Yutong Bai
I aim to build intelligent systems from first principles: systems that do not merely fit patterns or follow instructions, but that gradually develop structure, abstraction, and behavior through learning itself.
I'm interested in how intelligence emerges, not from handcrafted pipelines or task-specific heuristics, but from exposure to behaviorally rich, understructured environments, where models must learn what to attend to, how to reason, and how to improve. This requires designing learning systems that are not narrowly optimized for a goal, but that can self-organize and grow increasingly competent through interaction, experience, and computation.
I see scale as a tool, but not as the whole solution. Larger models open up more capacity, but what fills that capacity—and how it forms—is just as important. My research explores how we can use scale to amplify the right signals: not just data quantity, but the structural richness of behavior, and the dynamics of learning itself.
To that end, I focus on:
- Understanding what makes behavior intelligent, especially when it's easy for humans but hard for machines;
- Designing systems that learn internal structure from raw behavioral input, without task scaffolds or dense supervision;
- Creating conditions where models discover abstraction and reasoning, not because they are explicitly told to—but because learning leads them there.
I believe intelligence is not something we can fully define or supervise in advance—it must emerge over time, shaped by data, computation, and inductive processes inside the model. My work is an attempt to understand and enable that emergence.
Publications
( show selected / show all by date / show all by topic )
|
Whole-Body Conditioned Egocentric Video Prediction
|
|
|
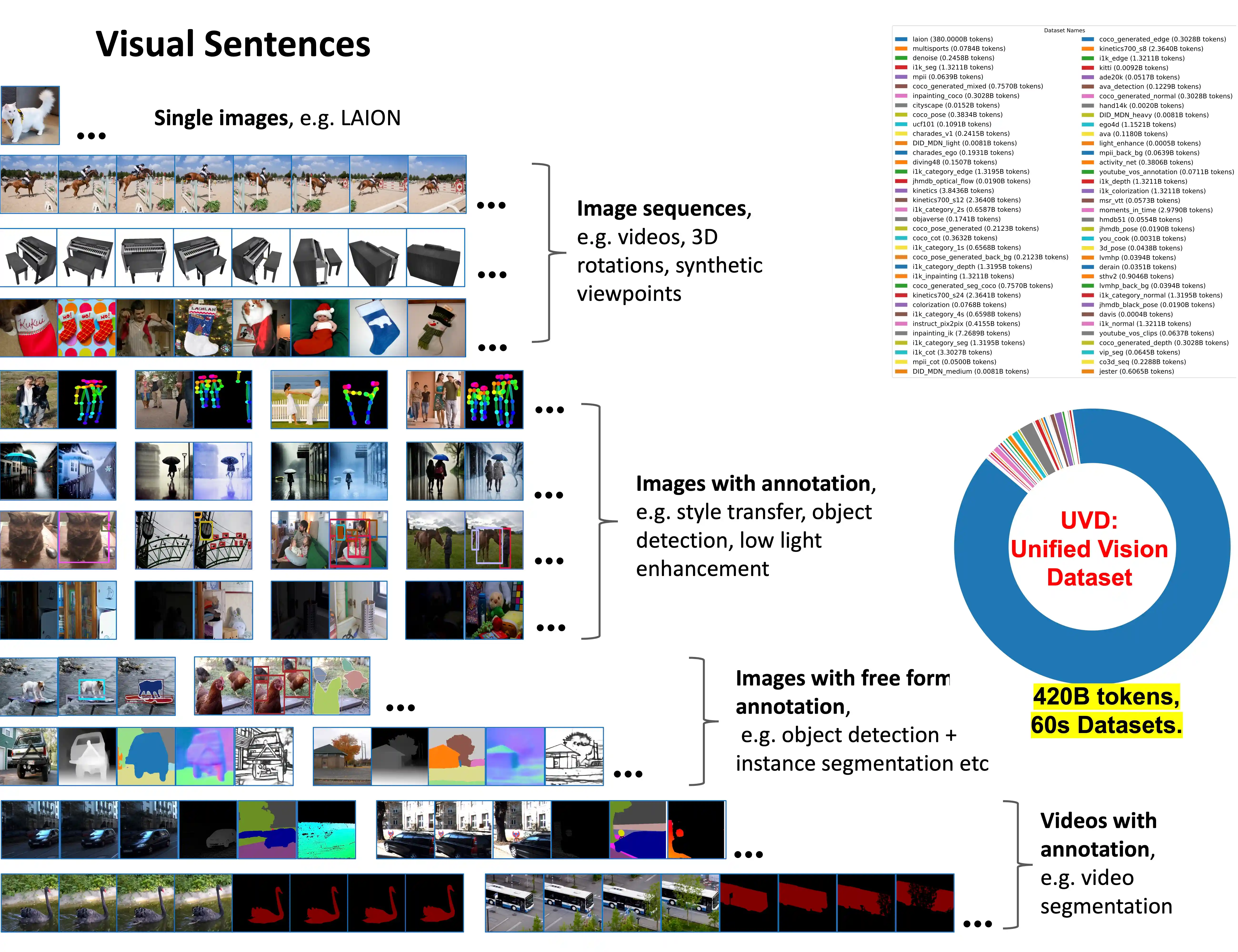
Sequential Modeling Enables Scalable Learning for Large Vision Models
paper / project page / code / model |
|
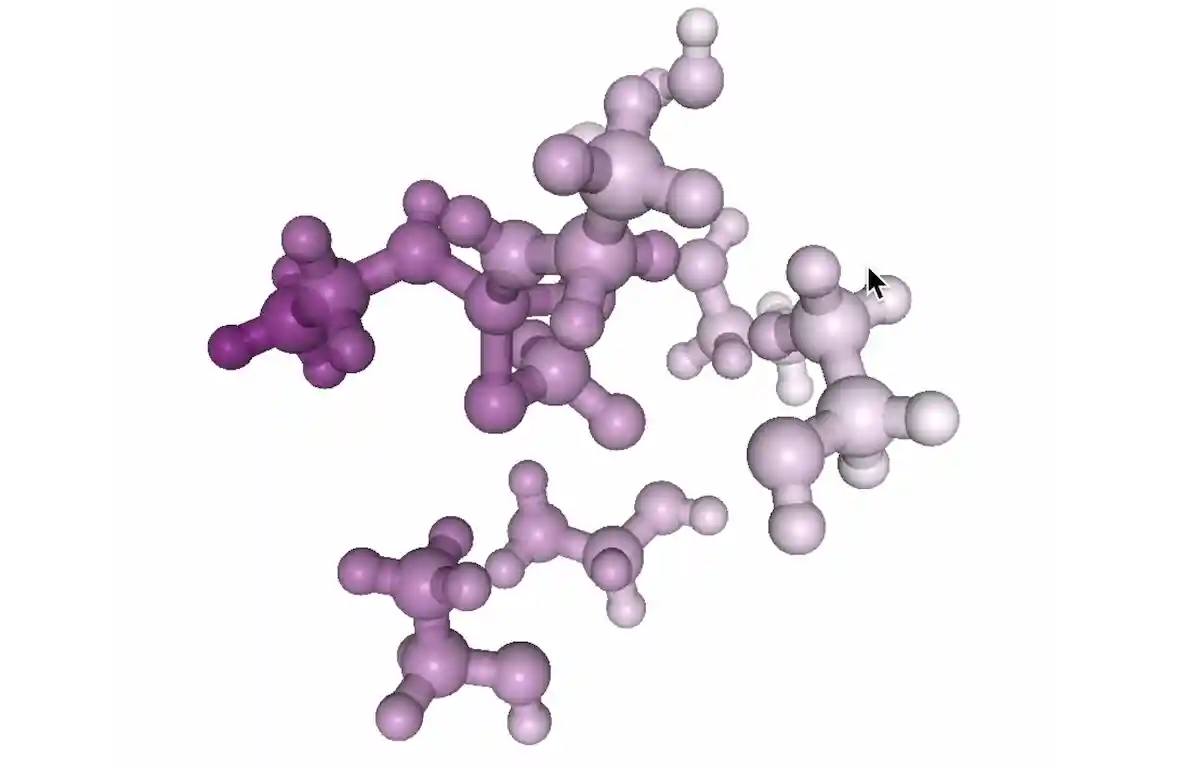
Transformers Discover Molecular Structure Without Graph Priors
|

|
The Serial Scaling Hypothesis
|

|
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset and World Model for Autonomy
paper / project page / data / code / model |
|
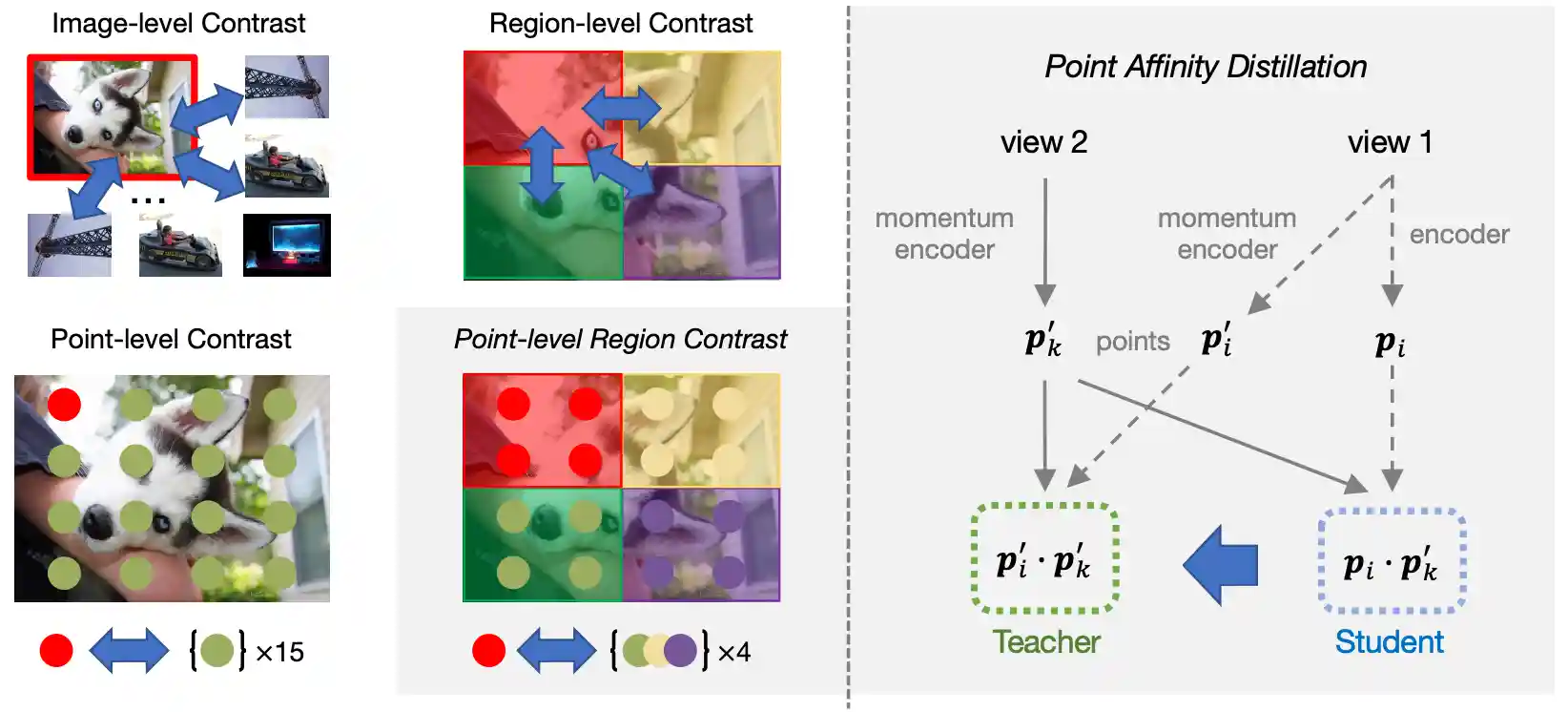
Point-Level Region Contrast for Object Detection Pre-Training
|
|
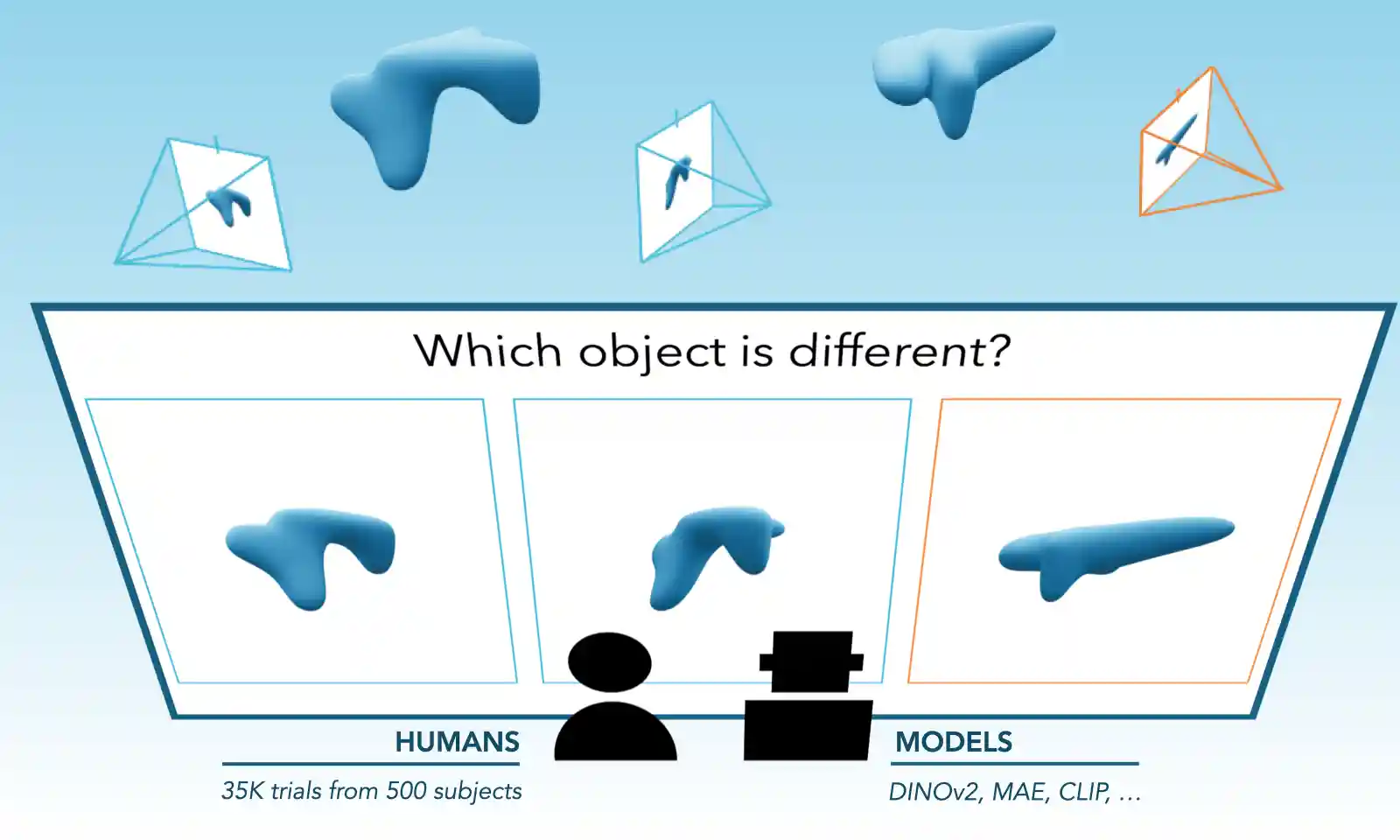
Evaluating Multiview Object Consistency in Humans and Image Models
paper / project page / code / data |

|
Intriguing Properties of Text-guided Diffusion Models
|
|
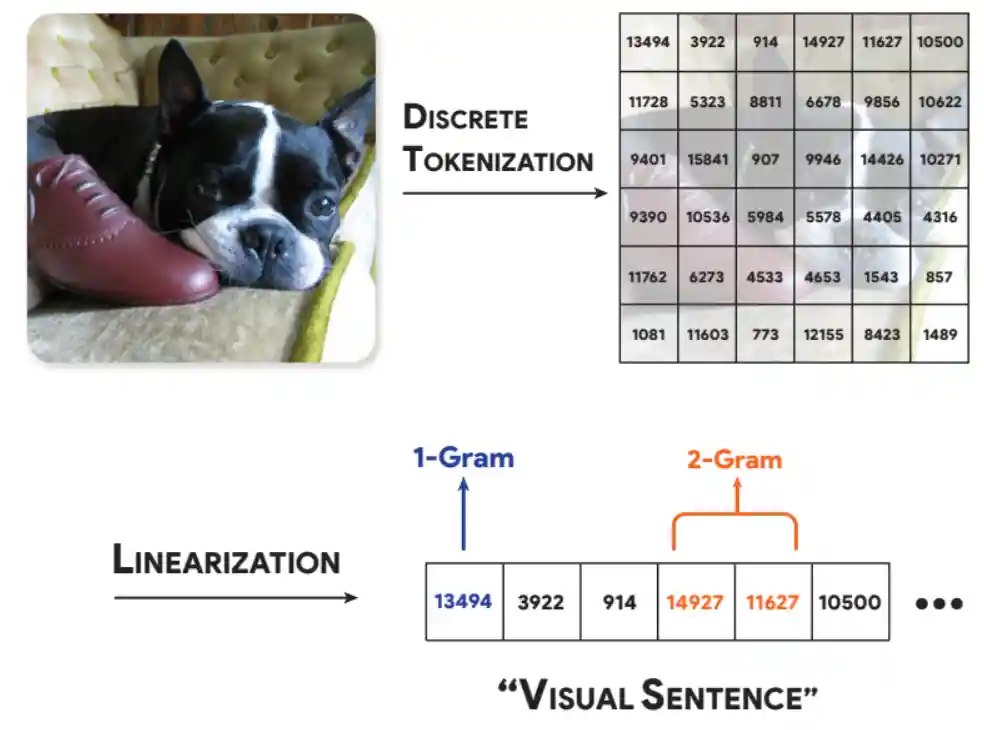
Analyzing The Language of Visual Tokens
|
|
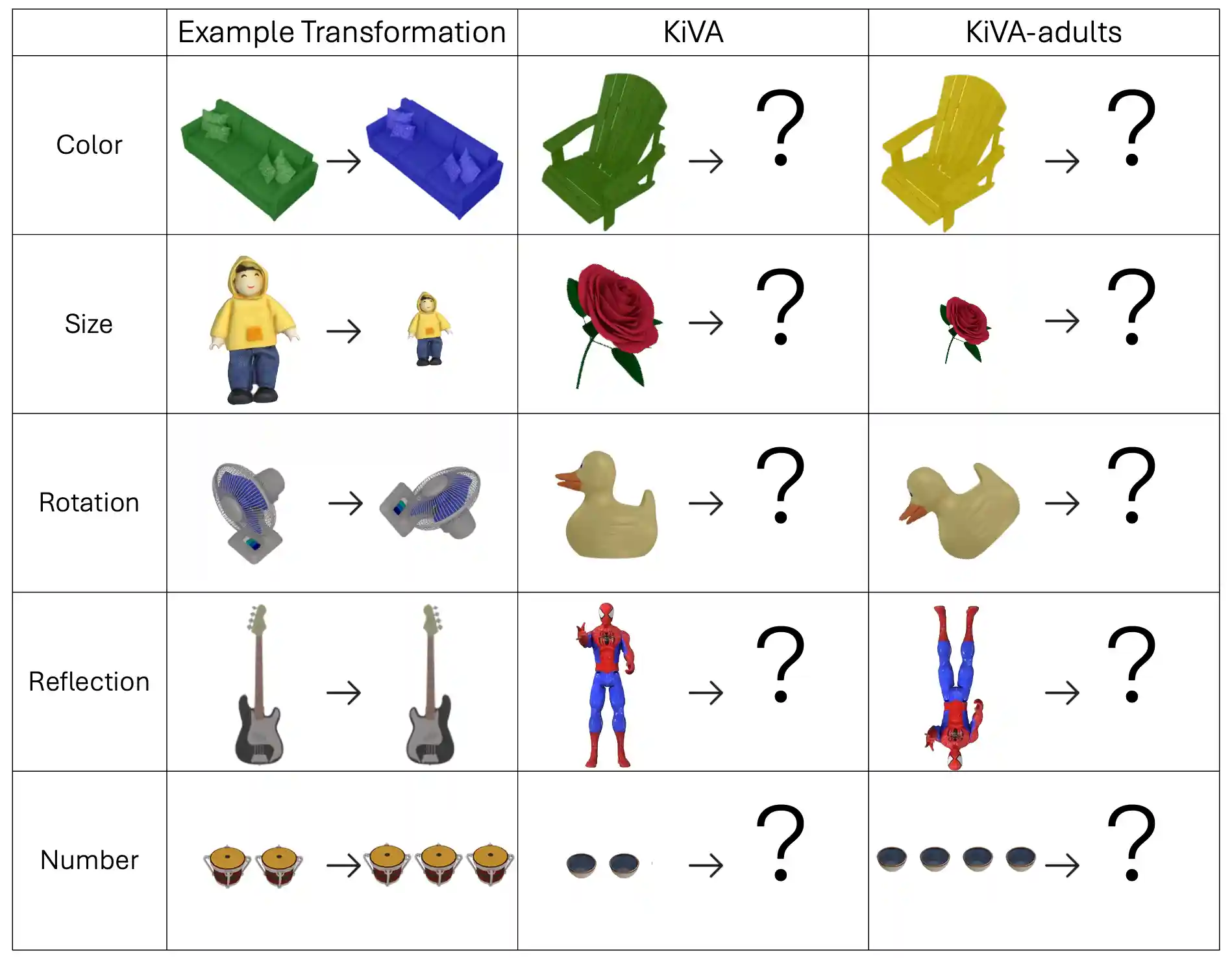
KiVA: Kid-inspired Visual Analogies for Testing Large Multimodal Models
paper / project page / code |
|
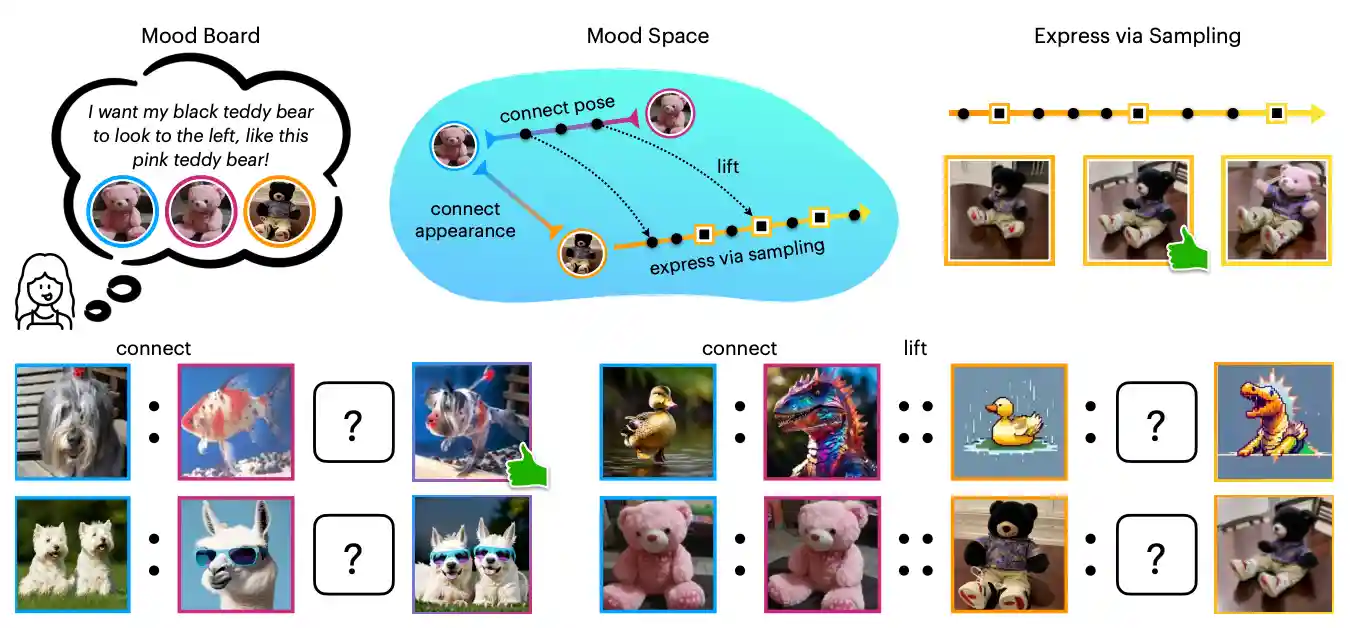
"I Know It When I See It": Mood Spaces for Connecting and Expressing Visual Concepts
paper / project page / demo |
|
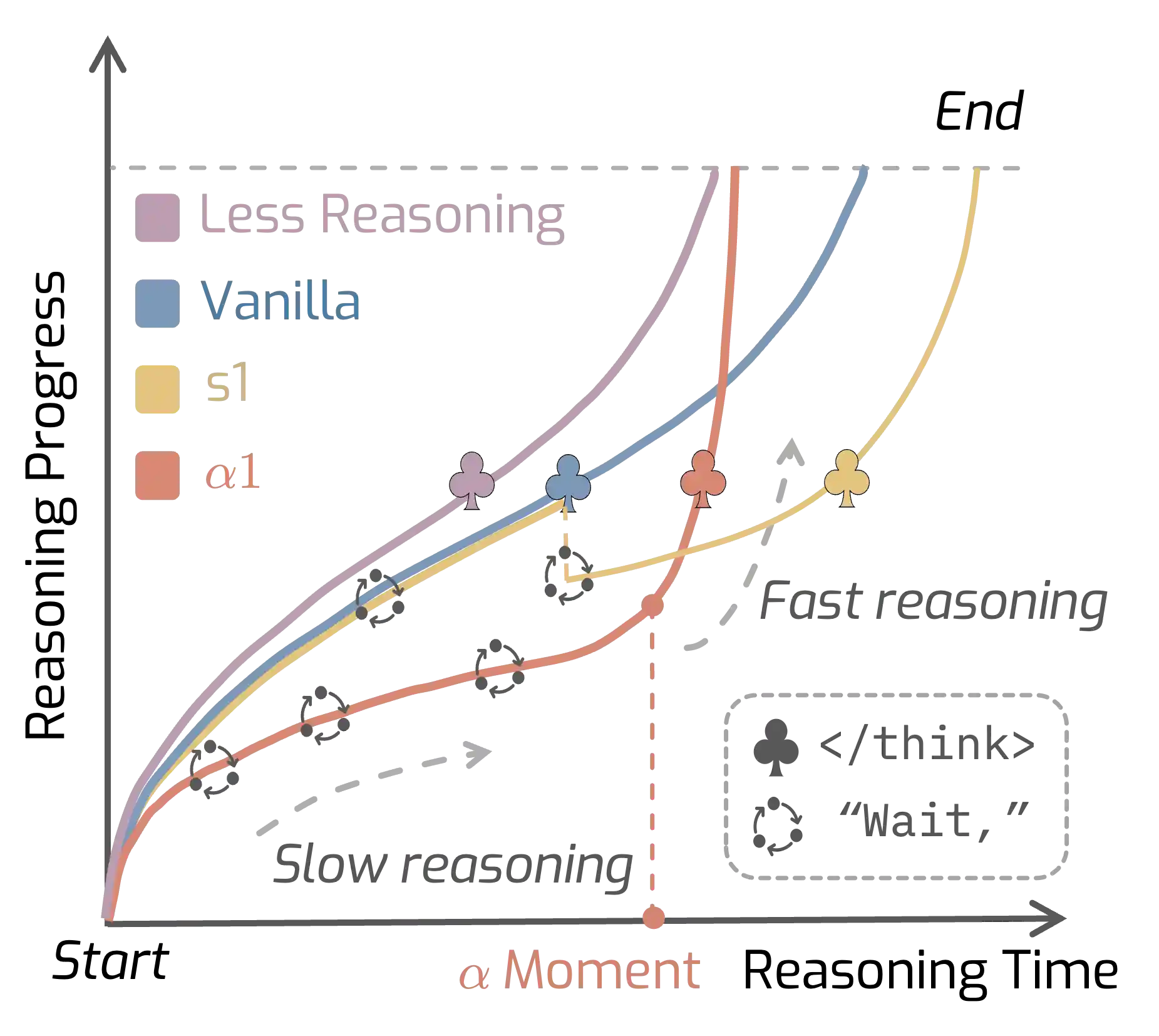
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
paper / project page / code |
|
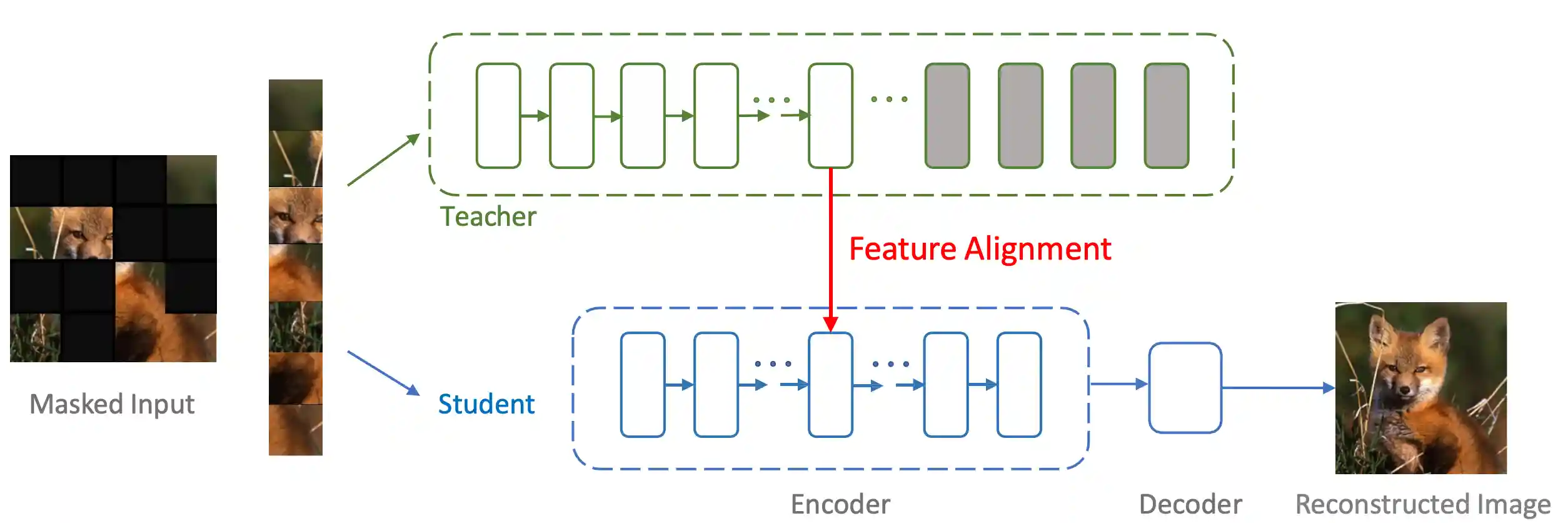
Masked Autoencoders Enable Efficient Knowledge Distillers
|
|
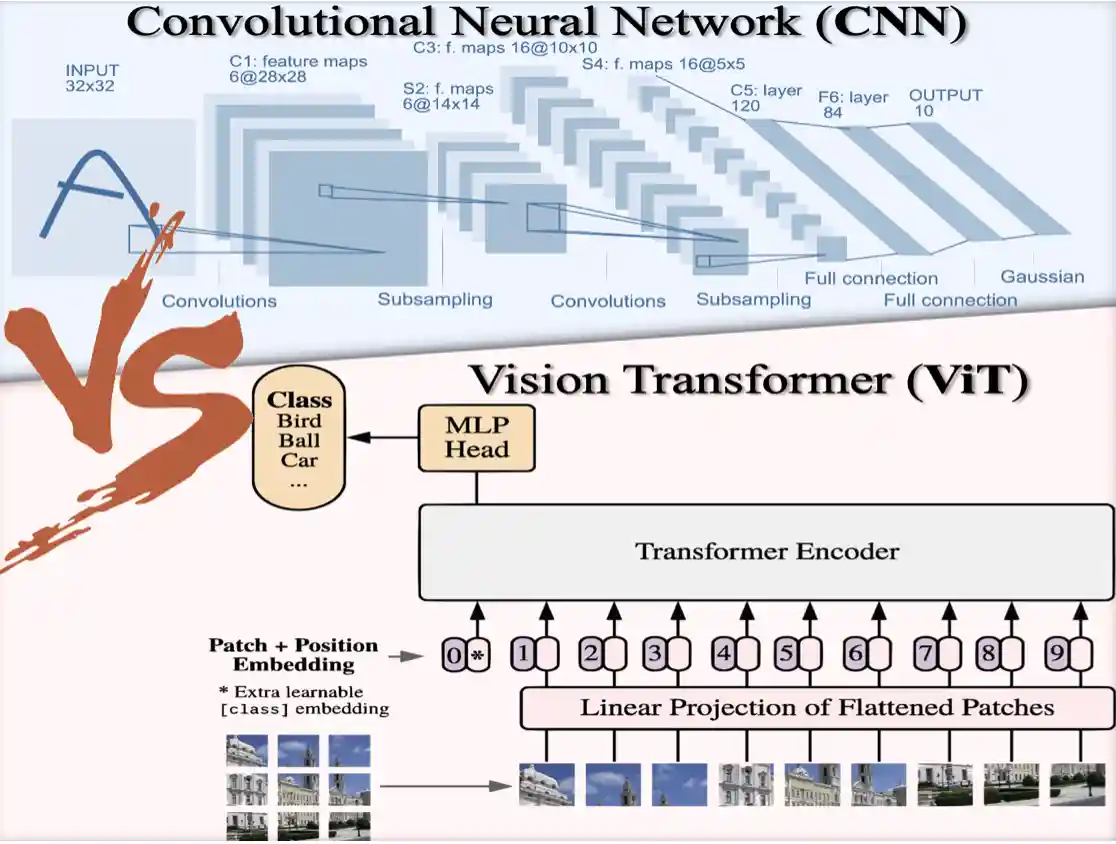
Are Transformers More Robust than CNNs?
|
|
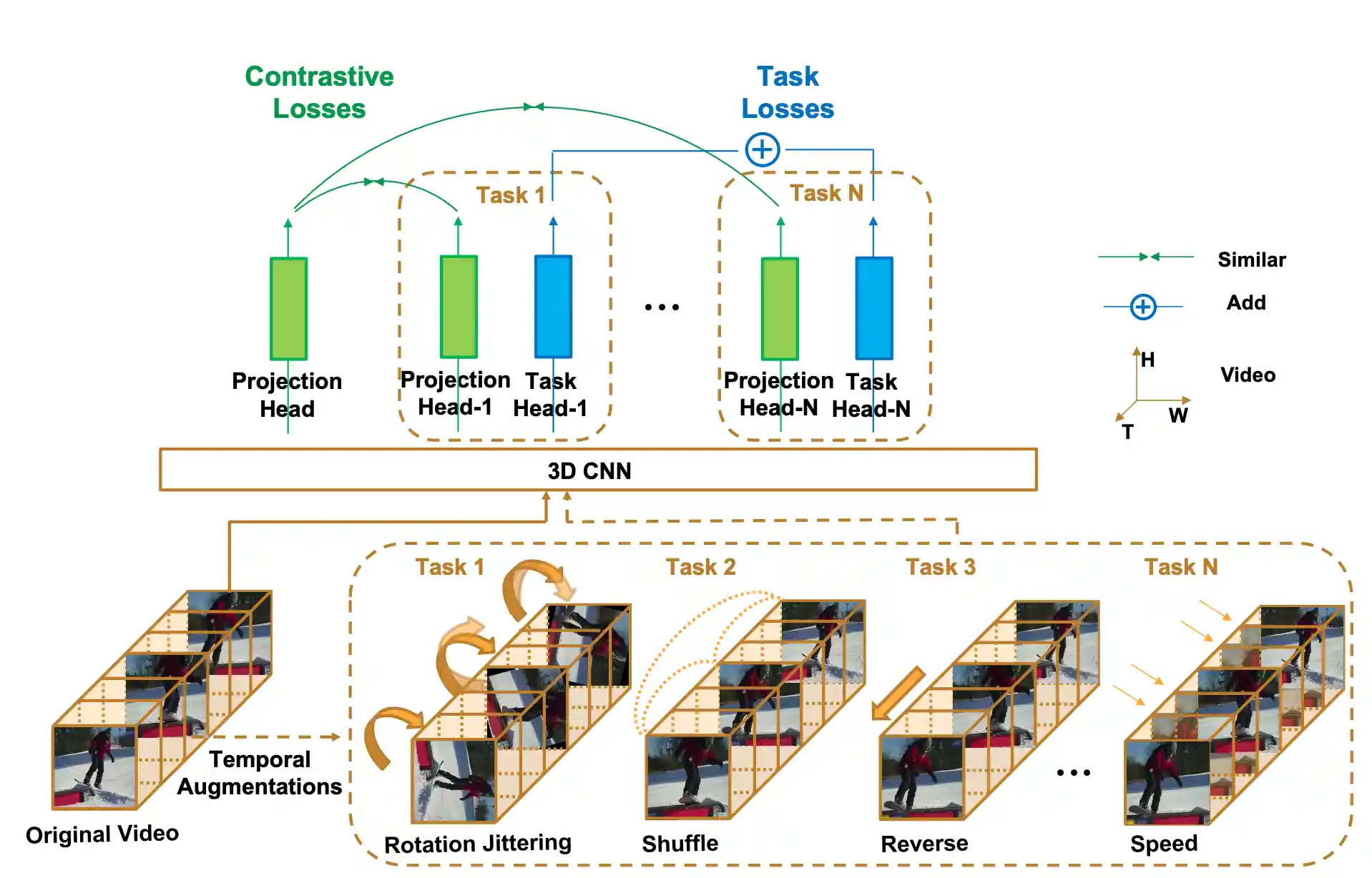
Can Temporal Information Help with Contrastive Self-Supervised Learning?
|
|
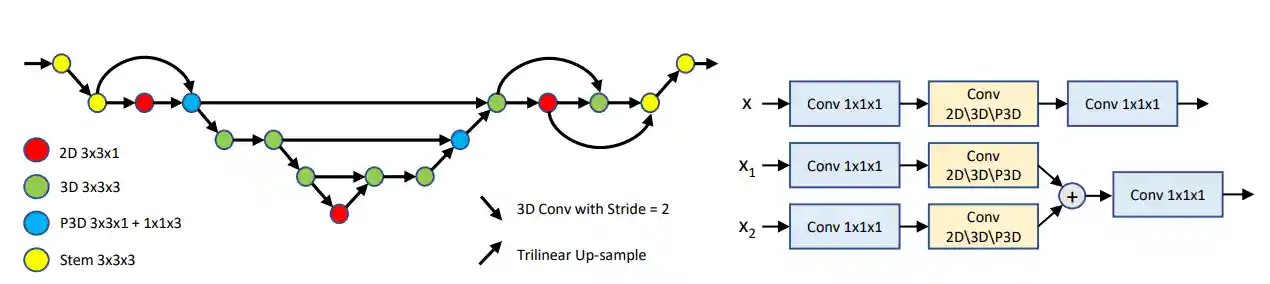
C2FNAS: Coarse-to-Fine Neural Architecture Search for 3D Medical Image Segmentation
|

|
Semantic Part Detection via Matching: Learning to Generalize to Novel Viewpoints from Limited Training Data
|

|
Clevr-ref+: Diagnosing Visual Reasoning with Referring Expressions
|
|
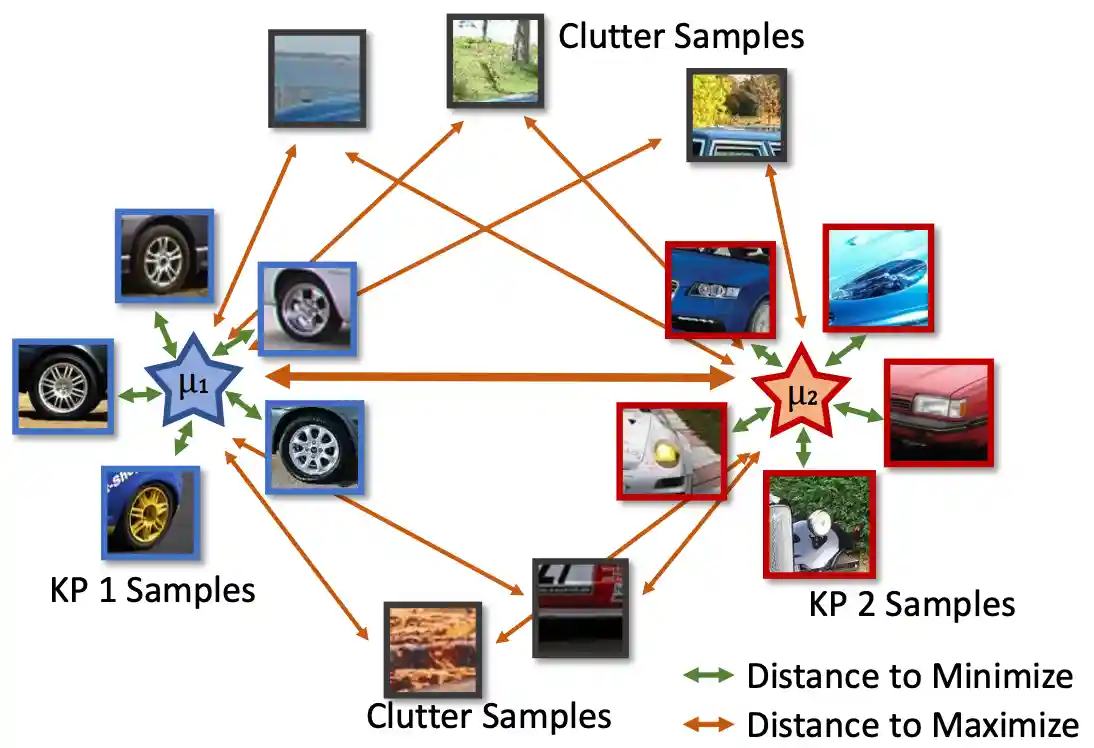
CoKe: Contrastive Learning for Robust Keypoint Detection
|
|
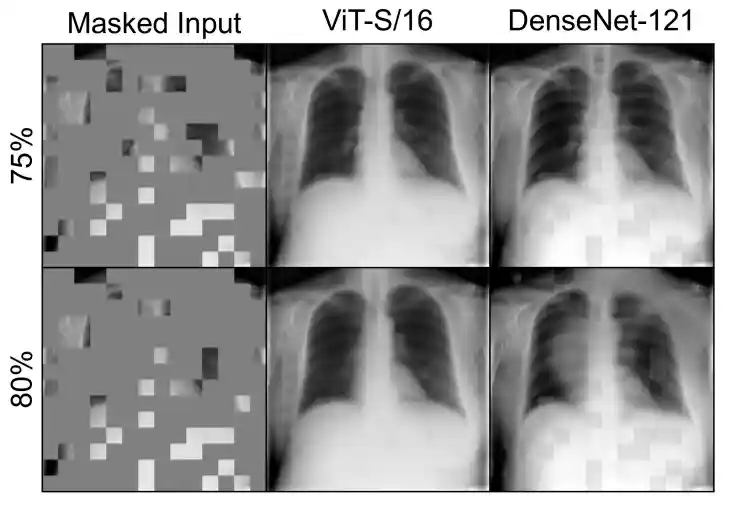
Delving Into Masked Autoencoders for Multi-Label Thorax Disease Classification
|

|
REOrdering Patches Improves Vision Models
paper / project page / code |

|
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
paper / project page / code / data |
|
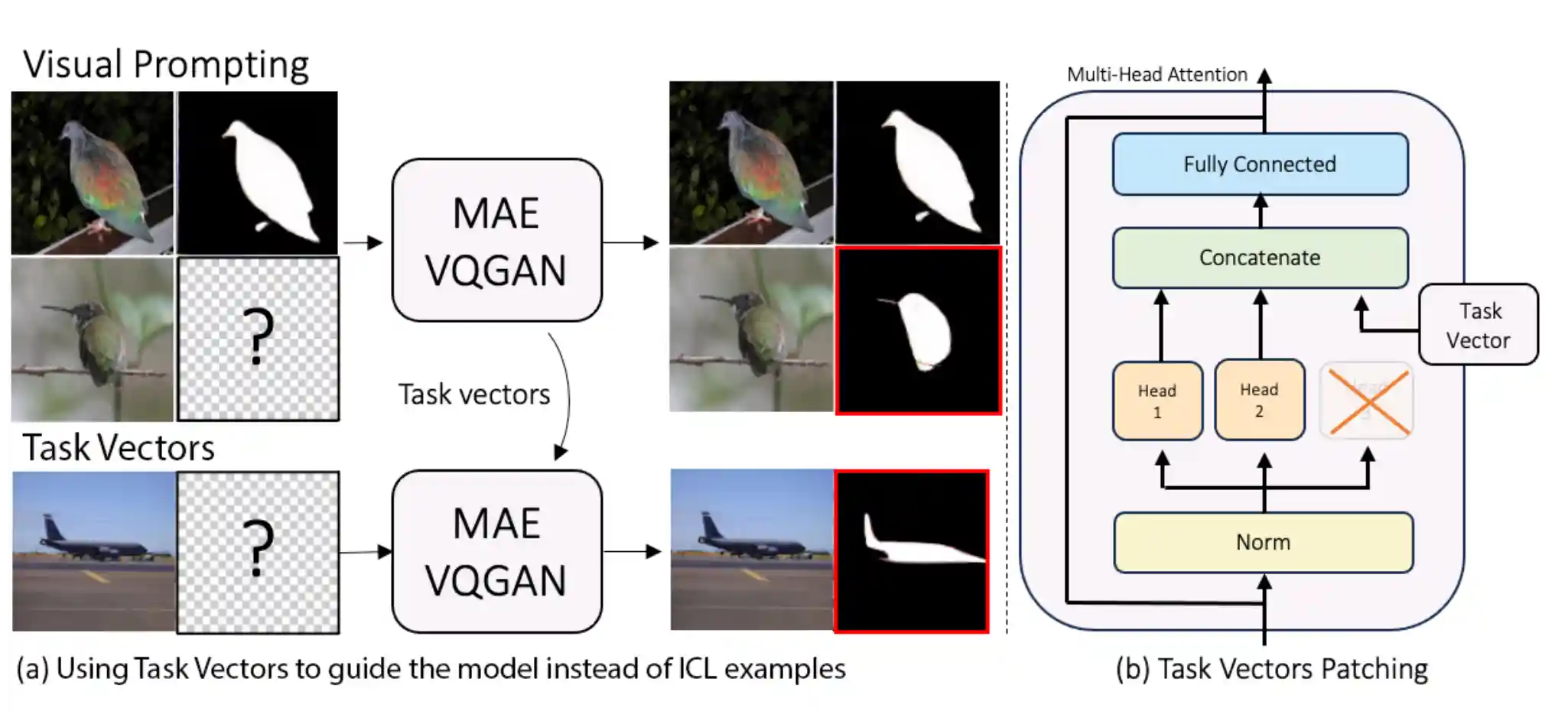
Finding Visual Task Vectors
|

|
Mask Guided Matting via Progressive Refinement Network
|
|
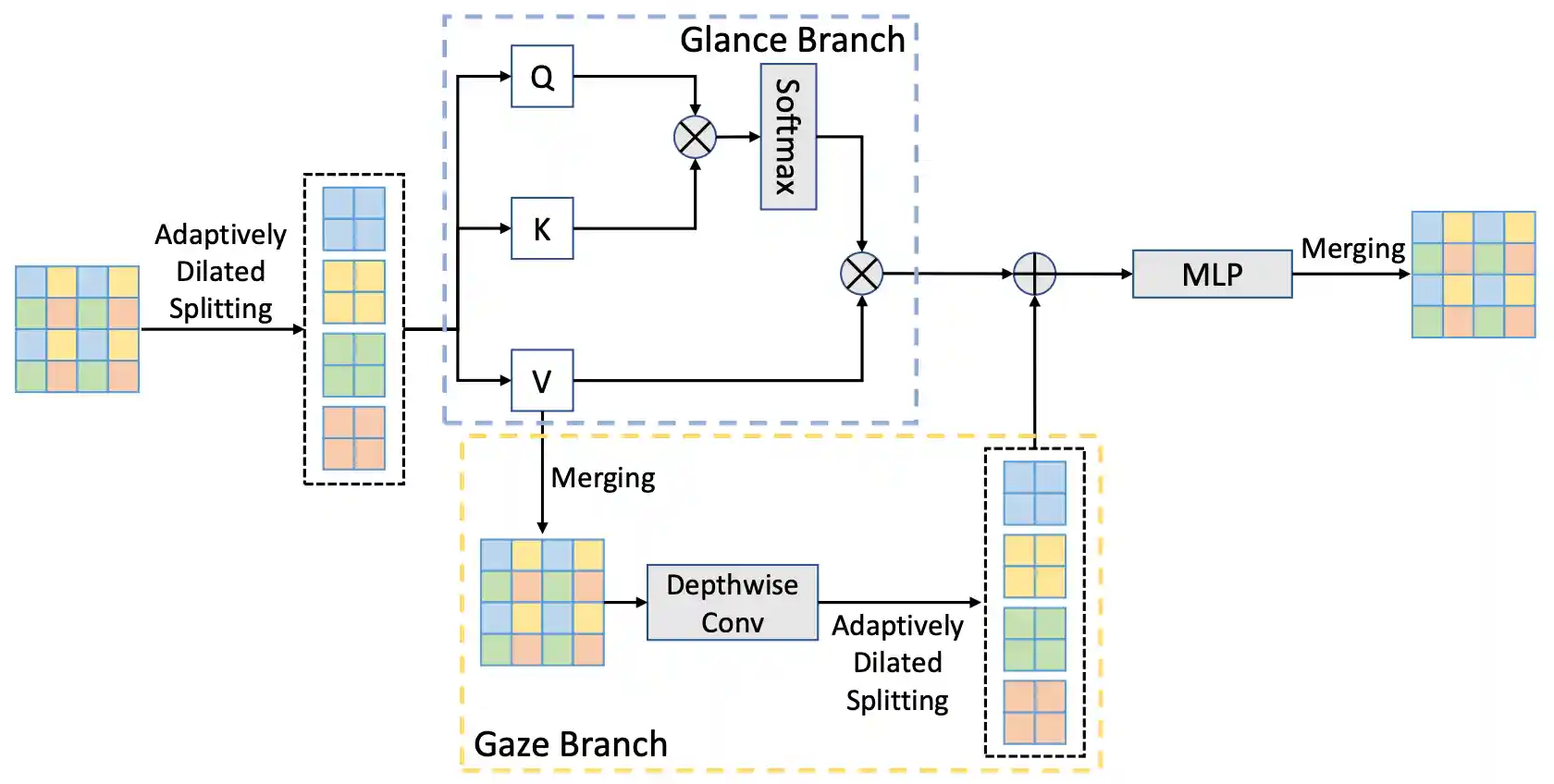
Glance-and-Gaze Vision Transformer
|
|
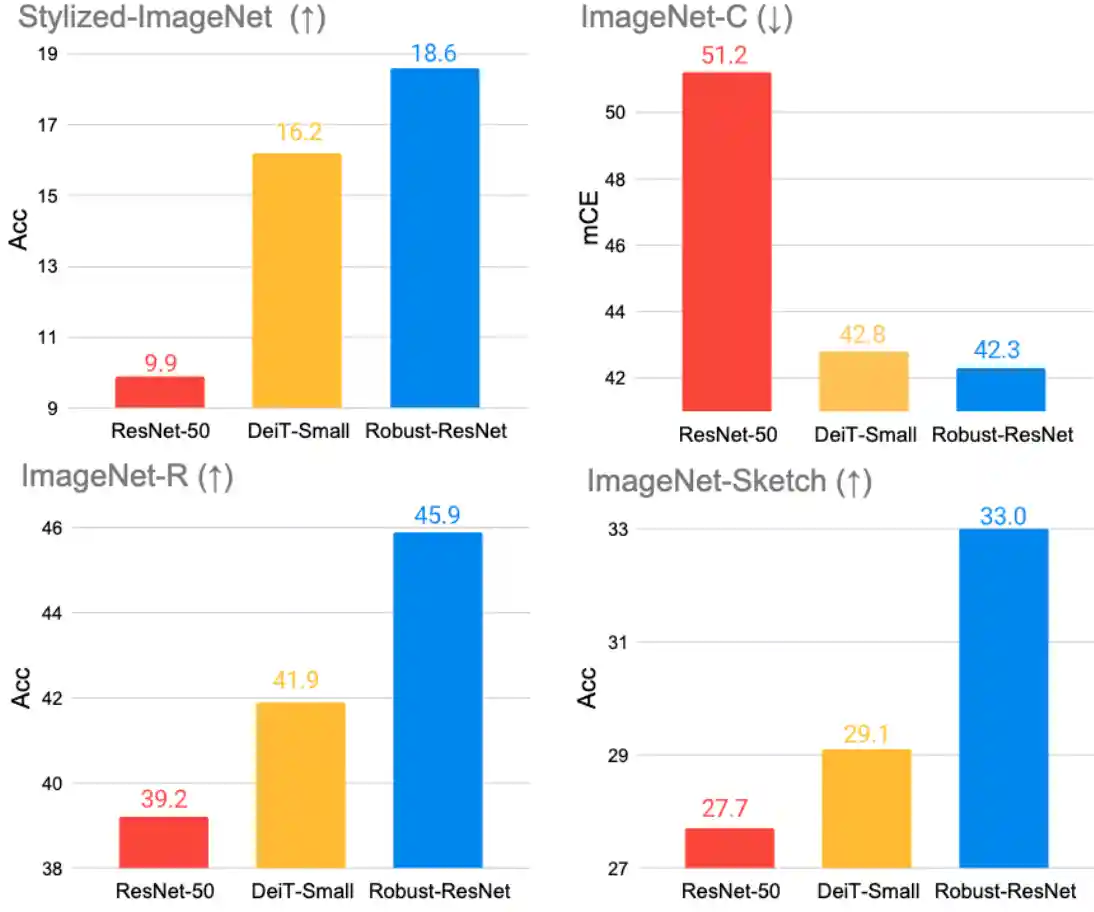
Can CNNs Be More Robust Than Transformers?
|

|
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
paper / project page / code / data |
|
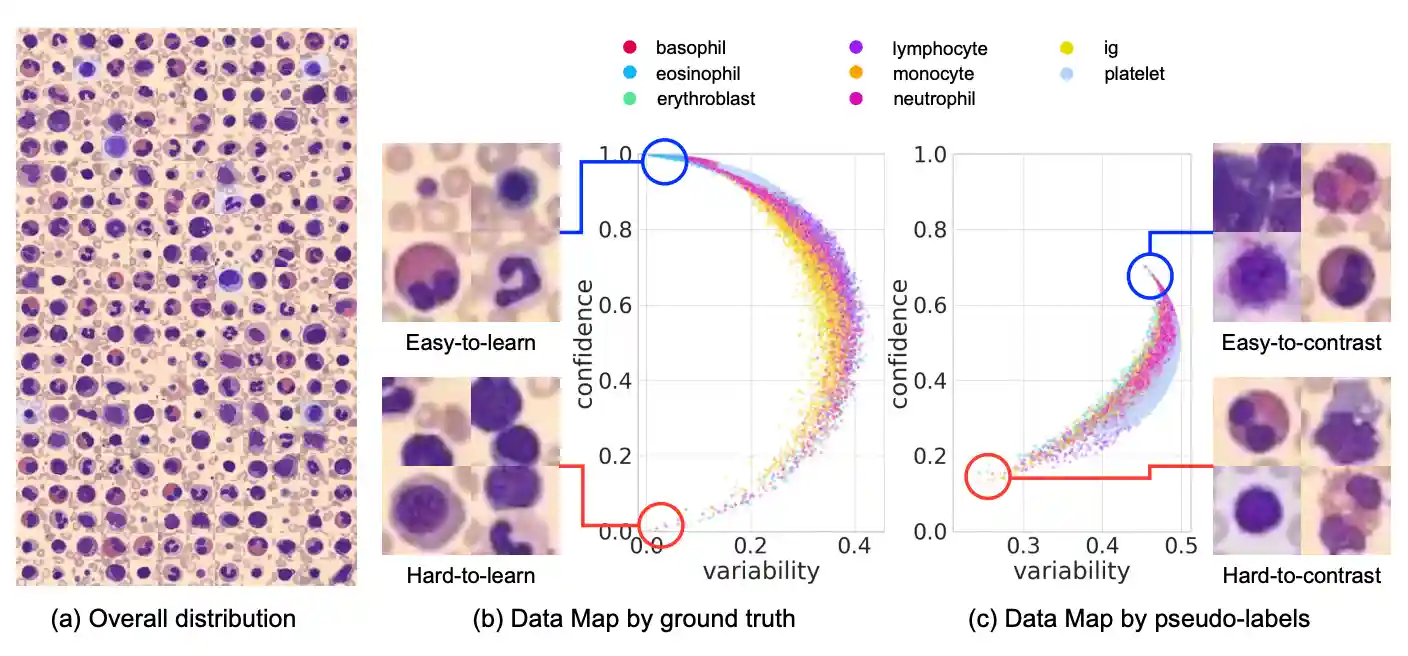
Making Your First Choice: To Address Cold Start Problem in Medical Active Learning
|
|
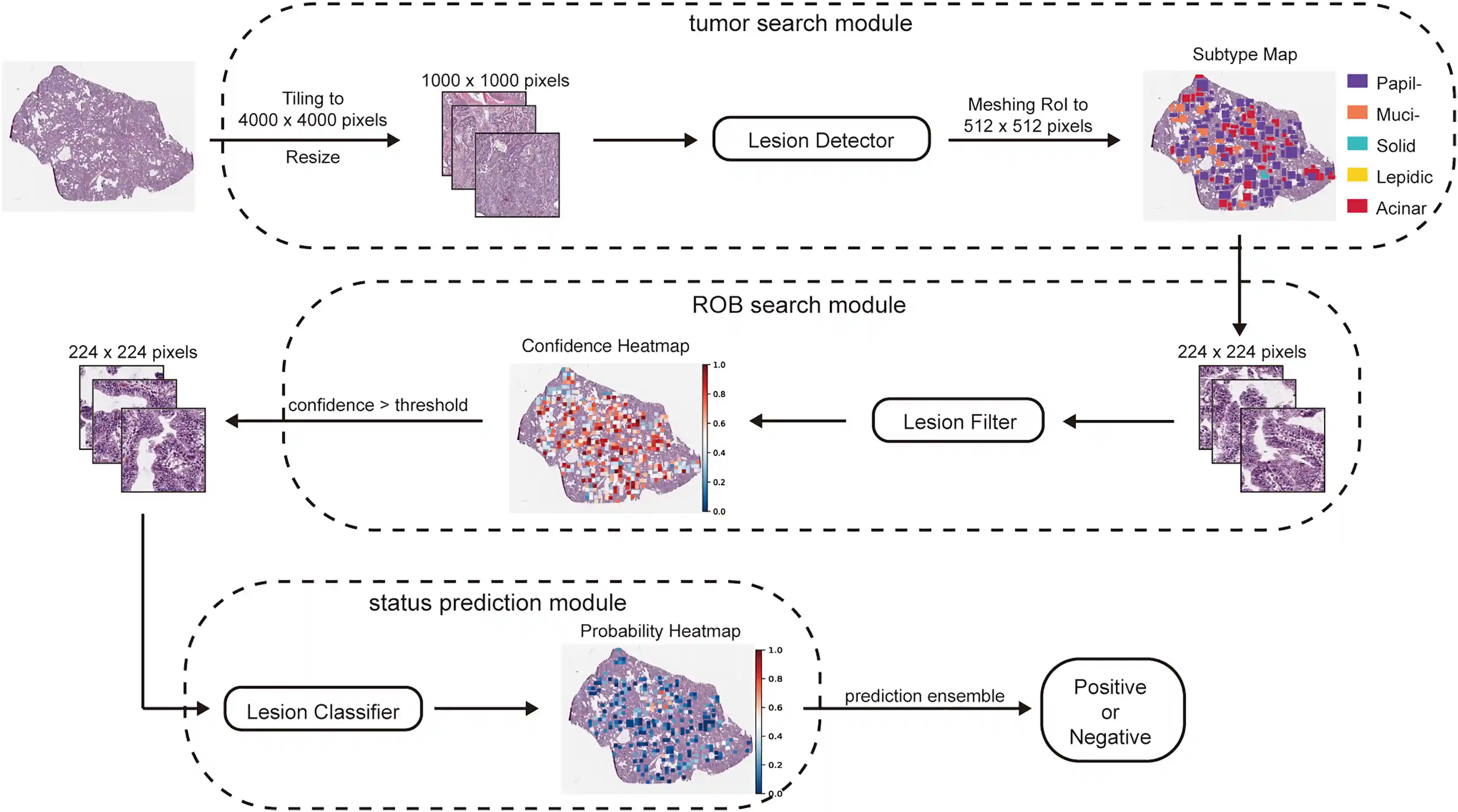
Focalizing regions of biomarker relevance facilitates biomarker prediction on histopathological images
|
|
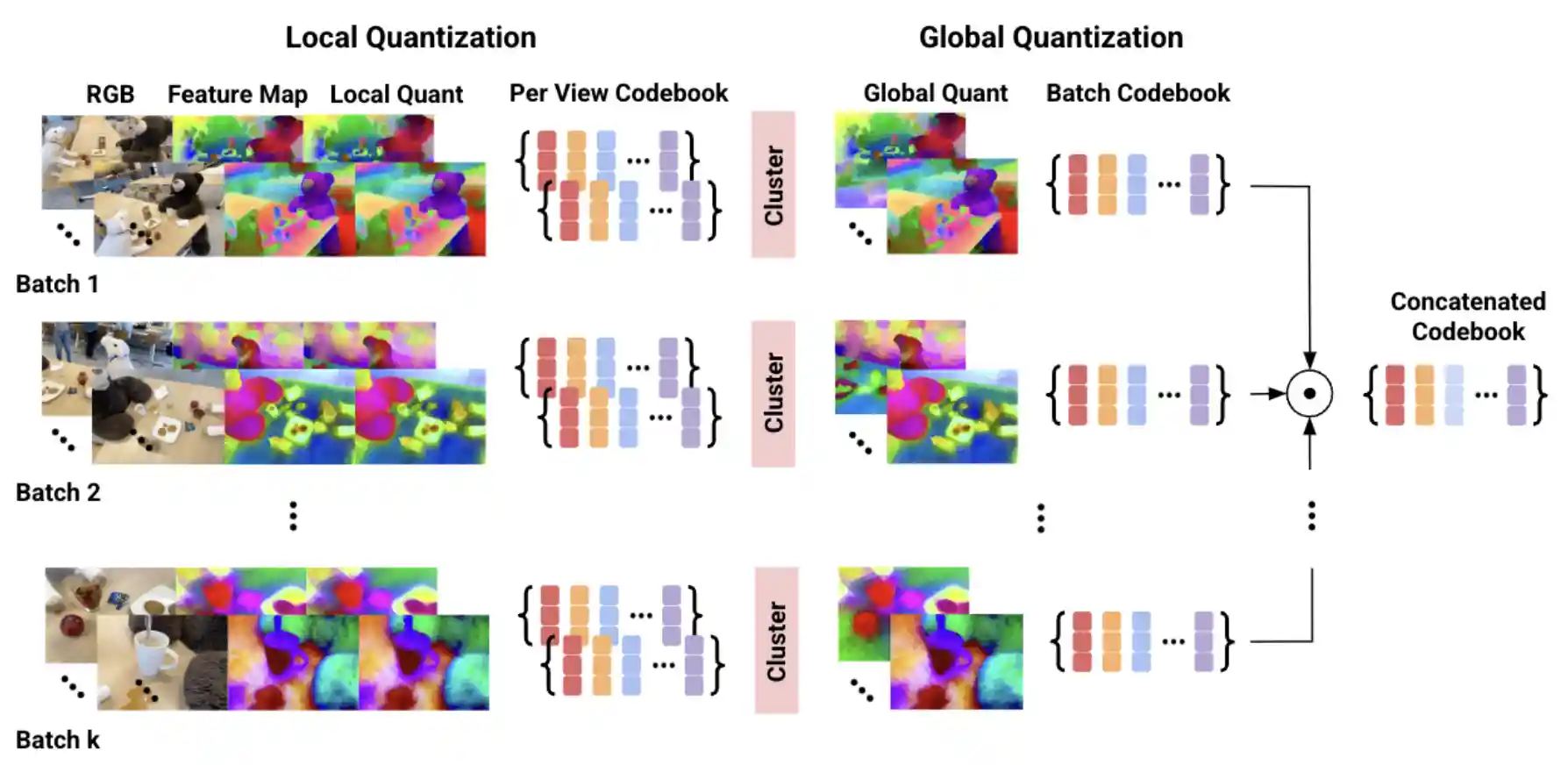
Vector Quantized Feature Fields for Fast 3D Semantic Lifting
|
|
Fast AdvProp
|