Xuan Wang
I am now a scientific researcher in Interaction Intelligence Lab, Ant Research. Prior to this, I was a senior researcher, leading the projects of neural rendering and 2D avatar in Tencent AI Lab. I recieved Ph.D. degree from School of Computer Science and Technology, Xi’an Jiaotong University in 2019 under the supervision of Prof. Fei Wang and Prof. Jizhong Zhao. I was a visiting student at NICTA in 2015 supervised by Dr. Mathieu Salzmann. I received Master degree from School of Software Engineering, Xi’an Jiaotong University in 2010, and received Bachelor degree from Department of Computer Science and Technology, Xi’an University of Science and Technology in 2007. My research interests include neural rendering(e.g. NeRF), non-rigid 3d reconstruction, performance capture, image synthesis and relevant applications. At present, we attempt to create the highly photorealistic and fully controllable digital content including human avatar and scenarios.
👩🎓🧑🎓 Internship at Interatcion Intelligence Lab, Ant Research. I am looking for the research interns to work on neural rendering (e.g. NeRF), image synthesis and digital avatars. Feel free to contact me!
🔈 Positions at Xi’an Jiaotong University. Assoc. Prof. Yu Guo, one of my co-authors, is looking for PH.D students, master students, resreach assistants and engineers. Please visit his personal homepage to get more details.
If you like the template of this homepage, welcome to star and fork Yi Ren’s open-sourced template version AcadHomepage .
🔥 News
- 2025.07: 🎉🎉 4 papers (with 1 Oral paper) accepted to ICCV 2025
- 2025.02: 🎉🎉 5 papers (with 1 Highlight paper) accepted to CVPR 2025
- 2023.07: 🎉🎉 1 paper accepted to ICCV 2023
- 2023.05: 🎉🎉 1 paper accepted to SIGGRAPH 2023
- 2023.03: 🎉🎉 8 papers (with 1 Highlight paper) accepted to CVPR 2023
📝 Selected Publications
Equal contribution$^\star$ Corresponding author$^\dagger$
Papers in 2025
ICCV 2025 (Oral)
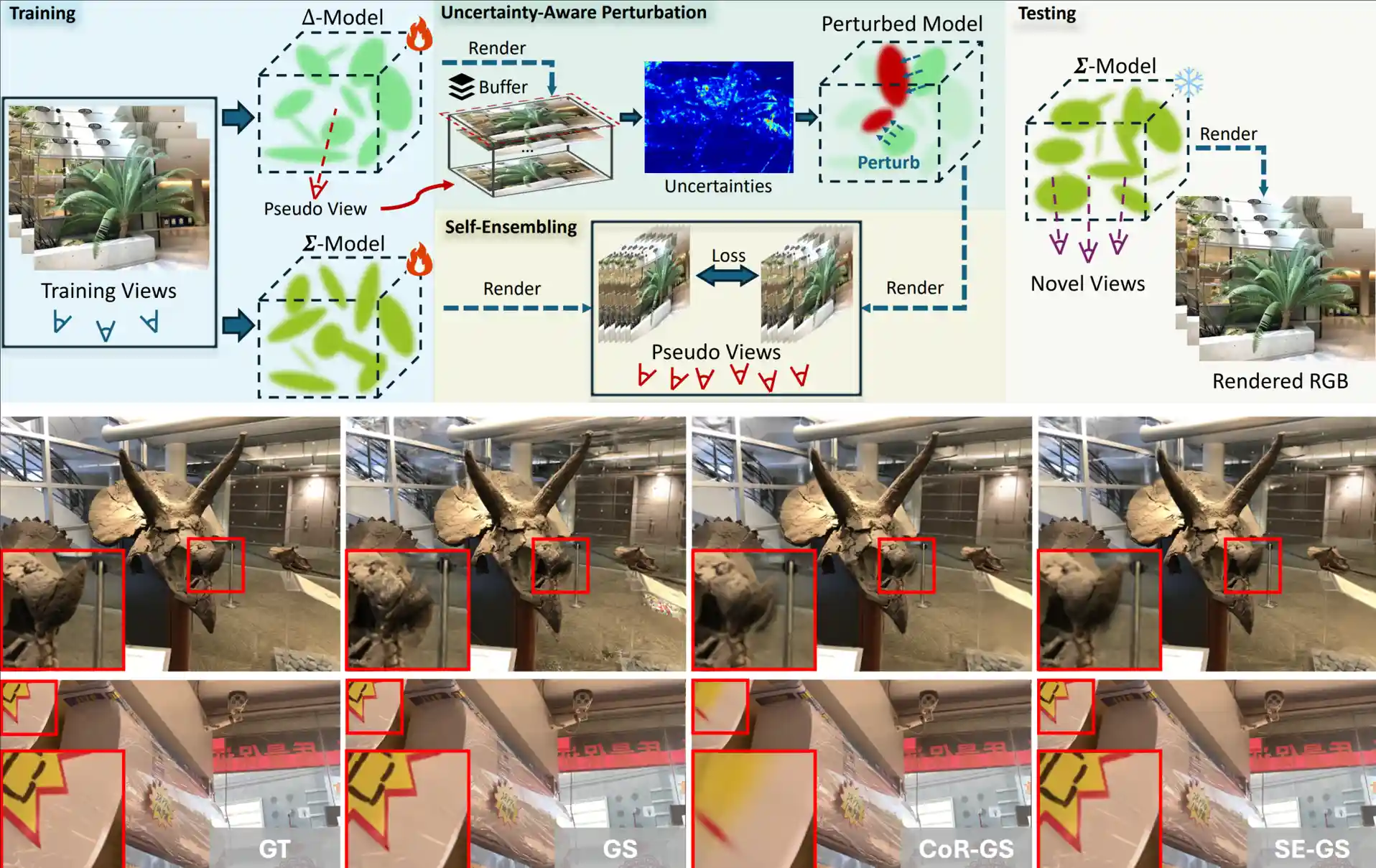
Self-Ensembling Gaussian Splatting for Few-Shot Novel View Synthesis
Chen Zhao, Xuan Wang, Tong Zhang, Saqib Javed, Mathieu Salzmann
Project |
- We observe that 3D Gaussian Splatting (3DGS) excels in novel view synthesis (NVS) but overfits with sparse views, so we propose Self-Ensembling Gaussian Splatting (SE-GS) using an uncertainty-aware perturbation strategy to train a main model alongside perturbed models. We minimize discrepancies between these models to form a robust ensemble for novel-view generation.
ICCV 2025

Yuan Sun, Xuan Wang, Cong Wang, WeiLi Zhang, Yanbo Fan, Yu Guo, Fei Wang
- 3D Gaussian-based head avatar modeling performs well with enough data, but prior-based methods lack rendering quality due to limited identity-shared representation power. We solve this via joint reconstruction and registration of prior-based and prior-free 3D Gaussians, merging and post-processing for complete avatars, with experiments showing better quality and high-resolution support.
ICCV 2025

Yudong Jin, Sida Peng, Xuan Wang, Tao Xie, Zhen Xu, Yifan Yang, Yujun Shen, Hujun Bao, Xiaowei Zhou
Project |
- This paper addresses high-fidelity novel-view synthesis from sparse-view human videos. While 4D diffusion models tackle limited observations, they lack spatio-temporal consistency, so we propose a sliding iterative denoising process on a latent grid (encoding image, camera and human poses) via alternating spatial-temporal denoising, enabling sufficient information flow and affordable GPU memory.
ICCV 2025

DGTalker: Disentangled Generative Latent Space Learning for Audio-Driven Gaussian Talking Heads
Xiaoxi Liang, Yanbo Fan, Qiya Yang, Xuan Wang, Wei Gao, Ge Li
- In this work, we investigate generating high-fidelity, audio-driven 3D Gaussian talking heads from monocular videos, presenting DGTalker—a real-time, high-fidelity, 3D-aware framework that uses Gaussian generative priors and latent space navigation to alleviate 3D information lack and overfitting issues. We propose a disentangled latent space navigation framework for precise lip and expression control, plus masked cross-view supervision for robust learning. Extensive experiments show DGTalker outperforms state-of-the-art methods in visual quality, motion accuracy, and controllability.
CVPR 2025
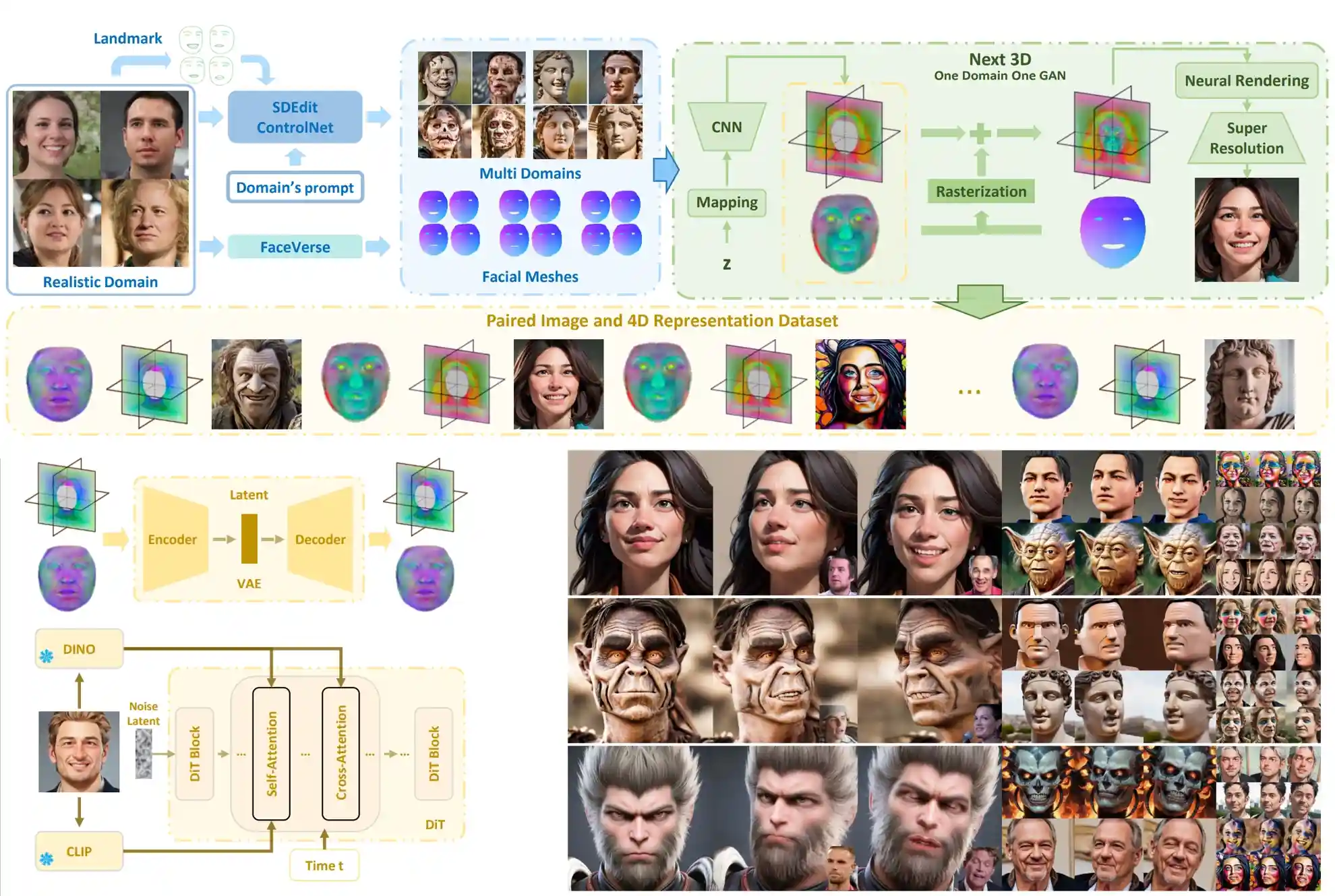
AvatarArtist: Open-Domain 4D Avatarization
Hongyu Liu, Xuan Wang$^\dagger$, Ziyu Wan, Yue Ma, Jingye Chen, Yanbo Fan, Yujun Shen, Yibing Song, Qifeng Chen$^\dagger$
Project |
- This work focuses on open-domain 4D avatarization, with the purpose of creating a 4D avatar from a portrait image in an arbitrary style. Extensive experiments suggest that our model, termed AvatarArtist, is capable of producing high-quality 4D avatars with strong robustness to various source image domains.
CVPR 2025

HERA: Hybrid Explicit Representation for Ultra-Realistic Head Avatars
Hongrui Cai$^\star$, Yuting Xiao$^\star$, Xuan Wang$^\dagger$, Jiafei Li, Yudong Guo, Yanbo Fan, Shenghua Gao, Juyong Zhang$^\dagger$
- We present a hybrid explicit representation to combine the strengths of different geometric primitives, which adaptively models rich texture on smooth surfaces as well as complex geometric structures simultaneously.
- To avoid artifacts created by facet-crossing Gaussian splats, we design a stable depth sorting strategy based on the rasterization results of the mesh and 3DGS.
- We incorporate the proposed hybrid explicit representation into modeling 3D head avatars, which render more fidelity images in real time.
Papers in 2024
ECCV 2024

Real-time 3d-aware portrait editing from a single image
Qingyan Bai, Zifan Shi, Yinghao Xu, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, Qifeng Chen
- This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner.
SIGGRAPH 2024 (Conf)
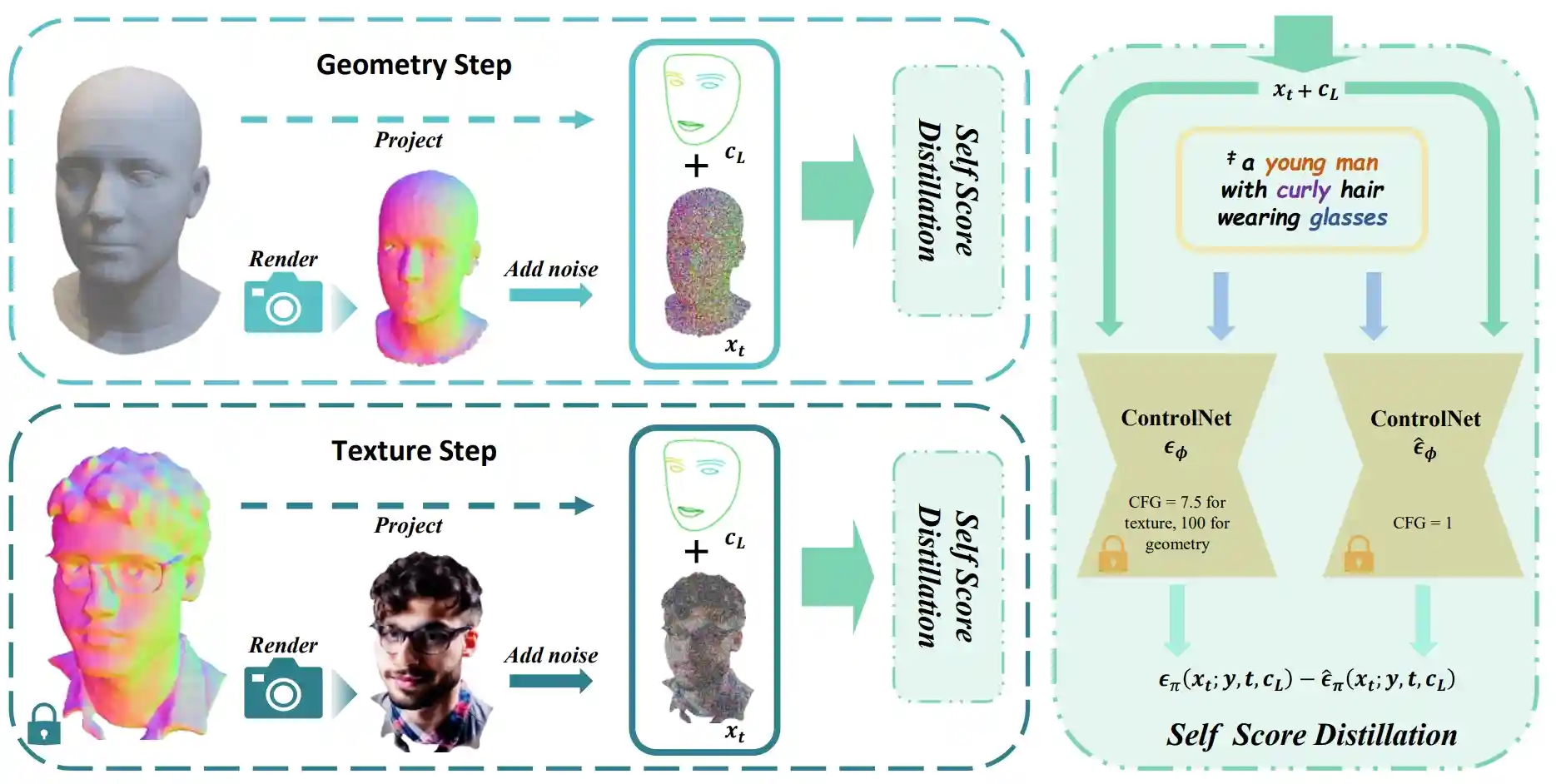
HeadArtist: Text-conditioned 3d head generation with self score distillation
Hongyu Liu, Xuan Wang$^\dagger$, Ziyu Wan, Yujun Shen, Yibing Song, Jing Liao, Qifeng Chen$^\dagger$
Project |
- We present HeadArtist for 3D head generation following human-language descriptions. With a landmark-guided ControlNet serving as a generative prior, we come up with an efficient pipeline that optimizes a parameterized 3D head model under the supervision of the prior distillation itself. We call such a process self score distillation (SSD).
Papers in 2023
ICCV 2023
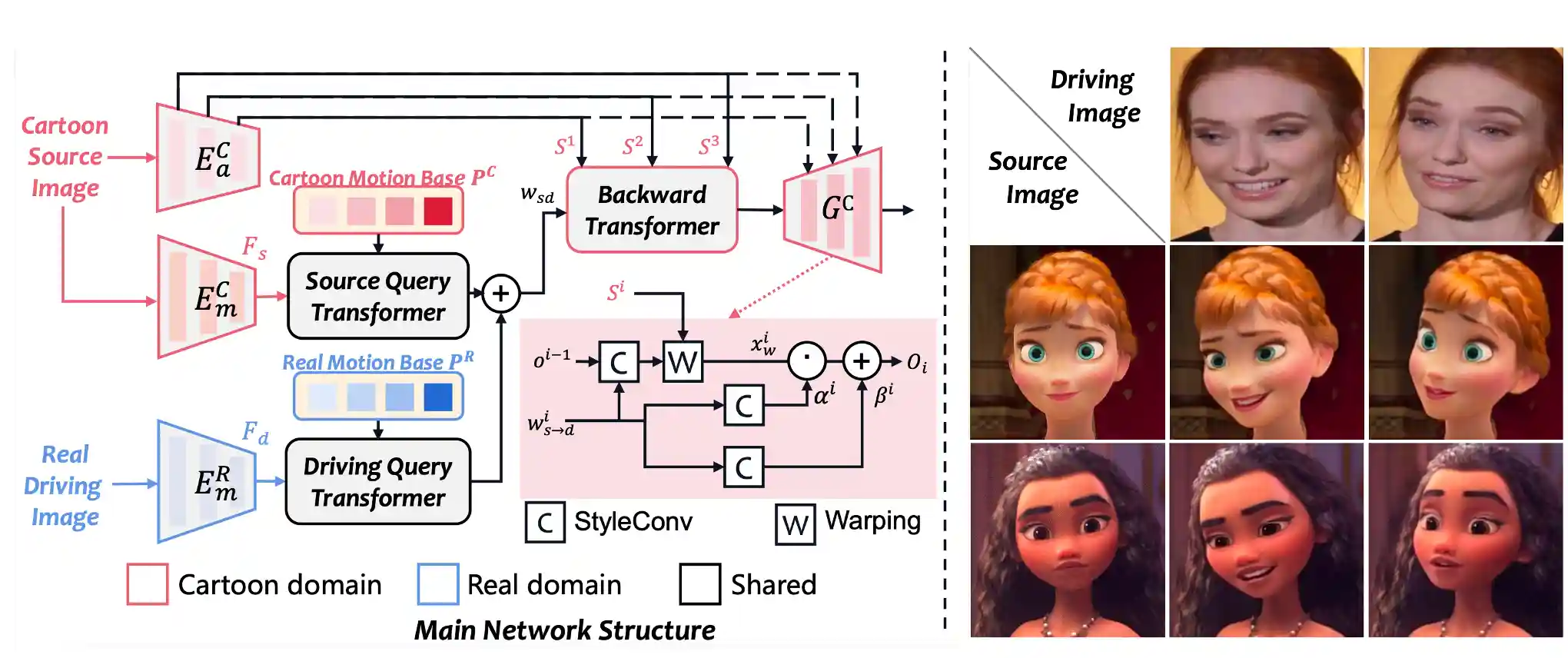
ToonTalker: Cross-Domain Face Reenactment
Yuan Gong, Yong Zhang, Xiaodong Cun, Fei Yin, Yanbo Fan, Xuan Wang, Baoyuan Wu, Yujiu Yang
- We propose a novel method for cross-domain reenactment without paired data.
SIGGRAPH 2023 (Conf)

NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Wangbo Yu, Yanbo Fan$^\dagger$, Yong Zhang$^\dagger$, Xuan Wang$^\dagger$, Fei Yin, Yunpeng Bai, Yan-Pei Cao, Ying Shan, Yang Wu, Zhongqian Sun, Baoyuan Wu
- We propose a one-shot 3D facial avatar reconstruction framework, which only requires a single source image to reconstruct high-fidelity 3D facial avatar, by leveraging the rich generative prior of 3D GAN and developing an efficient encoder-decoder network.
CVPR 2023 (Highlight)
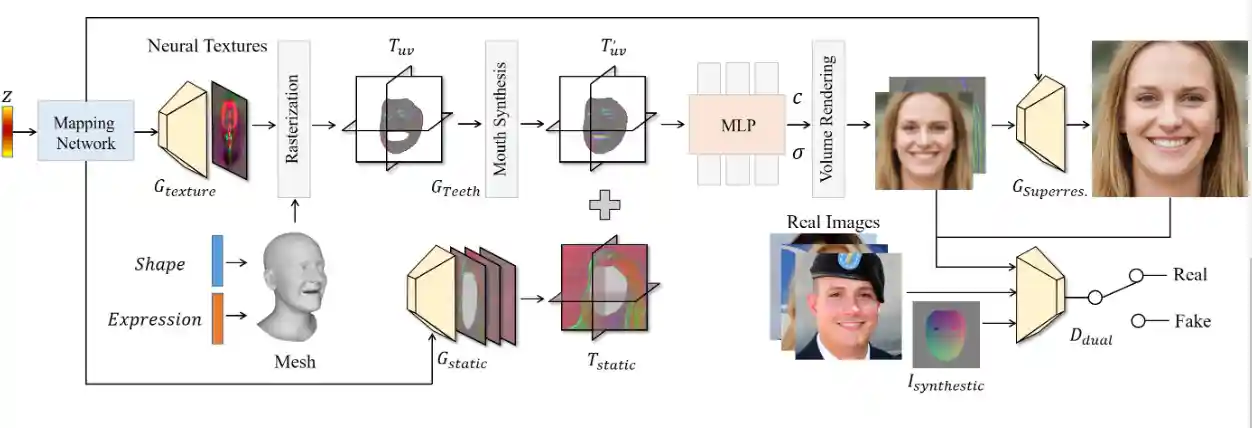
Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
Jingxiang Sun, Xuan Wang, Lizhen Wang, Xiaoyu Li, Yong Zhang, Hongwen Zhang, Yebin Liu
Project |
- We propose a 3D representation called Generative Texture-Rasterized Tri-planes that learns Generative Neural Textures on top of parametric mesh templates and then projects them into three orthogonal-viewed feature planes through rasterization, forming a tri-plane feature representation for volume rendering.
CVPR 2023

High-fidelity Facial Avatar Reconstruction from Monocular Video with Generative Priors
Yunpeng Bai, Yanbo Fan, Xuan Wang, Yong Zhang, Jingxiang Sun, Chun Yuan, Ying Shan
- We propose a new method for NeRF-based facial avatar reconstruction that utilizes 3D-aware generative prior. Different from existing works that depend on a conditional deformation field for dynamic modeling, we propose to learn a personalized generative prior, which is formulated as a local and low dimensional subspace in the latent space of 3D-GAN.
CVPR 2023
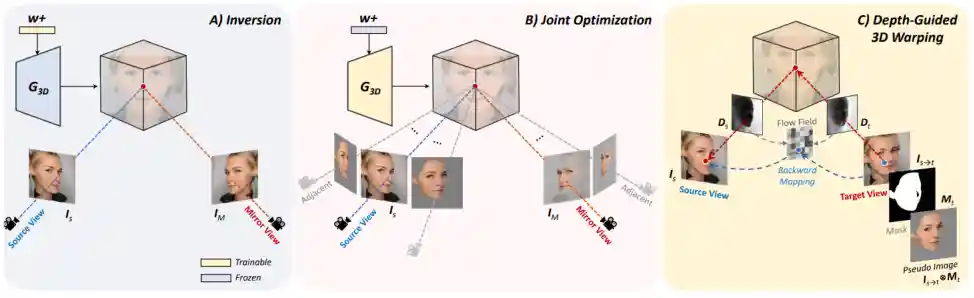
3D GAN Inversion with Facial Symmetry Prior
Fei Yin, Yong Zhang, Xuan Wang, Tengfei Wang, Xiaoyu Li, Yuan Gong, Yanbo Fan, Xiaodong Cun, Ying Shan, Cengiz Oztireli, Yujiu Yang
Project |
- We propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior.
CVPR 2023

High-Fidelity Clothed Avatar Reconstruction from a Single Image
Tingting Liao, Xiaomei Zhang, Yuliang Xiu, Hongwei Yi, Xudong Liu, Guo-Jun Qi, Yong Zhang, Xuan Wang, Xiangyu Zhu, Zhen Lei
- By combining the advantages of the high accuracy of optimization-based methods and the efficiency of learning-based methods, we propose a coarse-tofine way to realize a high-fidelity clothed avatar reconstruction (CAR) from a single image.
Papers in 2022
SIGGRAPH Asia 2022 (Conf)

VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Kun Cheng, Xiaodong Cun, Yong Zhang, Menghan Xia, Fei Yin, Mingrui Zhu, Xuan Wang, Jue Wang, Nannan Wang
Project | 🔥
- VideoReTalking, a new system to edit the faces of a real-world talking head video according to an input audio, producing a high-quality and lip-syncing output video even with a different emotion.
ECCV 2022

StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, Yujiu Yang
Project |
- We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing.
CVPR 2022

HDR-NeRF: High Dynamic Range Neural Radiance Fields
Xin Huang, Qi Zhang, Ying Feng, Hongdong Li, Xuan Wang, Qing Wang
Project |
- High Dynamic Range Neural Radiance Fields (HDR-NeRF) to recover an HDR radiance field from a set of low dynamic range (LDR) views with different exposures.