Zekun Qi

- 2026-02 One paper accepted to CVPR 2026.
- 2026-01 Three papers accepted to ICLR 2026.
- 2025-09 Two papers accepted to NeurIPS 2025, and one of them as Spotlight presentation.
- 2025-07 One paper accepted to ACMMM 2025 as Oral presentation.
- 2025-06 Two papers accepted to ICCV 2025, and one of them as Highlight presentation.
- 2025-01 One paper accepted to ICLR 2025.
- 2024-07 One paper accepted to ECCV 2024 and one paper accepted to ACMMM 2024.
- 2024-01 One paper accepted to ICLR 2024 as Spotlight presentation.
- 2023-09 One paper accepted to NeurIPS 2023.
- 2023-04 One paper accepted to ICML 2023.
- 2023-01 One paper accepted to ICLR 2023.
* indicates equal contribution
Selected Works By Date
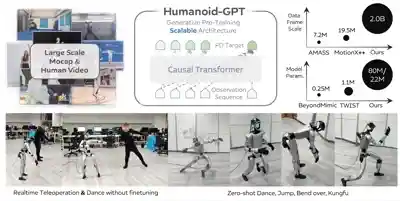
Zekun Qi*, Xuchuan Chen*, Jilong Wang*, Chenghuai Lin*, Yunrui Lian, Zhikai Zhang, Yu Guan, Wenyao Zhang, Xinqiang Yu, He Wang, Li Yi
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
We introduce Humanoid-GPT, a GPT-style Transformer trained on a billion-scale motion corpus for whole-body control, achieving zero-shot generalization to unseen motions and control tasks.
International Conference on Learning Representations (ICLR), 2026
Based on cognitive psychology, we introduce a comprehensive and complex spatial reasoning benchmark, including 50 detailed categories and 1.5K manual labeled QA pairs.
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi
Conference on Neural Information Processing Systems (NeurIPS), 2025 Spotlight
We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language.
Wenyao Zhang*, Hongsi Liu*, Zekun Qi*, Yunnan Wang*, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin
Conference on Neural Information Processing Systems (NeurIPS), 2025
We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high-level semantic information.
European Conference on Computer Vision (ECCV), 2024
We present ShapeLLM, the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages.
Runpei Dong*, Chunrui Han*, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
International Conference on Learning Representations (ICLR), 2024 Spotlight
We present DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models empowered with frequently overlooked synergy between multimodal comprehension and creation.

International Conference on Machine Learning (ICML), 2023
We propose contrast guided by reconstruct to mitigate the pattern differences between two self-supervised paradigms.

International Conference on Learning Representations (ICLR), 2023
We propose to use autoencoders as cross-modal teachers to transfer dark knowledge into 3D representation learning.
2026
Zekun Qi*, Xuchuan Chen*, Jilong Wang*, Chenghuai Lin*, Yunrui Lian, Zhikai Zhang, Yu Guan, Wenyao Zhang, Xinqiang Yu, He Wang, Li Yi
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
We introduce Humanoid-GPT, a GPT-style Transformer trained on a billion-scale motion corpus for whole-body control, achieving zero-shot generalization to unseen motions and control tasks.
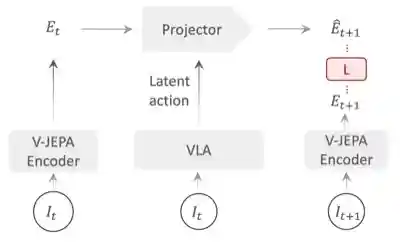
Jingwen Sun*, Wenyao Zhang*, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen
ArXiv Preprint, 2026
We introduce VLA-JEPA, a JEPA-style pretraining framework that learns action-relevant transition semantics by predicting future latent states, achieving consistent gains in sample efficiency and generalization.

ArXiv Preprint, 2026
We introduce ReWorld, a framework that employs reinforcement learning to align video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality.

International Conference on Learning Representations (ICLR), 2026
We believe that grounding can be seen as a chain-of-thought for spatial reasoning. Based on this, we achieve a new SOTA performance on VSI-Bench.
International Conference on Learning Representations (ICLR), 2026
Based on cognitive psychology, we introduce a comprehensive and complex spatial reasoning benchmark, including 50 detailed categories and 1.5K manual labeled QA pairs.
2025

Jeonghwan Kim*, Wontaek Kim*, Yidan Lu*, Jin Cheng*, Fatemeh Zargarbashi*, Zicheng Zeng*, Zekun Qi*, Zhiyang Dou, Nitish Sontakke, Donghoon Baek, Sehoon Ha, Tianyu Li
ArXiv Preprint, 2025
We present Switch-JustDance, a low-cost benchmarking pipeline that leverages Just Dance on Nintendo Switch to evaluate humanoid whole-body control, enabling direct human-robot comparison.
ArXiv Preprint, 2025
We present MM-Nav a multi-view VLA system with 360° perception. The model is trained on large-scale expert navigation data collected from multiple reinforcement learning agents.
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi
Conference on Neural Information Processing Systems (NeurIPS), 2025 Spotlight
We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language.
Wenyao Zhang*, Hongsi Liu*, Zekun Qi*, Yunnan Wang*, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin
Conference on Neural Information Processing Systems (NeurIPS), 2025
We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high-level semantic information.
International Conference on Computer Vision (ICCV), 2025 Highlight
We introduce DexVLG, a vision‑language‑grasp model trained on the 170M‑pose, 174k‑object dataset that can generate instruction‑aligned dexterous grasp poses.
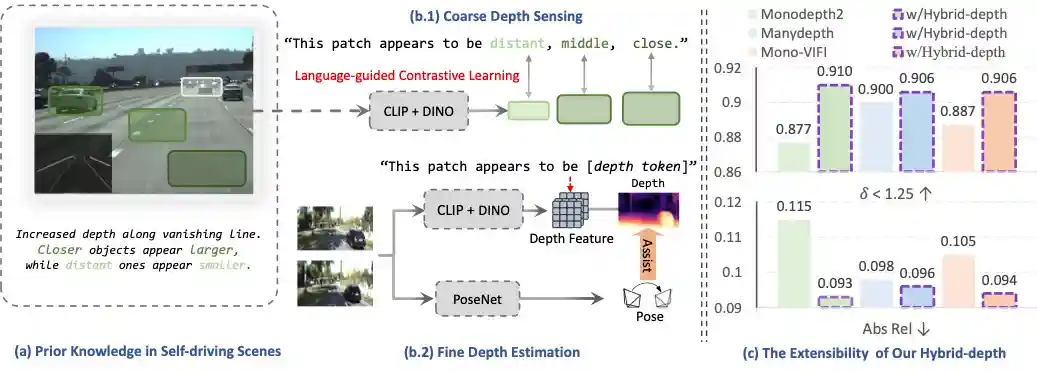
International Conference on Computer Vision (ICCV), 2025
We introduce Hybrid‑depth, a self‑supervised method that aligns hybrid semantics via language guided fusion, achieving SOTA accuracy on KITTI.
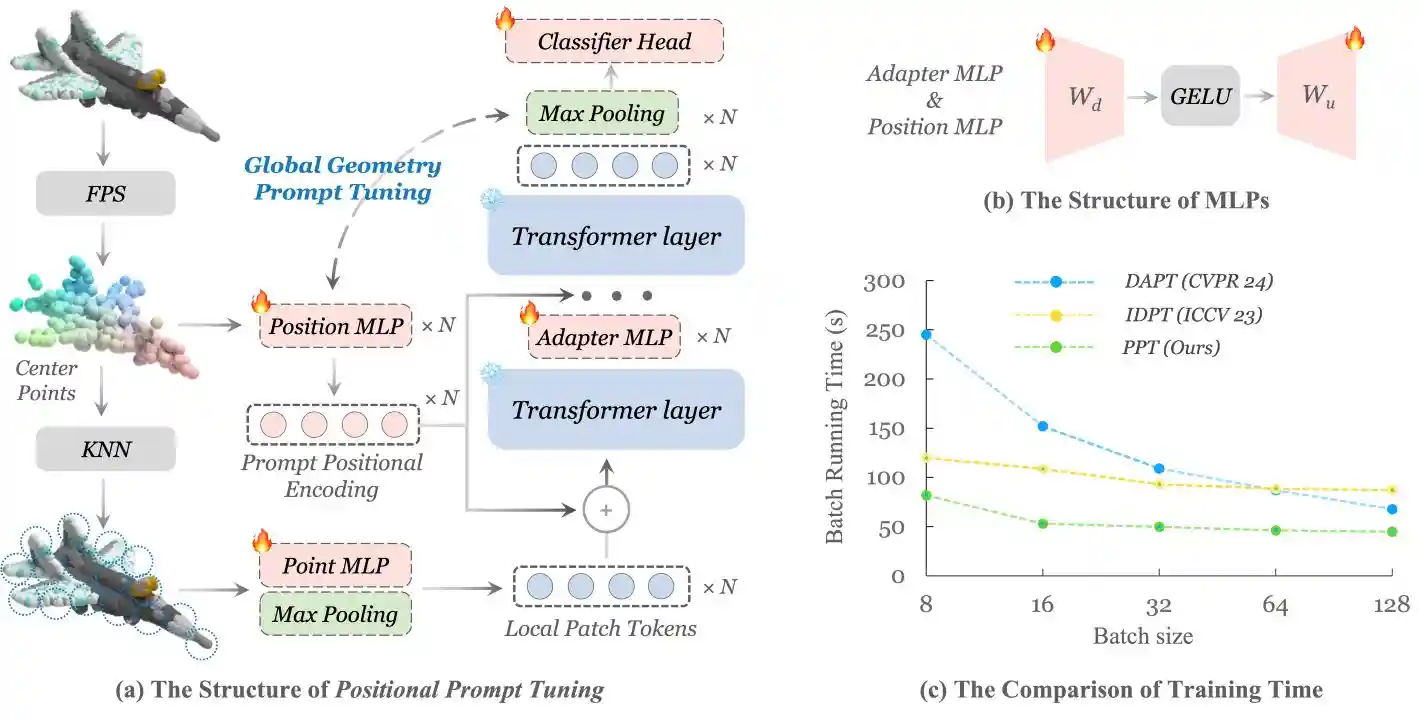
ACM International Conference on Multimedia (ACMMM), 2025 Oral
We rethink the role of positional encoding in 3D representation learning, and propose Positional Prompt Tuning for transfer learning.

International Conference on Learning Representations (ICLR), 2025
We collect diverse images and prompts, and utilize GPT-4o for automated evaluation aligned with human preference.
2024
European Conference on Computer Vision (ECCV), 2024
We present ShapeLLM, the first 3D Multimodal Large Language Model designed for embodied interaction.
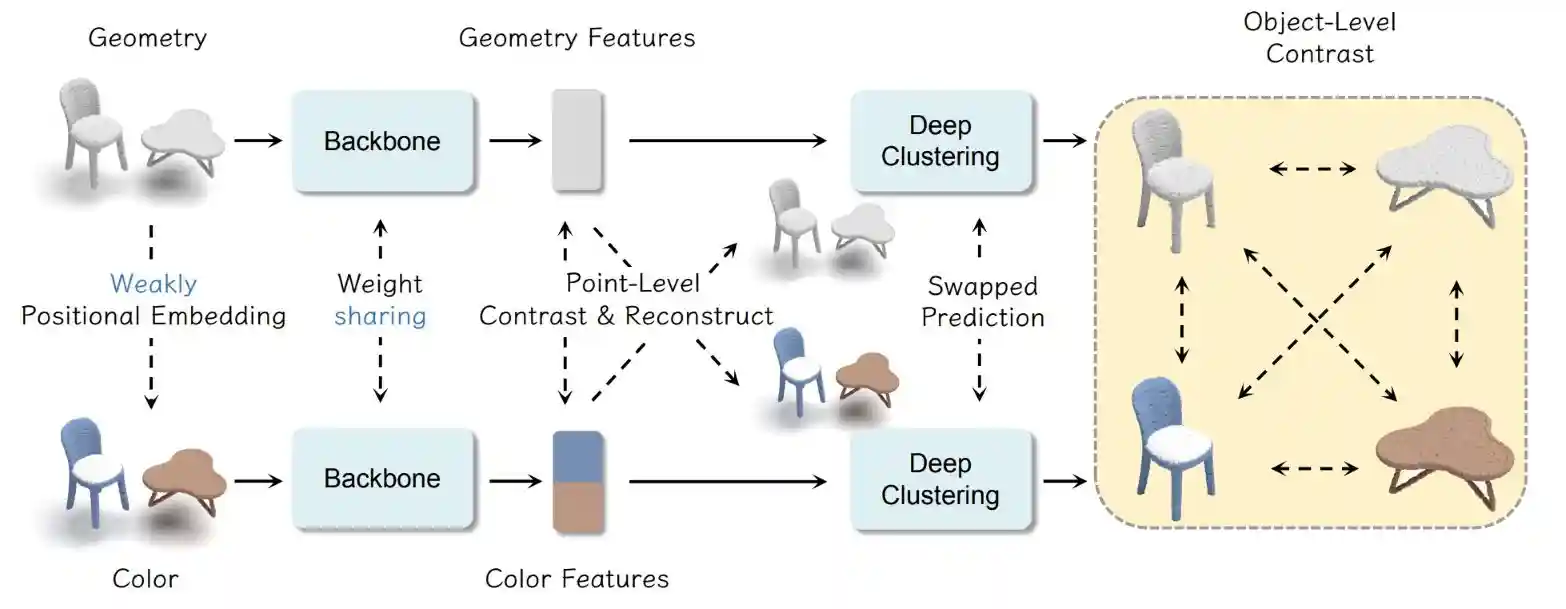
ACM International Conference on Multimedia (ACMMM), 2024
We enhance the utilization of color information to improve 3D scene self-supervised learning.
Runpei Dong*, Chunrui Han*, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
International Conference on Learning Representations (ICLR), 2024 Spotlight
We present DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models.
2023
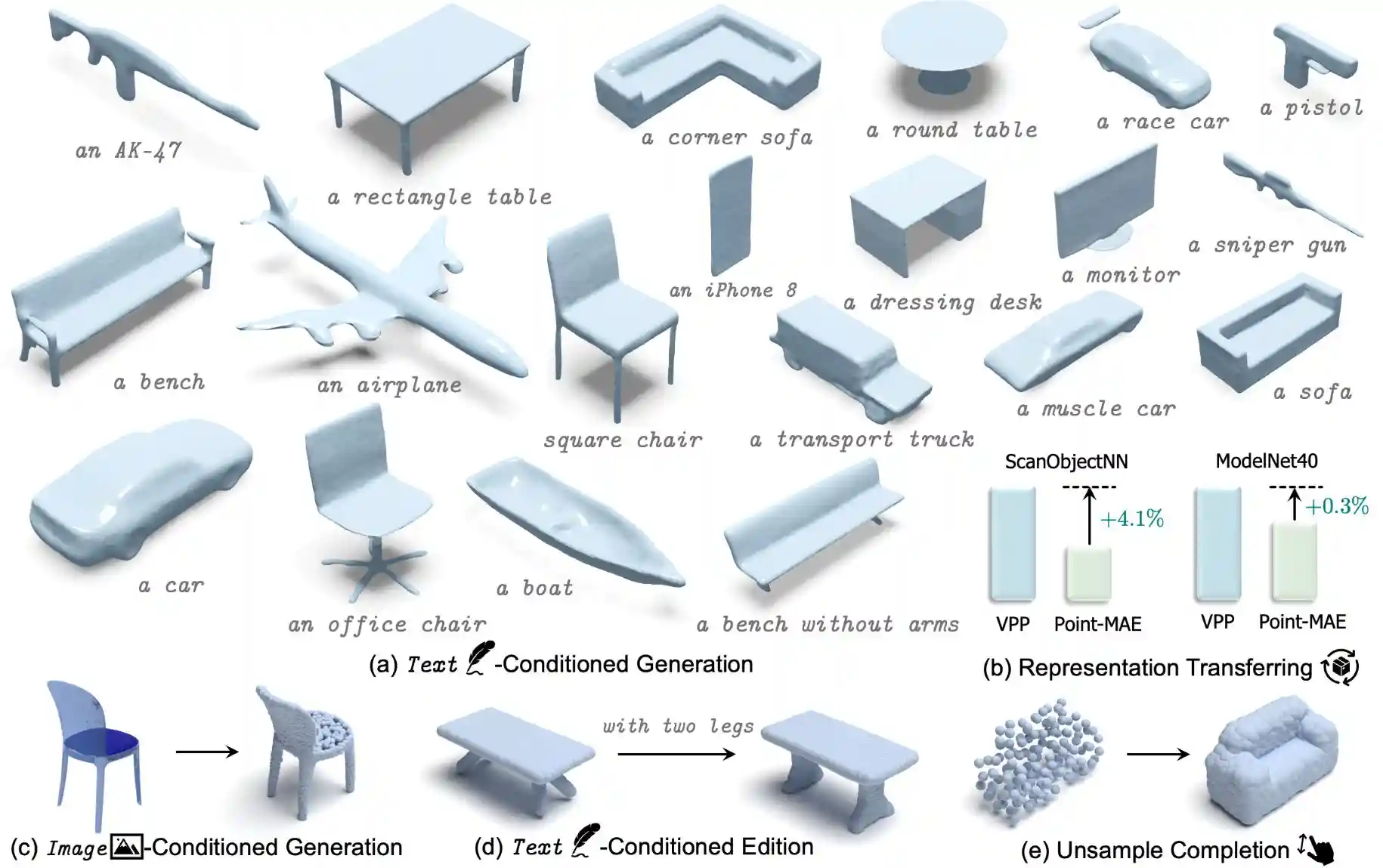
Conference on Neural Information Processing Systems (NeurIPS), 2023
We achieve rapid, multi-category 3D conditional generation by sharing the merits of different representations. VPP can generate 3D shapes in less than 0.2s.
International Conference on Machine Learning (ICML), 2023
We propose contrast guided by reconstruct to mitigate the pattern differences between two self-supervised paradigms.
International Conference on Learning Representations (ICLR), 2023
We propose to use autoencoders as cross-modal teachers to transfer dark knowledge into 3D representation learning.
- 2024 National Scholarship & Xiaomi Special Scholarship, Xi'an Jiaotong University
- 2022 Outstanding Graduate, Xi'an Jiaotong University
- 2021 Annual Spiritual Civilization Award, Xi'an Jiaotong University
- 2020 National runner-up of the China Undergraduate Physics Tournament (CUPT) as the team leader