
Trending Papers - Hugging Face
new
Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
 AK and the research community
AK and the research community

Submitted by

evanking
Monolingual ASR models trained on a balanced mix of high-quality, pseudo-labeled, and synthetic data outperform multilingual models for small model sizes, achieving superior error rates and enabling on-device ASR for underrepresented languages.
· Published on Sep 2, 2025
Submitted by
evanking

AutoDev is an AI-driven software development framework that automates complex engineering tasks within a secure Docker environment, achieving high performance in code and test generation.
· Published on Mar 13, 2024
AutoDev is an AI-driven software development framework that automates complex engineering tasks within a secure Docker environment, achieving high performance in code and test generation.

Submitted by

andito
Submitted by
andito

Submitted by

taesiri
Submitted by
taesiri

Submitted by

xhyandwyy
GUI-Owl and Mobile-Agent-v3 are open-source GUI agent models and frameworks that achieve state-of-the-art performance across various benchmarks using innovations in environment infrastructure, agent capabilities, and scalable reinforcement learning.
· Published on Aug 21, 2025
Submitted by
xhyandwyy
GUI-Owl and Mobile-Agent-v3 are open-source GUI agent models and frameworks that achieve state-of-the-art performance across various benchmarks using innovations in environment infrastructure, agent capabilities, and scalable reinforcement learning.

Submitted by

akhaliq
Submitted by
akhaliq


Submitted by
akhaliq
Mem0, a memory-centric architecture with graph-based memory, enhances long-term conversational coherence in LLMs by efficiently extracting, consolidating, and retrieving information, outperforming existing memory systems in terms of accuracy and computational efficiency.
· Published on Apr 28, 2025
Submitted by
akhaliq

Submitted by
taesiri
The Qwen3-TTS series presents advanced multilingual text-to-speech models with voice cloning and controllable speech generation capabilities, utilizing dual-track LM architecture and specialized speech tokenizers for efficient streaming synthesis.
 Qwen · Published on Jan 22, 2026
Qwen · Published on Jan 22, 2026
Submitted by
taesiri
The Qwen3-TTS series presents advanced multilingual text-to-speech models with voice cloning and controllable speech generation capabilities, utilizing dual-track LM architecture and specialized speech tokenizers for efficient streaming synthesis.
Qwen · Jan 22, 2026

Submitted by

hao-li
Agentic coding tools receive goals written in natural language as input, break them down into specific tasks, and write or execute the actual code with minimal human intervention. Central to this process are agent context files ("READMEs for agents") that provide persistent, project-level instructions. In this paper, we conduct the first large-scale empirical study of 2,303 agent context files from 1,925 repositories to characterize their structure, maintenance, and content. We find that these files are not static documentation but complex, difficult-to-read artifacts that evolve like configuration code, maintained through frequent, small additions. Our content analysis of 16 instruction types shows that developers prioritize functional context, such as build and run commands (62.3%), implementation details (69.9%), and architecture (67.7%). We also identify a significant gap: non-functional requirements like security (14.5%) and performance (14.5%) are rarely specified. These findings indicate that while developers use context files to make agents functional, they provide few guardrails to ensure that agent-written code is secure or performant, highlighting the need for improved tooling and practices.
· Published on Nov 17, 2025
Submitted by
hao-li
Agentic coding tools receive goals written in natural language as input, break them down into specific tasks, and write or execute the actual code with minimal human intervention. Central to this process are agent context files ("READMEs for agents") that provide persistent, project-level instructions. In this paper, we conduct the first large-scale empirical study of 2,303 agent context files from 1,925 repositories to characterize their structure, maintenance, and content. We find that these files are not static documentation but complex, difficult-to-read artifacts that evolve like configuration code, maintained through frequent, small additions. Our content analysis of 16 instruction types shows that developers prioritize functional context, such as build and run commands (62.3%), implementation details (69.9%), and architecture (67.7%). We also identify a significant gap: non-functional requirements like security (14.5%) and performance (14.5%) are rarely specified. These findings indicate that while developers use context files to make agents functional, they provide few guardrails to ensure that agent-written code is secure or performant, highlighting the need for improved tooling and practices.
· Nov 17, 2025

Submitted by

parachas
A preference-aligned routing framework using a compact 1.5B model effectively matches queries to user-defined domains and action types, outperforming proprietary models in subjective evaluation criteria.
· Published on Jun 19, 2025
Submitted by
parachas


Submitted by
taesiri
Submitted by
taesiri



Submitted by
taesiri
Submitted by
taesiri

Submitted by

xiaochonglinghu
Submitted by
xiaochonglinghu

Submitted by
akhaliq
Submitted by
akhaliq

Submitted by
taesiri
Submitted by
taesiri

Submitted by
akhaliq
Enhancements to the AgentScope platform improve scalability, efficiency, and ease of use for large-scale multi-agent simulations through distributed mechanisms, flexible environments, and user-friendly tools.
· Published on Jul 25, 2024
Submitted by
akhaliq

LightRAG improves Retrieval-Augmented Generation by integrating graph structures for enhanced contextual awareness and efficient information retrieval, achieving better accuracy and response times.
· Published on Oct 8, 2024

A self-supervised framework optimizes prompts for both closed and open-ended tasks by evaluating LLM outputs without external references, reducing costs and required data.
· Published on Feb 7, 2025
A self-supervised framework optimizes prompts for both closed and open-ended tasks by evaluating LLM outputs without external references, reducing costs and required data.

Submitted by
akhaliq
Submitted by
akhaliq

Submitted by

chenwang
Submitted by
chenwang

Text-to-LoRA (T2L) is a hypernetwork that dynamically adapts large language models using natural language descriptions, enabling efficient and zero-shot task-specific fine-tuning with minimal computational resources.

· Published on Jun 6, 2025
Text-to-LoRA (T2L) is a hypernetwork that dynamically adapts large language models using natural language descriptions, enabling efficient and zero-shot task-specific fine-tuning with minimal computational resources.
· Jun 6, 2025

Submitted by

UglyToilet
MemOS, a memory operating system for Large Language Models, addresses memory management challenges by unifying plaintext, activation-based, and parameter-level memories, enabling efficient storage, retrieval, and continual learning.
· Published on Jul 4, 2025
Submitted by
UglyToilet
MemOS, a memory operating system for Large Language Models, addresses memory management challenges by unifying plaintext, activation-based, and parameter-level memories, enabling efficient storage, retrieval, and continual learning.

Submitted by
taesiri
GLM-5 advances foundation models with DSA for cost reduction, asynchronous reinforcement learning for improved alignment, and enhanced coding capabilities for real-world software engineering.
· Published on Feb 17, 2026
Submitted by
taesiri
GLM-5 advances foundation models with DSA for cost reduction, asynchronous reinforcement learning for improved alignment, and enhanced coding capabilities for real-world software engineering.

Submitted by
taesiri
Submitted by
taesiri

Submitted by

Rbin
RAG-Anything is a unified framework that enhances multimodal knowledge retrieval by integrating cross-modal relationships and semantic matching, outperforming existing methods on complex benchmarks.
Submitted by
Rbin
RAG-Anything is a unified framework that enhances multimodal knowledge retrieval by integrating cross-modal relationships and semantic matching, outperforming existing methods on complex benchmarks.

Submitted by

lixiaoxi45
OmniGAIA benchmark evaluates multi-modal agents on complex reasoning tasks across video, audio, and image modalities, while OmniAtlas agent improves tool-use capabilities through hindsight-guided tree exploration and OmniDPO fine-tuning.
· Published on Feb 26, 2026
Submitted by
lixiaoxi45
OmniGAIA benchmark evaluates multi-modal agents on complex reasoning tasks across video, audio, and image modalities, while OmniAtlas agent improves tool-use capabilities through hindsight-guided tree exploration and OmniDPO fine-tuning.


Submitted by

zhongwenxu
Single-stream Policy Optimization (SPO) improves policy-gradient training for Large Language Models by eliminating group-based issues and providing a stable, low-variance learning signal, leading to better performance and efficiency.
 Tencent · Published on Sep 16, 2025
Tencent · Published on Sep 16, 2025
Submitted by
zhongwenxu
Single-stream Policy Optimization (SPO) improves policy-gradient training for Large Language Models by eliminating group-based issues and providing a stable, low-variance learning signal, leading to better performance and efficiency.
Submitted by

rajkumarrawal
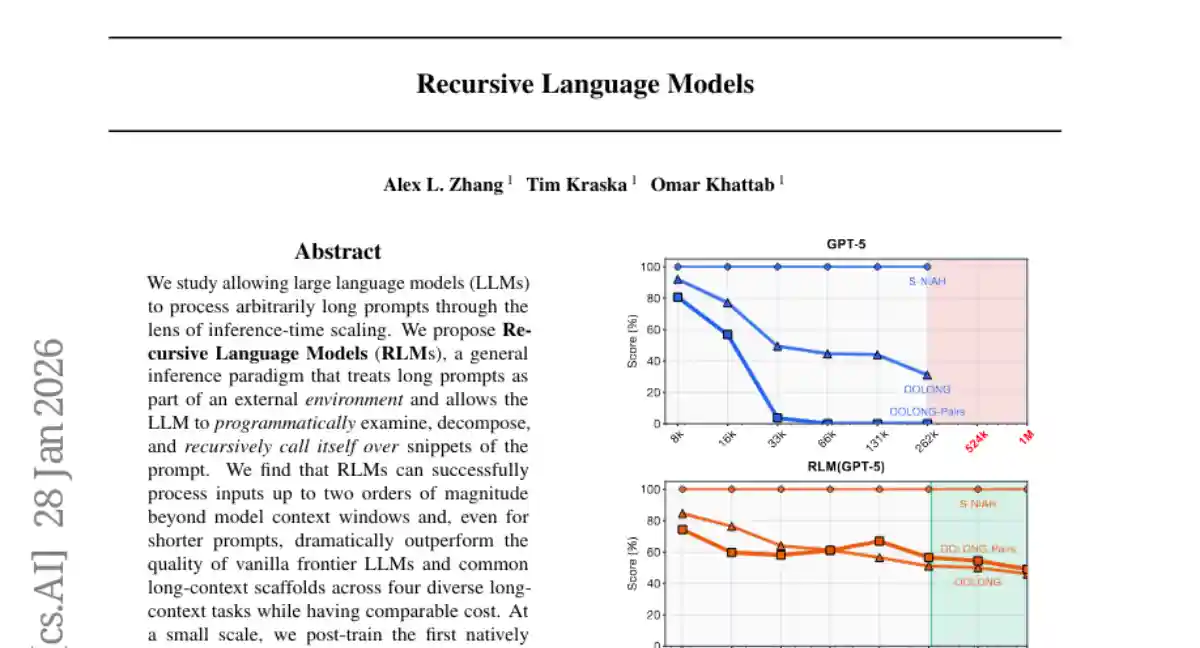
We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse long-context tasks, while having comparable (or cheaper) cost per query.
Submitted by
rajkumarrawal
We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse long-context tasks, while having comparable (or cheaper) cost per query.

A centralized orchestrator dynamically directs LLM agents via reinforcement learning, achieving superior multi-agent collaboration in varying tasks with reduced computational costs.

· Published on May 26, 2025
A centralized orchestrator dynamically directs LLM agents via reinforcement learning, achieving superior multi-agent collaboration in varying tasks with reduced computational costs.
· May 26, 2025


Submitted by

nielsr
Submitted by
nielsr


DeepSeek-V3 is a parameter-efficient Mixture-of-Experts language model using MLA and DeepSeekMoE architectures, achieving high performance with efficient training and minimal computational cost.
 DeepSeek · Published on Dec 27, 2024
DeepSeek · Published on Dec 27, 2024
DeepSeek-V3 is a parameter-efficient Mixture-of-Experts language model using MLA and DeepSeekMoE architectures, achieving high performance with efficient training and minimal computational cost.
LTX-2 is an open-source audiovisual diffusion model that generates synchronized video and audio content using a dual-stream transformer architecture with cross-modal attention and classifier-free guidance.
· Published on Jan 6, 2026

Submitted by

Dongchao
A suite of open-source music foundation models is introduced, featuring components for audio-text alignment, lyric recognition, music coding, and large language model-based song generation with controllable attributes and scalable parameterization.
· Published on Jan 15, 2026
Submitted by
Dongchao
A suite of open-source music foundation models is introduced, featuring components for audio-text alignment, lyric recognition, music coding, and large language model-based song generation with controllable attributes and scalable parameterization.
DreamZero is a World Action Model that leverages video diffusion to enable better generalization of physical motions across novel environments and embodiments compared to vision-language-action models.
DreamZero is a World Action Model that leverages video diffusion to enable better generalization of physical motions across novel environments and embodiments compared to vision-language-action models.

Submitted by

unilm
VibeVoice synthesizes long-form multi-speaker speech using next-token diffusion and a highly efficient continuous speech tokenizer, achieving superior performance and fidelity.
Submitted by
unilm
VibeVoice synthesizes long-form multi-speaker speech using next-token diffusion and a highly efficient continuous speech tokenizer, achieving superior performance and fidelity.

Kronos, a specialized pre-training framework for financial K-line data, outperforms existing models in forecasting and synthetic data generation through a unique tokenizer and autoregressive pre-training on a large dataset.
· Published on Aug 2, 2025

Submitted by

AdinaY
Submitted by
AdinaY

Submitted by

daixufang
Submitted by
daixufang

