Compositional Physical Reasoning of Objects and Events from Videos
Yunzhu Li5
Antonio Torralba6
Joshua B. Tenenbaum6
Chuang Gan1, 7
* (Equal Contributions)
Abstract
Understanding and reasoning about objects' physical properties in the natural world is a fundamental challenge in artificial intelligence. While some properties like colors and shapes can be directly observed, others, such as mass and electric charge, are hidden from the objects' visual appearance. This paper addresses the unique challenge of inferring these hidden physical properties from objects' motion and interactions and predicting corresponding dynamics based on the inferred physical properties. We first introduce the Compositional Physical Reasoning (ComPhy) dataset. For a given set of objects, ComPhy includes limited videos of them moving and interacting under different initial conditions. The model is evaluated based on its capability to unravel the compositional hidden properties, such as mass and charge, and use this knowledge to answer a set of questions. Besides the synthetic videos from simulators, we also collect a real-world dataset to show further test physical reasoning abilities of different models. We evaluate state-of-the-art video reasoning models on ComPhy and reveal their limited ability to capture these hidden properties, which leads to inferior performance. We also propose a novel neuro-symbolic framework, Physical Concept Reasoner (PCR), that learns and reasons about both visible and hidden physical properties. Leveraging an object-centric representation, PCR utilizes videos and the associated natural language to infer objects' physical properties without dense object annotations. It incorporates property-aware graph networks to approximate the dynamic interactions among objects. Furthermore, PCR employs a semantic parser to convert questions into semantic programs, and a program executor to execute the programs based on the learned physical properties and dynamics. After training, PCR demonstrates remarkable capabilities. It can detect and associate objects across frames, ground visible and hidden physical properties, make future and counterfactual predictions, and utilize these extracted representations to answer questions. We hope the proposed ComPhy dataset and the PCR model present a promising step towards more comprehensive physical reasoning in AI systems.
Dataset
ComPhy
target video
reference videos
Factual
Questions
event exist
Q: Are there any cubes that enter the scene after the blue object exits the scene?
A: no
event query
What shape is the first object to collide with the cyan object?
A: sphere
object both query
What are the colors of the two objects that are oppositely charged?
A: yellow and blue
Counterfactual & Predictive
Questions
counterfact opposite
If the blue object were oppositely charged, which event given below would not happen?
- a) The yellow object and the brown object would collide
- b) The blue object and the yellow sphere would collide
predictive
What event given below will happen next?
- a) The yellow object and the cube collide
- b) The cube and the brown object collide
Real-world Scenario
target video
reference videos
Factual
Questions
event exist
Q: Is the stationary brown cube magnetic?
A: yes
object magnetism count
How many cubes are magnetic?
A: 2
object object mass compare
Is the brown cube lighter than the grey sphere?
A: yes
Counterfactual & Predictive
Questions
counterfact heavier
If the red cube were heavier, which event would happen?
- a) The red cube and the grey sphere would collide
- b) The red cube and the brown cube would collide
predictive
What event will not happen next?
- a) The red cube and the grey sphere would collide
- b) The brown cube and the sphere would collide
Physical Concept Reasoner

We present Physical Concept Reasoner (PCR), a new physical reasoning model, which aims to comprehend objects' visible properties, infer hidden physical properties and events, and image corresponding physical dynamics by observing the videos and responding to the associated questions.
PCR can be factorized into different functional modules for physical reasoning in videos. As shown in the figure above, the model consists of five major modules: (1) Video Perceiver, (2) Visible Property Grounder, (3) Physical Property Inferencer, (4) Property-based Dynamic Predictor, and (5) Differentiable Symbolic Executor. The perception module detects objects' location and visual appearance attributes. The physical property learner learns objects' properties based on detected object trajectories. The dynamic predictor predicts objects' dynamics in the counterfactual scene based on objects' properties and locations. Finally, an execution engine runs the program parsed by the language parser on the predicted dynamic scene to answer the question.
Example
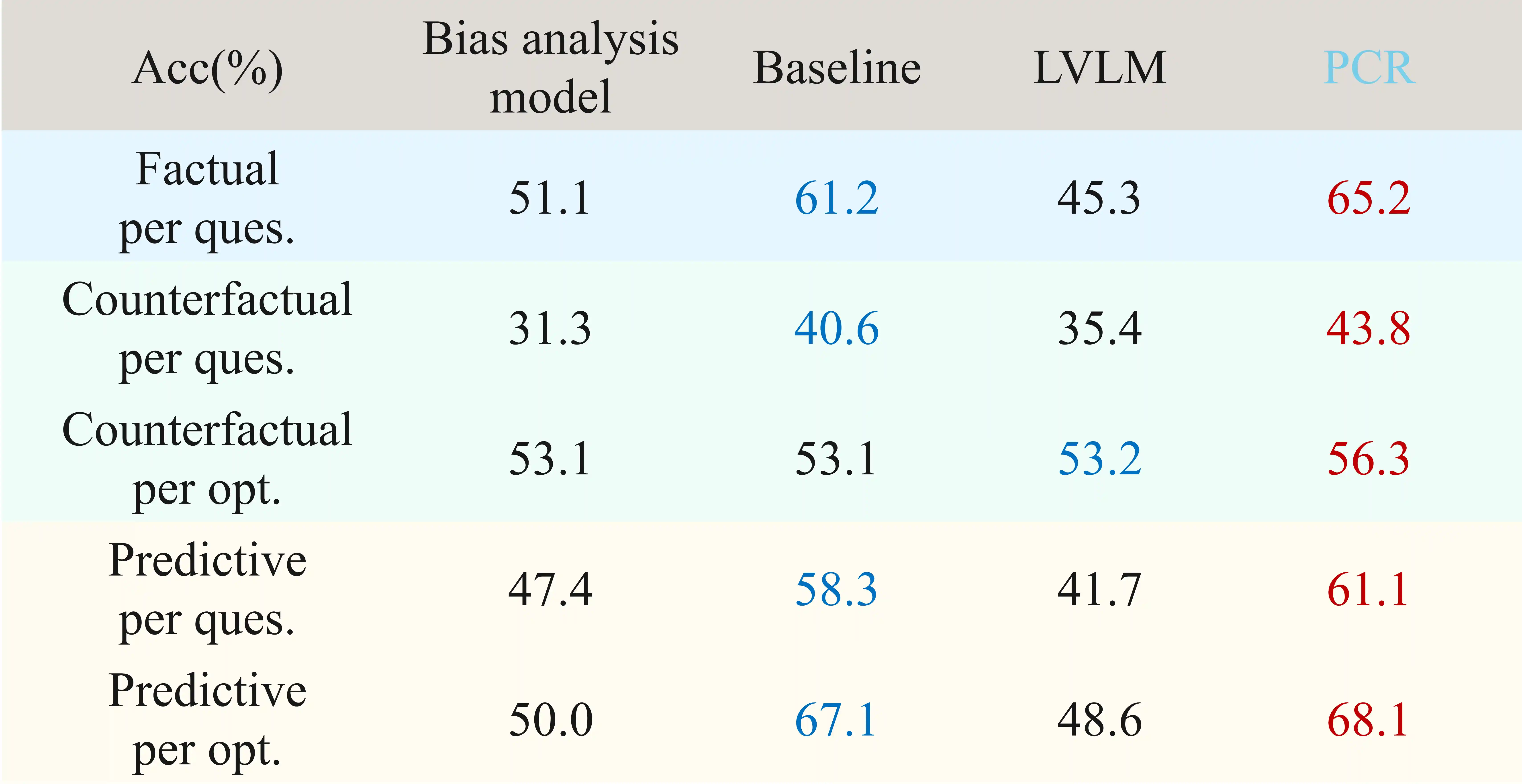
Experiments
ComPhy

Real-world Scenario