lista.
💡 Explicación:
Si join() es un mpetodo de string puede operar cualquier iterable (lista, tulpe e iteradores). Si fuera un método de lista tendría que ser implementado de manera separada por cada tipo de datos. Además, no tiene mucho sentido pones un método específico para strings en una API genérica de objetos list.
- Algunas declaraciones que se ven algo raras pero aun así son correctas:
[] = ()es una declaración semánticamente correcta (desempaquetar untuplevacío en unalistvacía).'a'[0][0][0][0][0]también es una declaración semánticamente correcta ya que los strins son secuencias (iterables que soportan la asignación de elementos usando índices de enteros).3 --0-- 5 == 8y--5 == 5también están correctos semánticamente y devuelvenTrue.
-
Teniendo en cuenta que
aes un número,++ay--ason declaraciones válidas en Python pero no se comportan de la misma manera que lo hacen el lenguajes como C, C++ o Java.>>> a = 5 >>> a 5 >>> ++a 5 >>> --a 5
💡 Explicación:
- No existe el operador
++en la gramática de Python. En realidad, son simplemente dos operadores+. ++ase traduce como+(+a)que a su vez se traduce comoa. Similar a esto, el output de la declaración--apuede ser justificado.- En esta [pregunta] de StackOverflow se discute la lógica detrás de ausencia de los operadores de incremento y decremento en Python.
-
Tienes que tener cuidado con el operador Walrus en Python. Pero, ¿alguna vez has oído hablar de el operador "invasor espacial"?
>>> a = 42 >>> a -=- 1 >>> a 43
Se utiliza como una alternativa al operador de incremento, junto con otro,
💡 Explicación:
Esta broma viene del tweet de Raymond Hettinger. El operador "invasor espacial" es en realidad a -= (-1) pero escrito de una manera incorrecta. Esto es equivalente a a = a - (- 1). Lo mismo aplica para a += (+ 1).
-
Python tiene un operador "implicación inversa" no documentado.
>>> False ** False == True True >>> False ** True == False True >>> True ** False == True True >>> True ** True == True True
💡 Explicación:
Si reemplazas False y True con 0 y 1 y realizas la operación, verás que la tabla es equivalente a un operador de implicación inversa (fuente).
-
Ya que estamos hablando de operadores, aprovecho para decir que hay un operador
@para multiplicación matriz (no te preocupes, en esto caso es de verdad).>>> import numpy as np >>> np.array([2, 2, 2]) @ np.array([7, 8, 8]) 46
💡 Explicación:
El operador @ fue añadido en Python 3.5 teniendo en cuenta la comunidad científica. Cualquier objeto puede sobrecargar el método mágico __matmul__ para definir un comportamiento para este operador.
-
Desde Python 3.8 en adelante puede usar un típico string "f" para depurar rápidamente (
f'{some_var=}'). Por ejemplo,>>> some_string = "wtfpython" >>> f'{some_string=}' "some_string='wtfpython'"
-
Python usa 2 butes para almacenar variables locales de funcioens. En teoría esto significa que solo 65536 variables pueden ser definidas en una función. Sin embargo, Python tiene una solución integrada que puede ser utilizada para almacenar más de 2^16 nombres de variables. El siguiente código demuestra qué pasa cuando hay más de 65536 variables locales definidas (cuidado: el siguiente código imprime alrededor de 2^18 líneas de texto. ¡Prepárate!):
import dis exec(""" def f(): """ + """ """.join(["X" + str(x) + "=" + str(x) for x in range(65539)])) f() print(dis.dis(f))
-
Muchos "threads" en Python no ejecutarán tu código concurrentemente (¡si, lo escuchaste bien!). Puede parecer intuitivo crear muchos "threads" y dejar que ejecuten tu código de Python concurrentemente, pero, debido a "Global Interpreter Lock", lo único que estás haciendo es que tus "threads" se ejecuten en el mismo core uno por uno. Los threads de Python son buenos para tareas de IO, pero para conseguir un resultado de paralelización en Python para tareas de CPU, tal vez quieras usar el módulo multiprocessing de Python.
-
A veces, el método
printno imprimirá los valores inmediatamente. Por ejemplo,# File some_file.py import time print("wtfpython", end="_") time.sleep(3)
Esto imprimirá wtfpython después de 3 segundos porque el argumento end en el output está paralizado ya sea porque se encontró \n o porque el programa terminó de ejecutarse. Podemos hacer que esto ocurra a la fuerza pasando el argumento flush=True.
-
Partir listas fuera de los índices finales no devuelve ningún error
>>> some_list = [1, 2, 3, 4, 5] >>> some_list[111:] []
-
Partir un iterable no siempre crea un nuevo objeto. Por ejemplo,
>>> some_str = "wtfpython" >>> some_list = ['w', 't', 'f', 'p', 'y', 't', 'h', 'o', 'n'] >>> some_list is some_list[:] # Se esperaba `False` porque se creó un nuevo objeto. False >>> some_str is some_str[:] # `True` porque los strings son inmutables, lo que crea un nuevo objeto sin mucha utilidad. True
-
int('١٢٣٤٥٦٧٨٩')devuelve 123456789` en Python 3. En Python, los caracteres decimales incluyen dígitos y todos los caracteres que pueden ser usados en forma de decimal, como U+0660, ARABIC-INDIC DIGIT ZERO. Hay una historia interesante en relación a este comportamiento de Python. -
Puedes separar números con pisos bajos (para una mejor legibilidad) desde Python 3 en adelante.
>>> six_million = 6_000_000 >>> six_million 6000000 >>> hex_address = 0xF00D_CAFE >>> hex_address 4027435774
-
'abc'.count('') == 4. Esta es una implementación aproximada al métodocount. el cual haría las cosas más fáciles de entender,def count(s, sub): result = 0 for i in range(len(s) + 1 - len(sub)): result += (s[i:i + len(sub)] == sub) return result
Este comportamiento se debe a que se detecta un substring vacío ('') con particiones de longitud 0 en el string original.
Contribuir
Hay varias maneras en las que puedes contribuir a wtfpython,
- Recomendando más ejemplos.
- Ayudando a traducir (ve los Issues con la etiqueta "translation").
- Corrijiendo errores pequeños como códigos obsoletos, errores de escritura, errores en el formato, etc.
- Identificando cosas como explicaciones no adecuadas, ejemplos redundantes, etc.).
- Cualquier recomendación creativa que haga que este proyecto sea más divertido y útil.
Por favor lee el archivo CONTRIBUTING.md para más detalles. No dudes en crear un Issue si quieres discutir sobre algo.
PD: Por favor, no recomiendes enlaces. Ningún enlace será añadido a no ser que sea muy relevante al proyecto.
Reconocimientos
La idea y el diseño de esta colleción está inspirada en el increíble proyecto de Denys Dovhan wtfjs. El apoyo incondicional de los Pythonistas le han dado una forma increíble.
¡Algunos enlaces útiles!
- https://www.youtube.com/watch?v=sH4XF6pKKmk
- https://www.reddit.com/r/Python/comments/3cu6ej/what_are_some_wtf_things_about_python
- https://sopython.com/wiki/Common_Gotchas_In_Python
- https://stackoverflow.com/questions/530530/python-2-x-gotchas-and-landmines
- https://stackoverflow.com/questions/1011431/common-pitfalls-in-python
- https://www.python.org/doc/humor/
- https://github.com/cosmologicon/pywat#the-undocumented-converse-implication-operator
- https://www.codementor.io/satwikkansal/python-practices-for-efficient-code-performance-memory-and-usability-aze6oiq65
- https://github.com/wemake-services/wemake-python-styleguide/search?q=wtfpython&type=Issues
- WFTPython discussion threads on Hacker News and Reddit.
🎓 Licencia
¡Sorprende a tus amigos!
Si te gusta wtfpython, puedes usar estos enlaces para compartir el proyecto con tus amigos,
¿Necesitas una versión en PDF?
He recibido algunas peticiones de una versión en PDF (y epub) de wtfpython. Puedes agregar tu información aquí para poder verla tan rápido como sea posible.
¡Eso es todo amigos! Para más contenido como este, puedes agregar tu dirección de correo electrónico aquí.