val numRecords = 100 * 1000 * 1000L; val numFiles = 200;
val df = spark.range(0, numFiles, 1, numFiles).mapPartitions { it => val partitionID = it.toStream.head val r = new Random(seed = partitionID) Iterator.fill((numRecords / numFiles).toInt)(randomConnRecord(r)) };
// conn_order_only_ip create table sample.conn_order_only_ip like sample.conn_random; INSERT overwrite sample.conn_order_only_ip select * from sample.conn_random order by src_ip, dst_ip;
// conn_order create table sample.conn_order like sample.conn_random; INSERT overwrite sample.conn_order select * from sample.conn_random order by src_ip, src_port, dst_ip, dst_port;
2、生成 Z-order 优化的表:
1 2 3 4 5 6 7 8 9
// conn_zorder_only_ip create table sample.conn_zorder_only_ip like sample.conn_random; insert overwrite sample.conn_zorder_only_ip select * from sample.conn_random; OPTIMIZE sample.conn_zorder_only_ip ZORDER BY src_ip, dst_ip;
// conn_zorder create table sample.conn_zorder like sample.conn_random; insert overwrite sample.conn_zorder select * from sample.conn_random; OPTIMIZE sample.conn_zorder ZORDER BY src_ip, src_port, dst_ip, dst_port;
Zorder 优化效果对比分析
1、存储分析
表名
大小
生成时间
conn_random
2.7 G
1.1 min
conn_order_only_ip
2.2 G
1.3 min
conn_order
2.2 G
52 s
conn_zorder_only_ip
1510.3 MiB
1.9 min
conn_zorder
1510.4 MiB
1.9 min
2、查询分析
1 2 3 4 5 6
// query select count(*) from sample.conn_random where src_ip like '157%' and dst_ip like '216.%'; select count(*) from sample.conn_order_only_ip where src_ip like '157%' and dst_ip like '216.%'; select count(*) from sample.conn_order where src_ip like '157%' and dst_ip like '216.%'; select count(*) from sample.conn_zorder_only_ip where src_ip like '157%' and dst_ip like '216.%'; select count(*) from sample.conn_zorder where src_ip like '157%' and dst_ip like '216.%';
表名
扫描数据量
conn_random
100,000,000
conn_order_only_ip
400,000
conn_order
400,648
conn_zorder_only_ip
120,000
conn_zorder
120,000
3、总结
从上面的测试结果中可以很直观的看到 Z-order 优化的一些特点:
排序消耗:由于需要对数据进行排序,所以对于数据生产任务有少许额为的排序消耗。
减少空间:数据进行了聚类,使得相邻数据有很高的相似性,大幅提高数据压缩率,减少存储空间。
提高查询性能:数据临近也让 RowGroup 数据范围比较小,加大了查询时 Data skip 效果,减少扫描的数据量,提升查询性能。
CREATE TEMPORARY VIEW jdbcTable USING org.apache.spark.sql.jdbc OPTIONS ( url 'jdbc:mysql://192.168.1.199:3306/database', dbtable 'database.tablename', user 'username', password 'password' );
通过 CatalogPlugin 方式访问 MySQL:
1 2 3 4 5 6 7
set spark.sql.catalog.mysql=org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCTableCatalog; set spark.sql.catalog.mysql.url=jdbc:mysql://192.168.1.199/database; set spark.sql.catalog.mysql.user=username; set spark.sql.catalog.mysql.password=password;
# 配置 clickhouse catalog set spark.sql.catalog.clickhouse=xenon.clickhouse.ClickHouseCatalog; set spark.sql.catalog.clickhouse.host=192.168.1.199; set spark.sql.catalog.clickhouse.grpc_port=9100; set spark.sql.catalog.clickhouse.user=username; set spark.sql.catalog.clickhouse.password=password; set spark.sql.catalog.clickhouse.database=database;
# 查询 clickhouse 数据 use clickhouse; select * from tablename;
开启 AQE,并通过添加 distribute by cast(rand() * 100 as int) 触发 Shuffle 操作:
1 2 3 4 5 6
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=false; set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
insert overwrite sample.catalog_returns partition (hash=0) select * from tpcds.sf300.catalog_returns distribute by cast(rand() * 100 as int);
Add repartition node at the top of query plan. An approach of merging small files.
1.2.0
spark.sql.optimizer.insertRepartitionNum
none
The partition number if spark.sql.optimizer.insertRepartitionBeforeWrite.enabled is enabled. If AQE is disabled, the default value is spark.sql.shuffle.partitions. If AQE is enabled, the default value is none that means depend on AQE.
The partition number of each dynamic partition if spark.sql.optimizer.insertRepartitionBeforeWrite.enabled is enabled. We will repartition by dynamic partition columns to reduce the small file but that can cause data skew. This config is to extend the partition of dynamic partition column to avoid skew but may generate some small files.
对于动态分区写入,会根据动态分区字段进行 Repartition,并添加一个随机数来避免产生数据倾斜,spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum 用来配置随机数的范围,不过添加随机数后,由于加大了动态分区的基数,还是可能会导致小文件。这个操作类似在 SQL 中添加 distribute by DYNAMIC_PARTITION_COLUMN, cast(rand() * 100 as int)。
静态分区写入
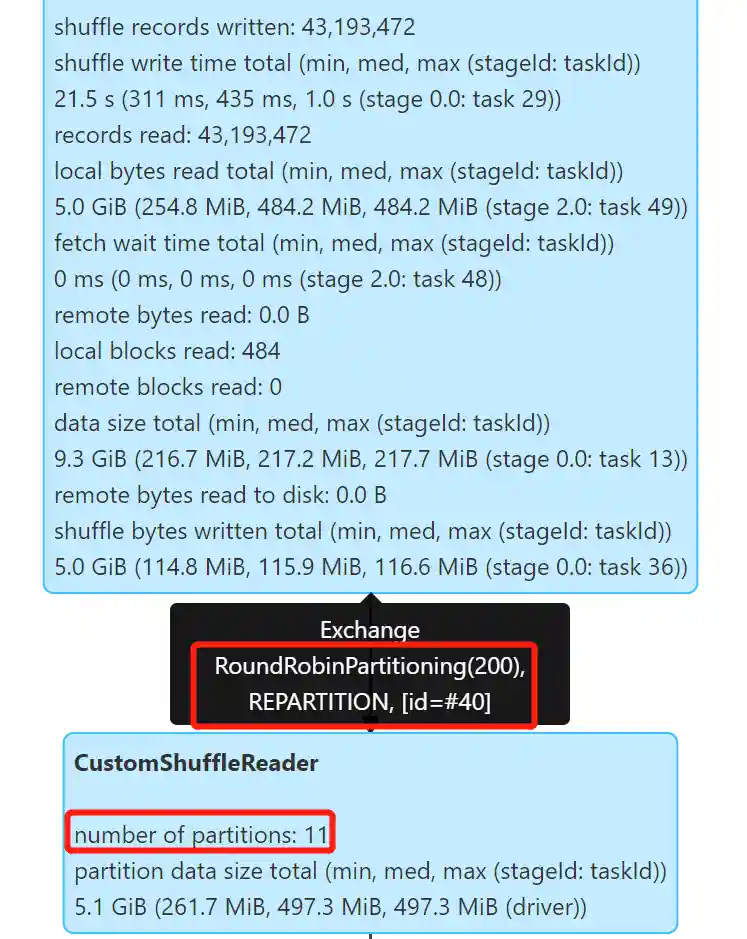
开启 Kyuubi 优化和 AQE,测试静态分区写入:
1 2 3 4 5 6 7
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true;
set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
insert overwrite sample.catalog_returns partition (hash=0) select * from tpcds.sf300.catalog_returns;
可以看到 AQE 生效了,很好的控制了小文件,产生了 11 个文件,文件大小 314.5 M 左右。
动态分区写入
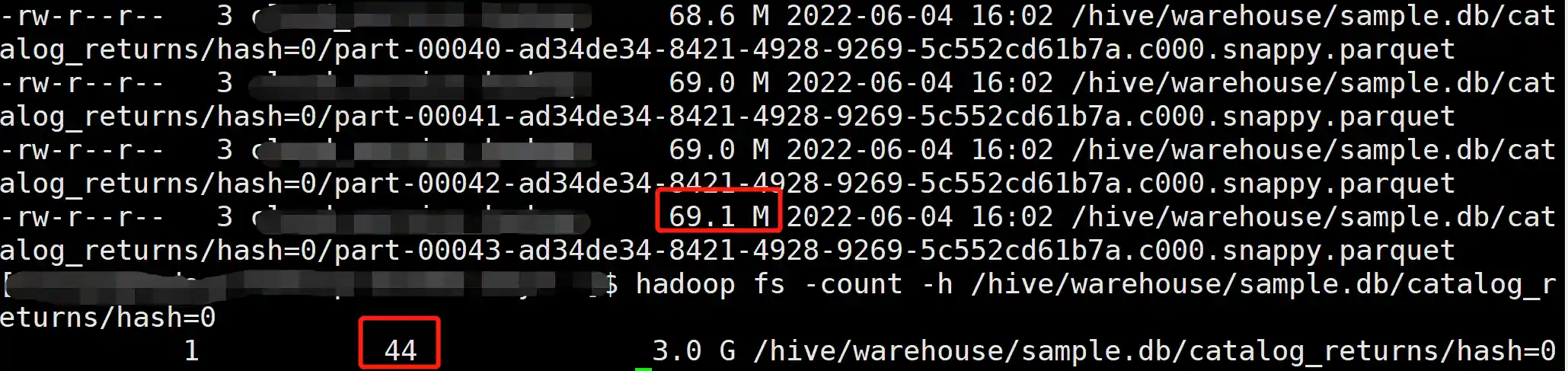
我们测试一下动态分区写入的情况,先关闭 Kyuubi 优化,并生成 10 个 hash 分区:
1 2 3
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=false;
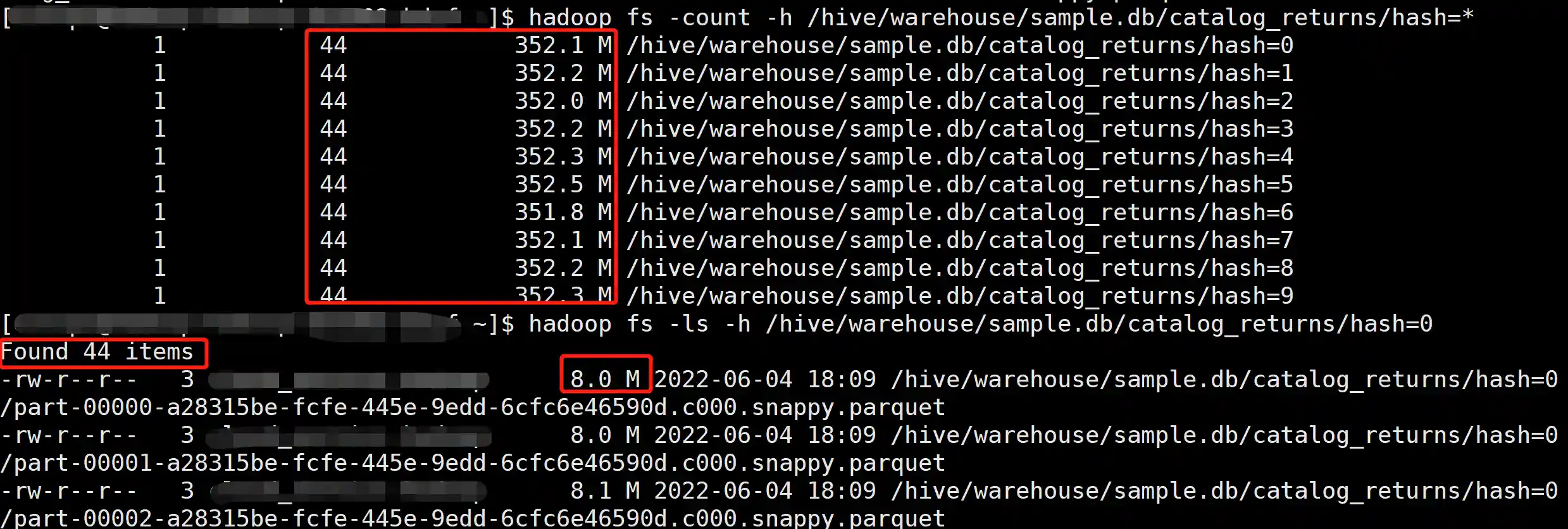
insert overwrite sample.catalog_returns partition (hash) select *, cast(rand() * 10 as int) as hash from tpcds.sf300.catalog_returns;
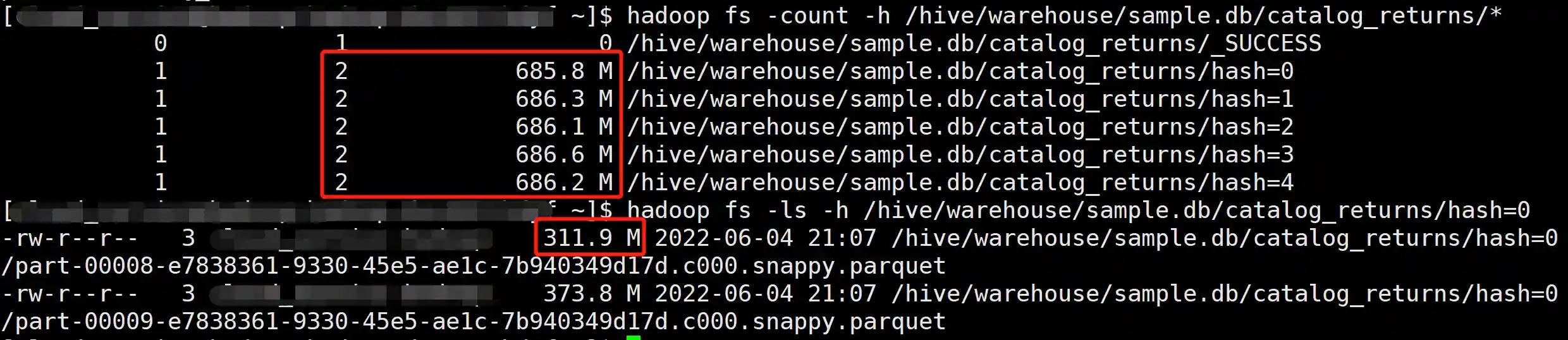
产生了 44 × 10 = 440 个文件,文件大小 8 M 左右。
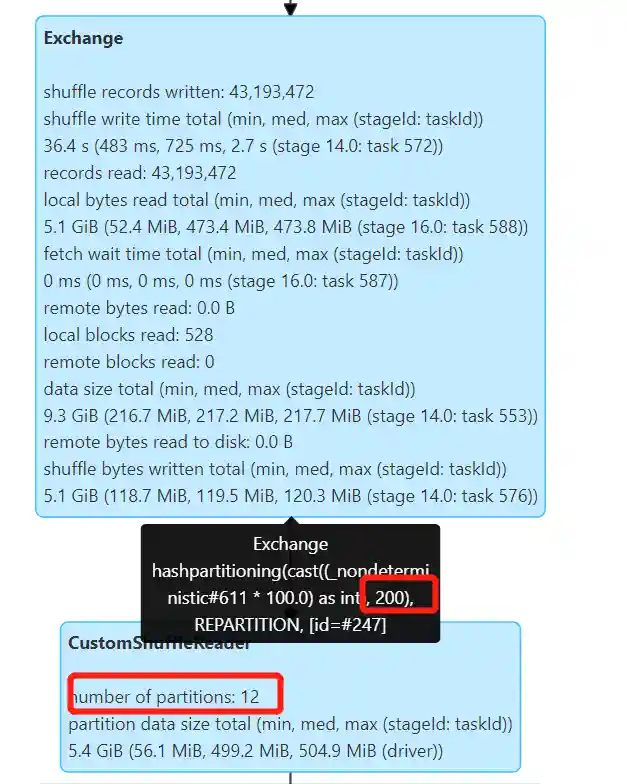
开启 Kyuubi 优化和 AQE:
1 2 3 4 5 6 7 8
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true; set spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum=100;
set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
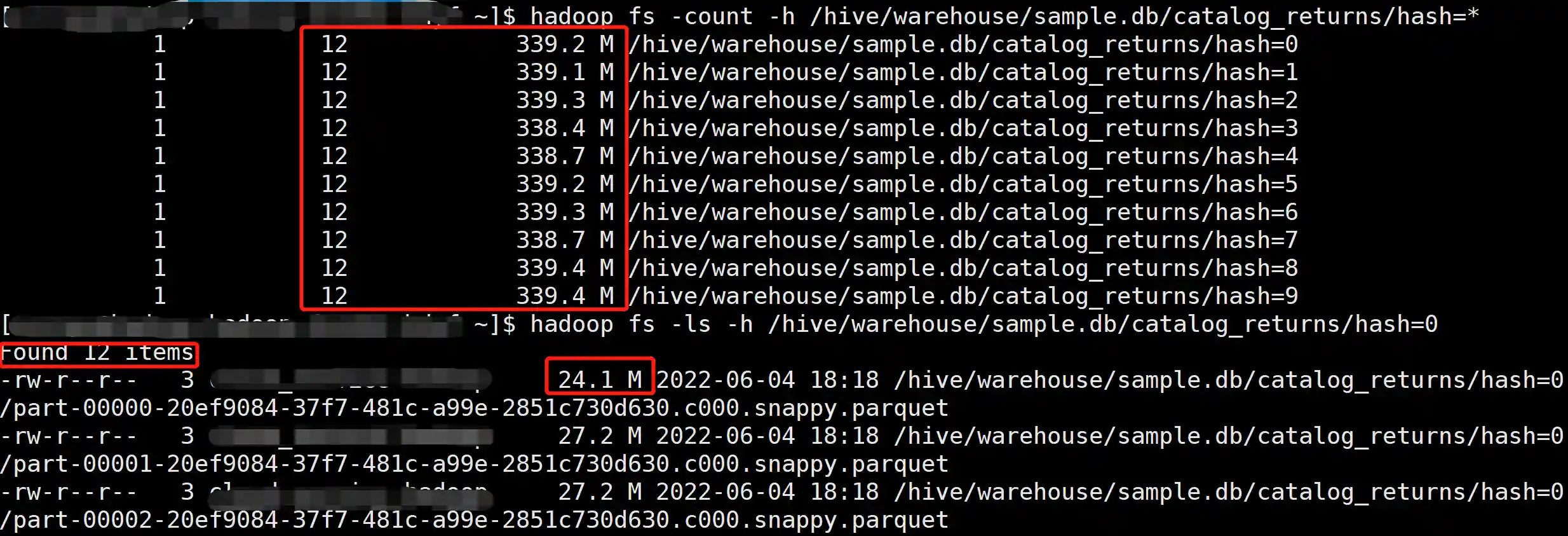
insert overwrite sample.catalog_returns partition (hash) select *, cast(rand() * 10 as int) as hash from tpcds.sf300.catalog_returns;
产生了 12 × 10 = 120 个文件,文件大小 30 M 左右,可以看到小文件有所改善,不过任然不够理想。
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true; set spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum=0;
set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
insert overwrite sample.catalog_returns partition (hash) select *, cast(rand() * 5 as int) as hash from tpcds.sf300.catalog_returns;
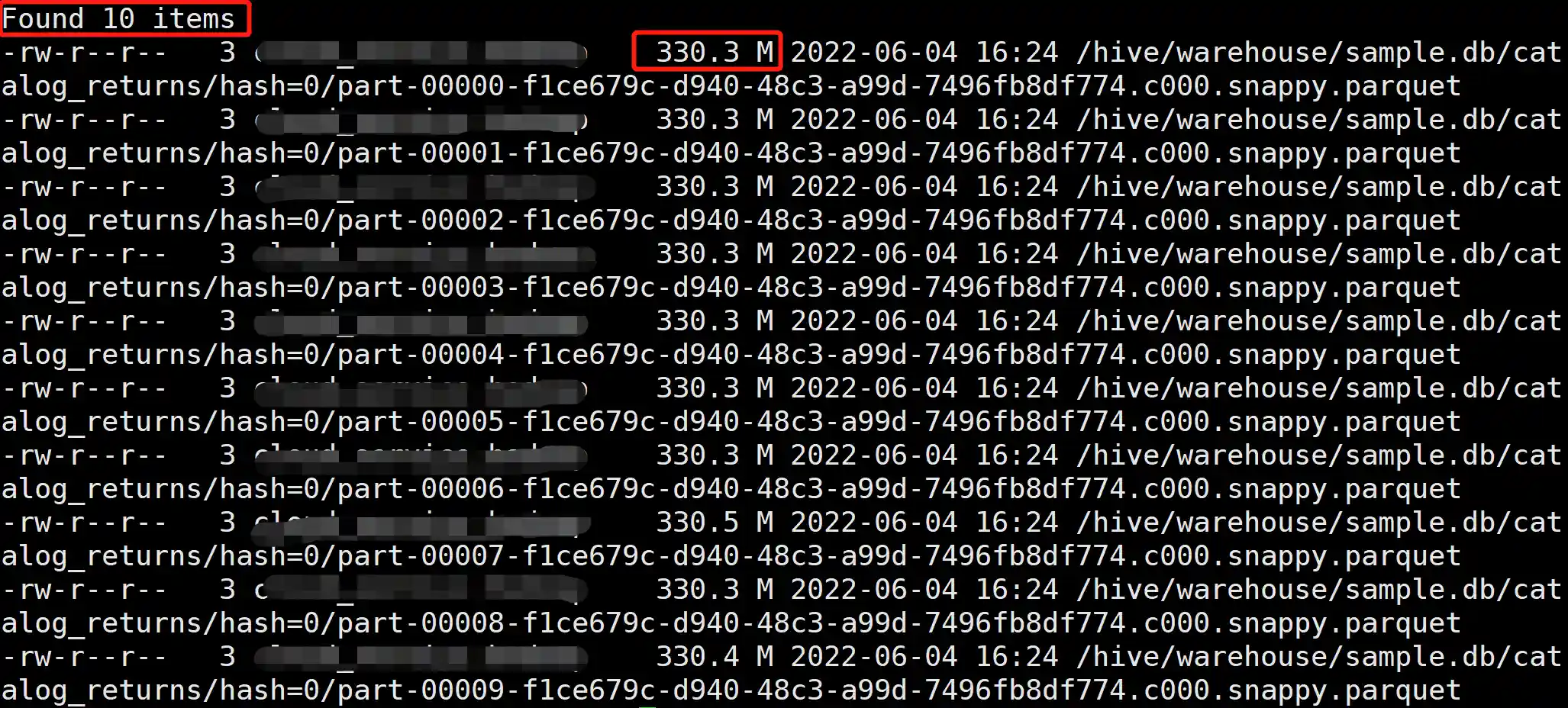
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true;
set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
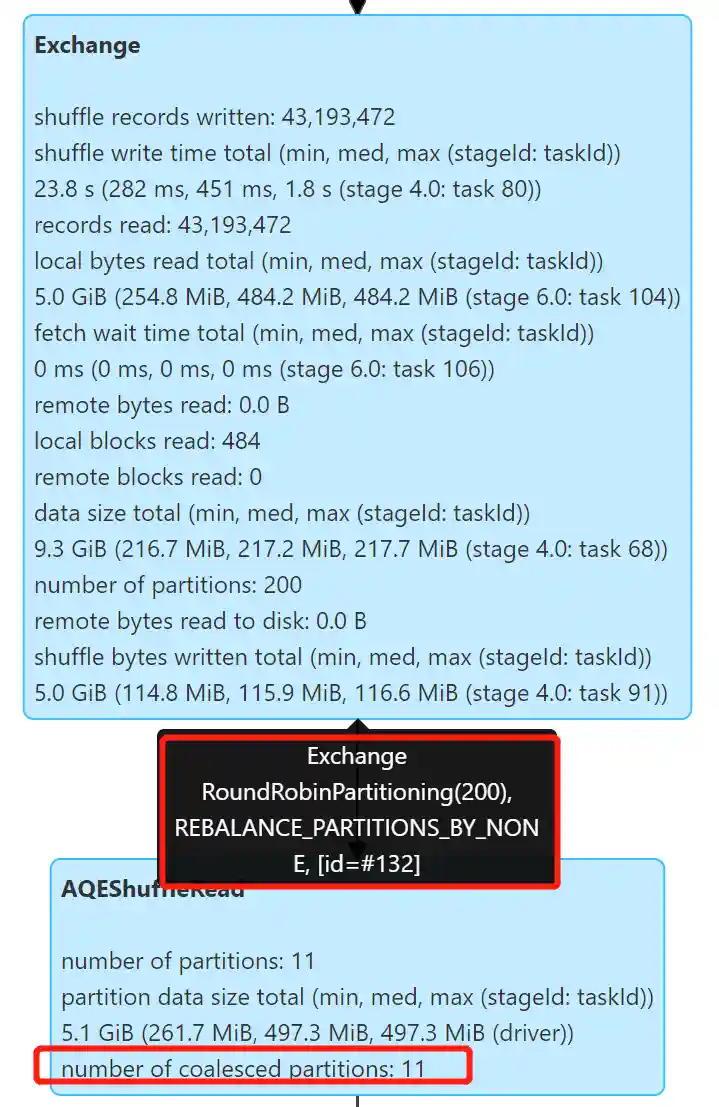
insert overwrite sample.catalog_returns partition (hash=0) select * from tpcds.sf300.catalog_returns;
Repartition 操作自动合并了小分区,产生了 11 个文件,文件大小 334.6 M 左右,解决了小文件的问题。
set spark.sql.optimizer.insertRepartitionBeforeWrite.enabled=true;
set spark.sql.adaptive.enabled=true; set spark.sql.adaptive.advisoryPartitionSizeInBytes=512M; set spark.sql.adaptive.coalescePartitions.minPartitionNum=1;
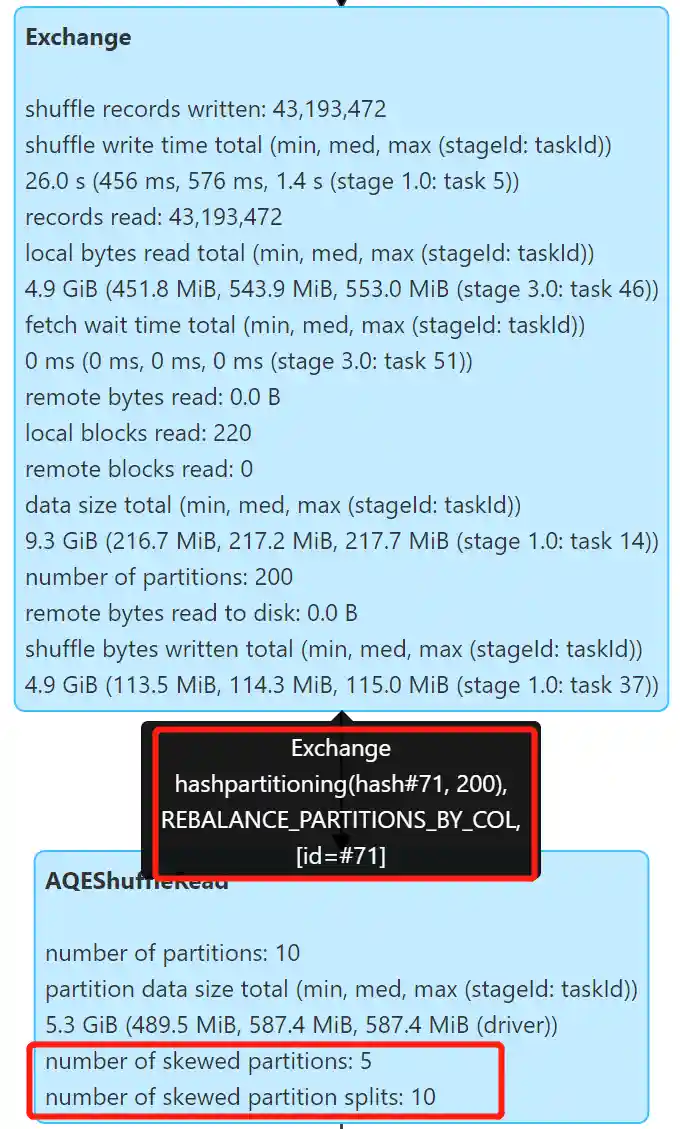
insert overwrite sample.catalog_returns partition (hash) select *, cast(rand() * 5 as int) as hash from tpcds.sf300.catalog_returns;
Kyuubi Server 中也定义了一些监控指标,用于监控 Kyuubi Server 的运行状况,支持了很多的 Reporter,包括 Prometheus,后续工作需要将指标投递到 Prometheus 中,对 Kyuubi 服务进行监控告警。具体参考: Kyuubi Server Metrics。
Kyuubi Ctl
Kyuubi 的 bin 目录中提供了 kyuubi-ctl 工具,目前主要用于维护 Server 和 Engine 实例的状态,可以获取和删除 Server 和 Engine 在 Zookeeper 上的注册信息。
目前包括了,下面一些命令,可执行 bin/kyuubi-ctl --help 获取完整帮助信息。
1 2 3 4 5 6
Command: get [server|engine] [options] Get the service/engine node info, host and port needed. Command: delete [server|engine] [options] Delete the specified service/engine node, host and port needed. Command: list [server|engine] [options] List all the service/engine nodes for a particular domain.
overridedeffindTable(options: DataSourceOptions, conf: Configuration): Table = { val path = options.get("path") val cluster = options.get("cluster") Preconditions.checkArgument(path.isPresent, "Cannot open table: path is not set".asInstanceOf[Object]) Preconditions.checkArgument(cluster.isPresent, "Cannot open table: cluster is not set".asInstanceOf[Object])
val catalog = loadClusterCatalog(cluster.get()) catalog.loadTable(tableIdentifier(path.get())) }
}
objectClusterIcebergSource{
valSHORT_NAME = "iceberg-cluster"
val catalogs: util.Map[String, Catalog] = newConcurrentHashMap[String, Catalog]()
defloadClusterCatalog(cluster: String): Catalog = { if (!catalogs.containsKey(cluster)) catalogs synchronized { if (!catalogs.containsKey(cluster)) { val hiveCatalog = newHiveCatalog() hiveCatalog.setConf(hadoopConf(cluster)) val properties = new util.HashMap[String, String]() hiveCatalog.initialize(s"iceberg_catalog_$cluster", properties) catalogs.put(cluster, hiveCatalog) } } catalogs.get(cluster) }
loadTable 时 HiveMetaStore 初始化报错,No suitable driver found for jdbc:mysql:***
1 2 3 4 5 6 7 8
java.sql.SQLException: No suitable driver found for jdbc:mysql://***:***/hive_db?createDatabaseIfNotExist=true at java.sql.DriverManager.getConnection(DriverManager.java:689) at java.sql.DriverManager.getConnection(DriverManager.java:208) at com.jolbox.bonecp.BoneCP.obtainRawInternalConnection(BoneCP.java:349) at com.jolbox.bonecp.BoneCP.<init>(BoneCP.java:416) at com.jolbox.bonecp.BoneCPDataSource.getConnection(BoneCPDataSource.java:120) at org.datanucleus.store.rdbms.ConnectionFactoryImpl$ManagedConnectionImpl.getConnection(ConnectionFactoryImpl.java:501) at org.datanucleus.store.rdbms.RDBMSStoreManager.<init>(RDBMSStoreManager.java:298)
"NotificationHookConsumer thread-40" #522 prio=5 os_prio=0 tid=0x00007f897794d000 nid=0x98e5 runnable [0x00007f69c4ecd000] java.lang.Thread.State: RUNNABLE // ...... at org.apache.tinkerpop.gremlin.structure.Vertex.property(Vertex.java:38) at org.apache.atlas.repository.graphdb.janus.AtlasJanusElement.getProperty(AtlasJanusElement.java:65) at org.apache.atlas.repository.store.graph.v2.AtlasGraphUtilsV2.getIdFromVertex(AtlasGraphUtilsV2.java:105) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToRelatedObjectId(EntityGraphRetriever.java:1025) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapRelatedVertexToObjectId(EntityGraphRetriever.java:991) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToRelationshipAttribute(EntityGraphRetriever.java:976) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapRelationshipAttributes(EntityGraphRetriever.java:944) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAtlasEntity(EntityGraphRetriever.java:418) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAtlasEntity(EntityGraphRetriever.java:395) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToObjectId(EntityGraphRetriever.java:900) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToCollectionEntry(EntityGraphRetriever.java:819) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToArray(EntityGraphRetriever.java:787) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAttribute(EntityGraphRetriever.java:709) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapAttributes(EntityGraphRetriever.java:568) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAtlasEntity(EntityGraphRetriever.java:415) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.toAtlasEntityWithExtInfo(EntityGraphRetriever.java:183) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.toAtlasEntityWithExtInfo(EntityGraphRetriever.java:178) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.toAtlasEntityWithExtInfo(EntityGraphRetriever.java:166) at org.apache.atlas.repository.converters.AtlasInstanceConverter.getAndCacheEntity(AtlasInstanceConverter.java:300) at org.apache.atlas.repository.store.graph.v2.AtlasEntityChangeNotifier.toAtlasEntities(AtlasEntityChangeNotifier.java:409) at org.apache.atlas.repository.store.graph.v2.AtlasEntityChangeNotifier.notifyV2Listeners(AtlasEntityChangeNotifier.java:305) at org.apache.atlas.repository.store.graph.v2.AtlasEntityChangeNotifier.notifyListeners(AtlasEntityChangeNotifier.java:275) at org.apache.atlas.repository.store.graph.v2.AtlasEntityChangeNotifier.onEntitiesMutated(AtlasEntityChangeNotifier.java:108) at org.apache.atlas.repository.store.graph.v2.AtlasEntityStoreV2.createOrUpdate(AtlasEntityStoreV2.java:732) at org.apache.atlas.repository.store.graph.v2.AtlasEntityStoreV2.createOrUpdate(AtlasEntityStoreV2.java:253) // ...... "NotificationHookConsumer thread-11" #464 prio=5 os_prio=0 tid=0x00007f8977919000 nid=0x98c8 runnable [0x00007f69c6beb000] java.lang.Thread.State: RUNNABLE // ...... at org.apache.tinkerpop.gremlin.structure.Vertex.property(Vertex.java:72) at org.apache.tinkerpop.gremlin.structure.Vertex.property(Vertex.java:38) at org.apache.atlas.repository.graphdb.janus.AtlasJanusElement.getProperty(AtlasJanusElement.java:65) at org.apache.atlas.repository.graph.GraphHelper.getTypeName(GraphHelper.java:1090) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapSystemAttributes(EntityGraphRetriever.java:1121) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapEdgeToAtlasRelationship(EntityGraphRetriever.java:1080) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapEdgeToAtlasRelationship(EntityGraphRetriever.java:1070) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToRelatedObjectId(EntityGraphRetriever.java:1033) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapRelationshipArrayAttribute(EntityGraphRetriever.java:1010) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToRelationshipAttribute(EntityGraphRetriever.java:981) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapRelationshipAttributes(EntityGraphRetriever.java:944) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAtlasEntity(EntityGraphRetriever.java:418) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.mapVertexToAtlasEntity(EntityGraphRetriever.java:395) at org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever.toAtlasEntity(EntityGraphRetriever.java:162) at org.apache.atlas.repository.store.graph.v2.AtlasEntityStoreV2.createOrUpdate(AtlasEntityStoreV2.java:699) at org.apache.atlas.repository.store.graph.v2.AtlasEntityStoreV2.createOrUpdate(AtlasEntityStoreV2.java:253) // ......