PhyX
Does Your Model Have the "Wits" for Physical Reasoning?
Taiqiang Wu1,
Qi Han3,
Yunta Hsieh2,
Jizhou Wang4,
Yuyue Zhang3,
Yuxin Cheng1,
Zijian Hao3,
Yuansheng Ni5,
Xin Wang6,
Zhongwei
Wan6,
Kai Zhang6,
Wendong Xu1,
Jing
Xiong1,
Ping Luo1,
Wenhu Chen5,
Chaofan Tao1†,
Z. Morley Mao2,
Ngai Wong1†,
1The University of Hong Kong,
2University of Michigan,
3Independent,
4University of Toronto,
5University of Waterloo,
6The Ohio State University
†Corresponding author.
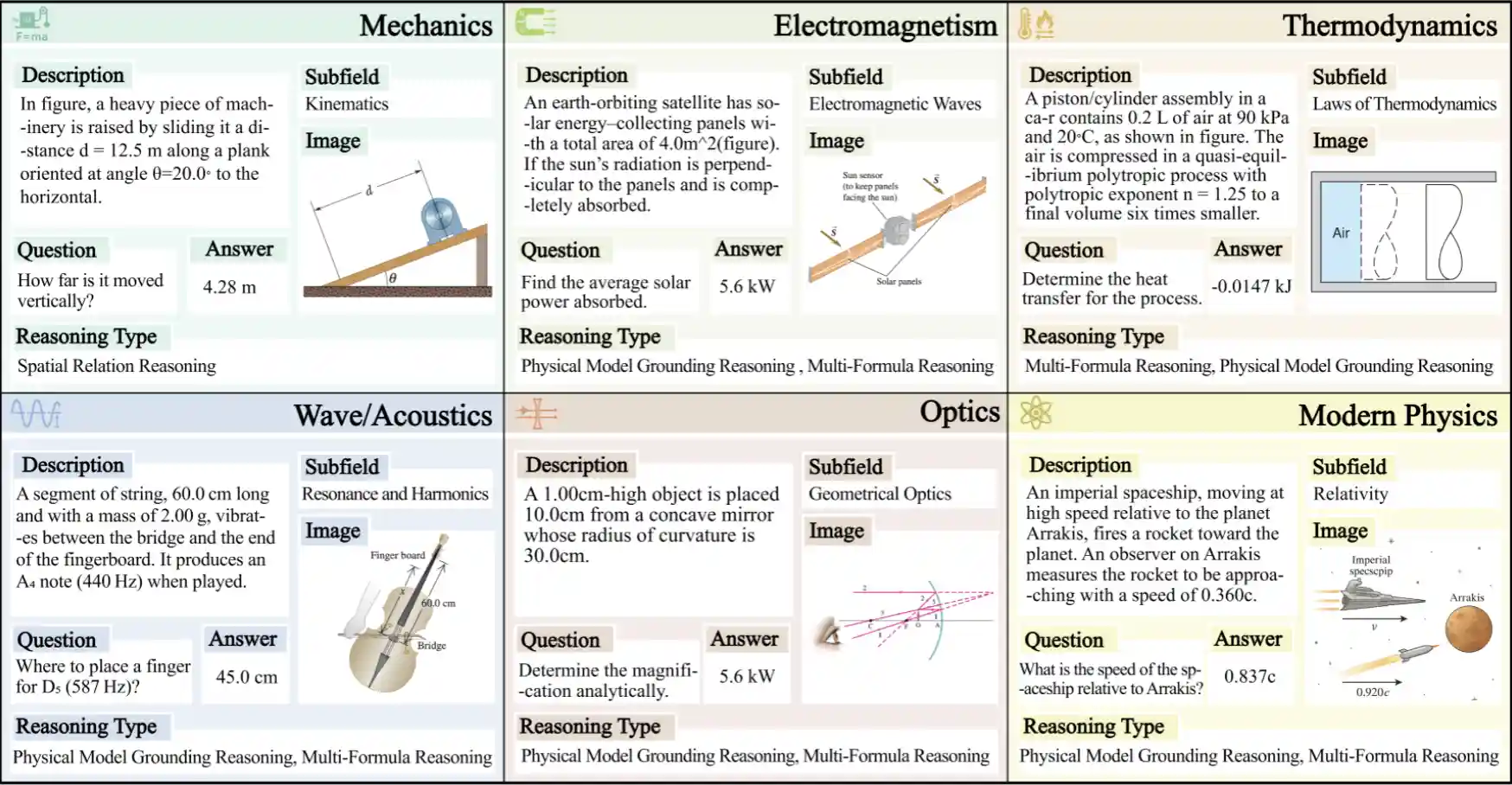
Data examples of the PhyX dataset. The dataset contains 3,000 human-annotated physics problems with visual context.
🔔News
🎉 [2026.02.15]: Seed 2.0 technical report has been released and it outperforms GPT-5.2-High by 0.6% on PhyX, congratulations!
🎉 [2025.12.17]: Step-GUI technical report has been released and it outperforms Qwen3-VL-30B-A3B by 10.0% on PhyX, congratulations!
🔥 [2025-07-21]: PhyX is officially supported by lmms-eval for easy evalution! 🎉
🎉 [2025.07.10]: Skywork-R1V3 technical report has been released and it outperforms Qwen2.5-VL-72B by 8.0% on PhyX, congratulation!
🔥 [2025-05-27]: PhyX is officially supported by VLMEvalKit for easy evalution! 🎉
🚀 [2025-05-23]: The arXiv paper is online! 🚀
🚀 [2025-05-21]: We release the testmini set of PhyX at Huggingface and the evaluation code! 🚀
Introduction
We introduce PhyX: the first large-scale benchmark designed to assess models capacity for physics-grounded reasoning in visual scenarios. PhyX includes 3K meticulously curated multimodal questions spanning 6 reasoning types across 25 sub-domains and 6 core physics domains: thermodynamics, electromagnetism, mechanics, modern physics, optics, and wave&acoustics. In our comprehensive evaluation, even state-of-the-art models struggle significantly with physical reasoning. GPT-4o, Claude3.7-Sonnet, and GPT-o4-mini achieve only 32.5%, 42.2%, and 45.8% accuracy respectively-performance gaps exceeding 29% compared to human experts.
 PhyX Benchmark
PhyX Benchmark
Comparisons with Existing Benchmarks
To further distinguish the difference between PhyX and other existing ones, we elaborate the benchmark details in figure. From the realistic perspective, the prior benchmarks are heavily focused on abstract lining. In contrast, our benchmark are realistic and delete text redundancy.
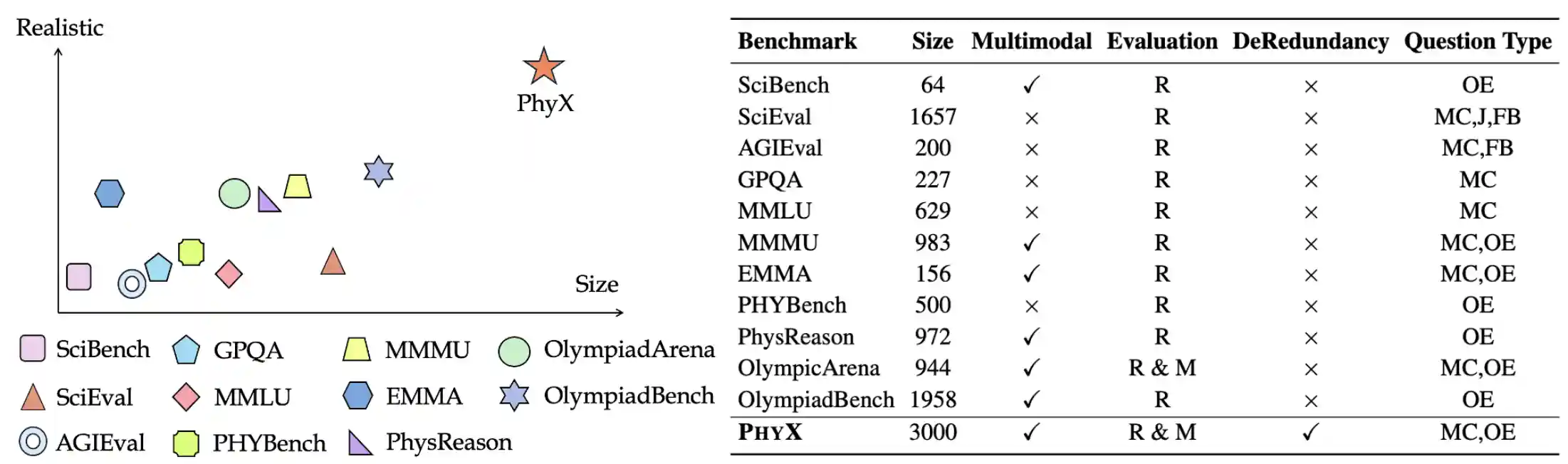
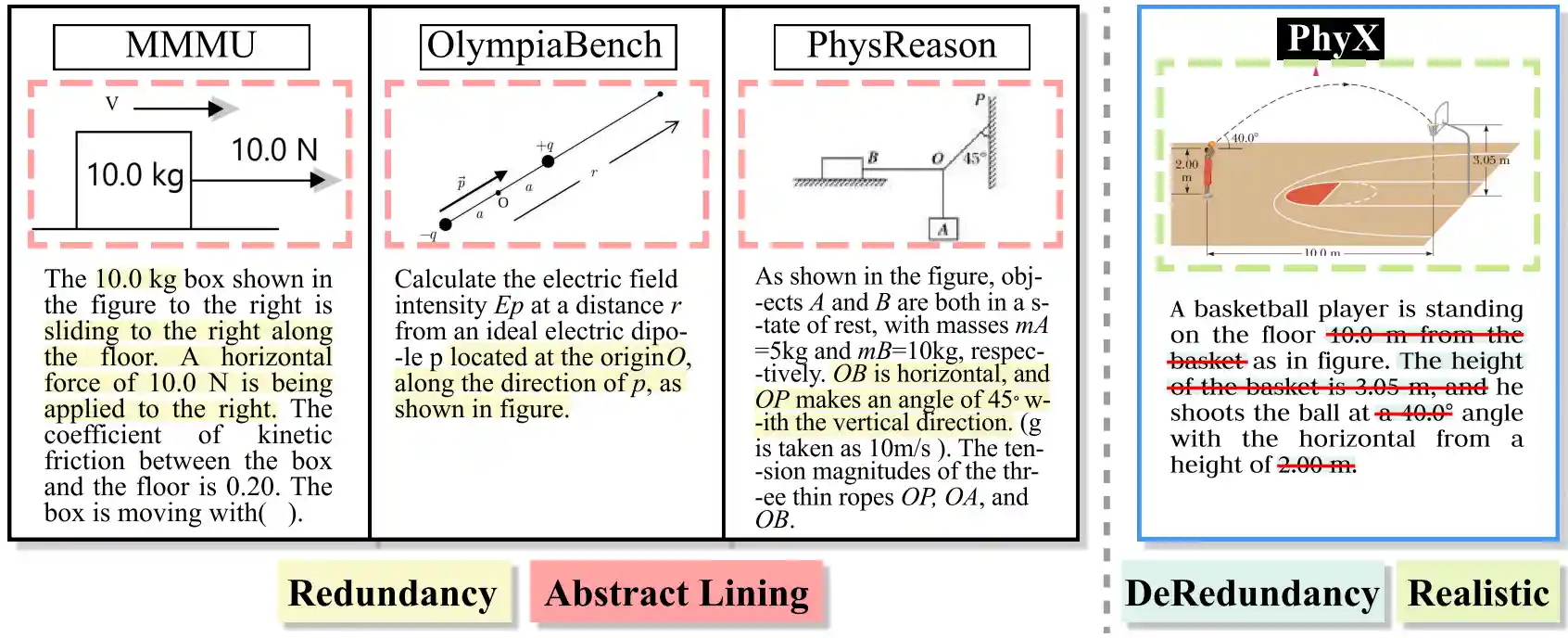
Comparison with existing physics benchmarks.
Statistics
Sampled PhyX examples from each discipline.
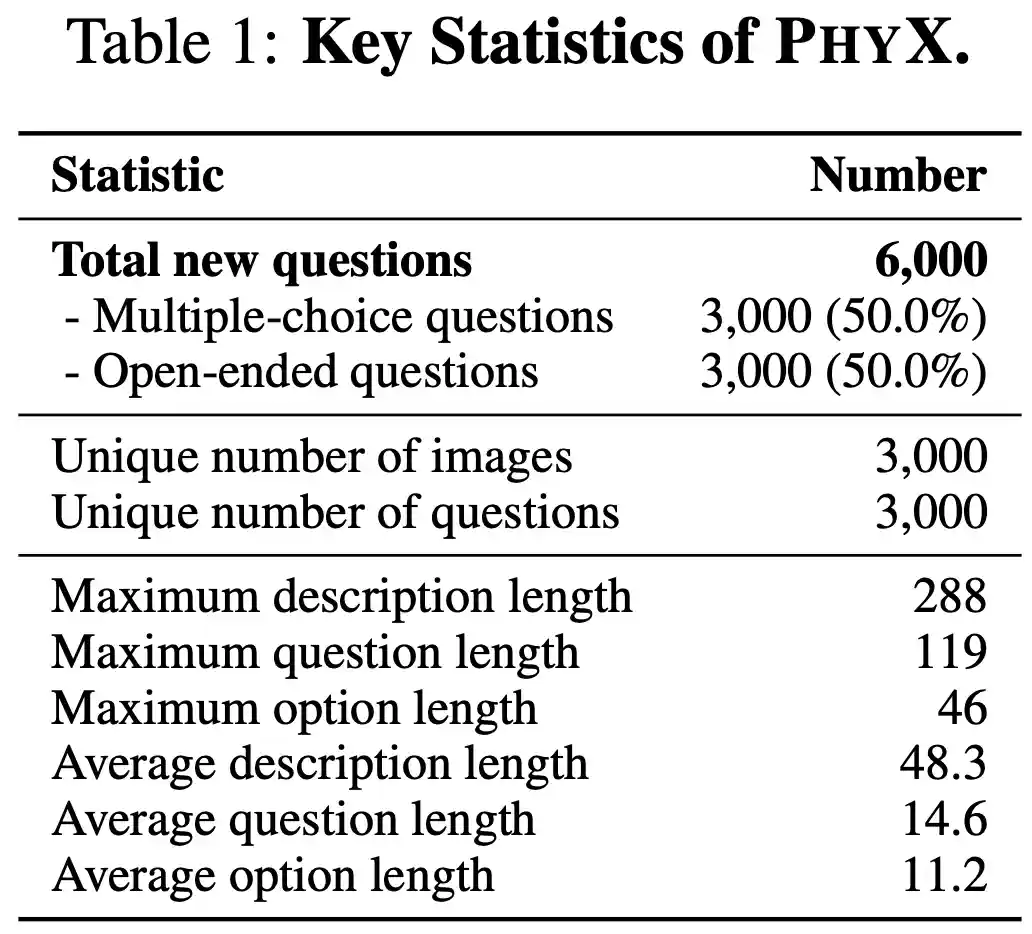
Key statistics of the PhyX benchmark
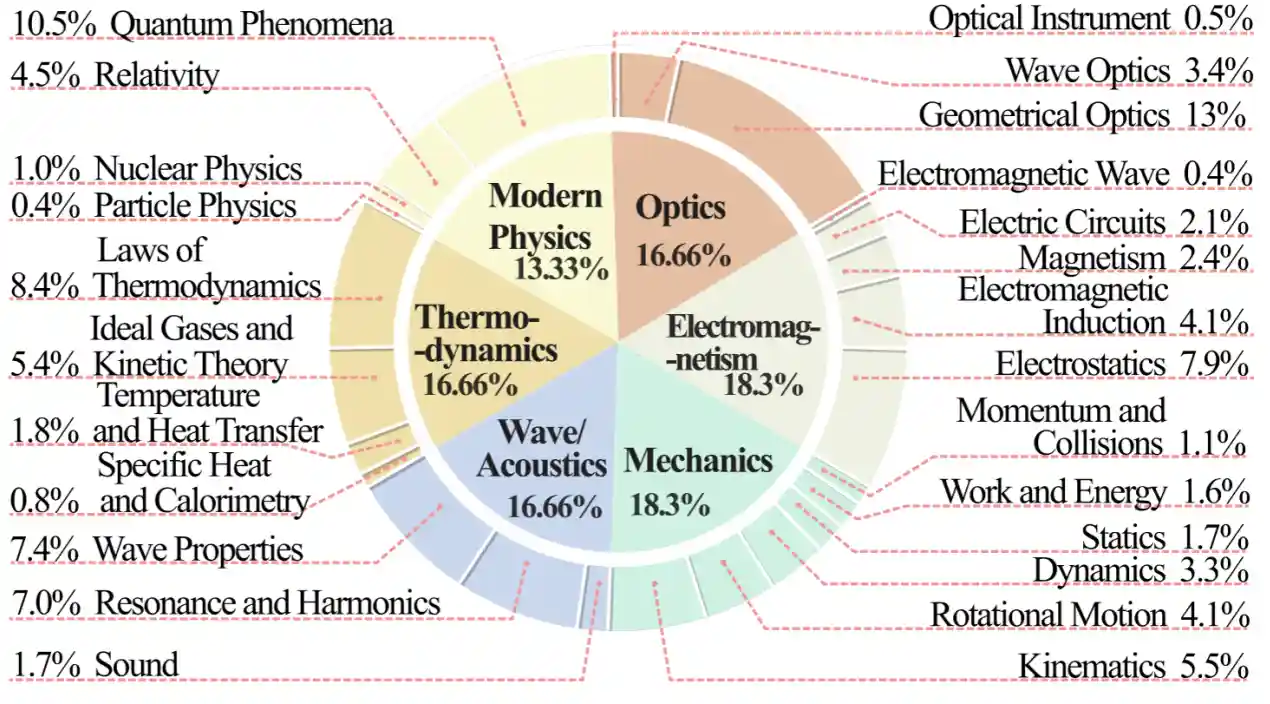
Distribution of question domains in the PhyX dataset
Experiment Results
Data
You can directly download our data from Huggingface datasets. For guidance on how to access and utilize the data, please consult our instructions on Github.
Leaderboard
We evaluate various models including LLMs and LMMs. In each type, we consider both closed- and open-source models. Our evaluation is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark.
In our leaderboard, the default setting is the testmini subset with Text-DeRedundancy setting, which removes text redundancy in the question (`PhyX_mini_OE.tsv` & `PhyX_mini_MC.tsv`). We suggest using this setting for a fair comparison.
🚨 To submit your results to the leaderboard, please send to huishen [at] umich [dot] edu with your results.
Human Expert Open-Source Proprietary
Click on PhyX(OE), PhyX(MC) or PhyX(domain) to expand detailed results.
| Reset | PhyX(OE) ▼ | PhyX(MC) ▼ | PhyX(domain) ▼ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Size | Date | Text-DeRedundancy | Full-Text | Text-Minimal | Text-DeRedundancy | Full-Text | Text-Minimal | Overall | Mechanics | Electro-magnetism | Thermo-dynamics | Waves & Acoustics | Optics | Modern Physics |
Overall results of different models on the PhyX leaderboard. The best-performing model in each category is in-bold, and the second best is underlined. *: results provided by the authors.
Error Analysis
To dive into the reasoning capabilities and limitations of models, we meticulously inspected 96 randomly sampled incorrect predictions and performed an in-depth analysis based on GPT-4o. The objectives of this analysis were twofold: to identify current model weaknesses and to guide future enhancements in model design and training. A comprehensive case study of 30 notable cases is included in our paper, Appendix E.

Error distribution over 96 annotated GPT-4o errors.
Error Examples
Correct Examples
BibTeX
@misc{shen2025phyxdoesmodelwits,
title={PhyX: Does Your Model Have the "Wits" for Physical Reasoning?},
author={Hui Shen and Taiqiang Wu and Qi Han and Yunta Hsieh and Jizhou Wang and Yuyue Zhang and Yuxin Cheng and Zijian Hao and Yuansheng Ni and Xin Wang and Zhongwei Wan and Kai Zhang and Wendong Xu and Jing Xiong and Ping Luo and Wenhu Chen and Chaofan Tao and Zhuoqing Mao and Ngai Wong},
year={2025},
eprint={2505.15929},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.15929},
}