Xiaoming Zhao, PhD

Anagh Malik, Dorian Chan, Xiaoming Zhao, David B. Lindell, Oncel Tuzel, and Jen-Hao Rick Chang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
[bibtex] We introduce a framework for learning latent representations of 4D objects which are descriptive, compressive, and accessible (requiring minimal input).

Jen-Hao Rick Chang*, Xiaoming Zhao*, Dorian Chan, and Oncel Tuzel
(* denotes equal contribution)
International Conference on Learning Representations (ICLR), 2026
[bibtex] We propose a 3D latent representation that jointly models object geometry and view-dependent appearance, enabling high-quality image-to-3D generation.

Xiaoming Zhao and Alexander G. Schwing
AAAI Conference on Artificial Intelligence (AAAI), 2026
[Paper] [bibtex] We find both classifier guidance and classifier-free guidance achieve conditional generation by pushing the denoising diffusion trajectories away from data distribution's decision boundaries.
Jen-Hao Rick Chang, Yuyang Wang, Miguel Angel Bautista, Jiatao Gu, Xiaoming Zhao, Joshua M. Susskind, and Oncel Tuzel
arXiv, 2025
[Paper] [Website] [bibtex] We show, for the first time, that latent 3D representations learned from modeling 3D surface probability densities can scale and perform competitively.

Xiaoming Zhao, Pratul P. Srinivasan, Dor Verbin, Keunhong Park, Ricardo Martin Brualla, and Philipp Henzler
Neural Information Processing Systems (NeurIPS), 2024
[Paper] [Results] [Website] [Leaderboard] [bibtex]
IllumiNeRF provides a simpler approach than traditional inverse rendering for 3D relighting: distilling samples from a single-image relighting diffusion model into a latent-variable NeRF.

Jing Wen, Xiaoming Zhao, Zhongzheng Ren, Alexander G. Schwing, and Shenlong Wang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[Paper] [Code] [Website] [bibtex] GoMAvatar introduces Gaussians-on-Mesh (GoM) representation for real-time, memory-efficient, and high-quality animatable human modeling.


Zhenggang Tang, Zhongzheng Ren, Xiaoming Zhao, Bowen Wen, Jonathan Tremblay, Stan Birchfield, and Alexander G. Schwing
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[Paper] [Code] [Website] [bibtex] NeRFDeformer automatically modifies a NeRF representation based on a single RGB-D observation of a non-rigid transformed version of the original scene.
Xiaoming Zhao, Alex Colburn, Fangchang Ma, Miguel Angel Bautista, Joshua M. Susskind, and Alexander G. Schwing
International Conference on Learning Representations (ICLR), 2024
[Paper] [Code] [Website] [bibtex] PGDVS provides an analysis framework for generalized dynamic view synthesis and finds with consistent depth estimations, scene-specific appearance optimization is NOT required.

Xiaoming Zhao, Yuan-Ting Hu, Zhongzheng Ren, and Alexander G. Schwing
AAAI Conference on Artificial Intelligence (AAAI), 2023
[Paper] [Code] [bibtex] OPlanes provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification.
Xiaoming Zhao, Fangchang Ma, David Güera, Zhile Ren, Alexander G. Schwing, and Alex Colburn
European Conference on Computer Vision (ECCV), 2022 (Oral Presentation)
[Paper] [Code] [Website] [bibtex]
GMPI guarantees to be view-consistent and enables fast training (in less than half a day at a resolution of 10242) and high FPS during inference.

Xiaoming Zhao, Zhizhen Zhao, and Alexander G. Schwing
European Conference on Computer Vision (ECCV), 2022
[Paper] [Code] [Website] [bibtex] Carefully designed initialization and alignment procedures enable benefiting from both classical and recent learning-based texture optimization techniques.

Zhongzheng Ren*, Xiaoming Zhao*, and Alexander G. Schwing
(* denotes equal contribution)
Neural Information Processing Systems (NeurIPS), 2021
[Paper] [Website] [bibtex] REDO enables class-agnostic geometry reconstruction for dynamic objects from RGB-D videos.
Xiaoming Zhao, Harsh Agrawal, Dhruv Batra, and Alexander G. Schwing
International Conference on Computer Vision (ICCV), 2021
[Paper] [Code] [Website] [bibtex] A well-trained visual odometry module can be a drop-in replacement for GPS and Compass sensor in PointGoal navigation.
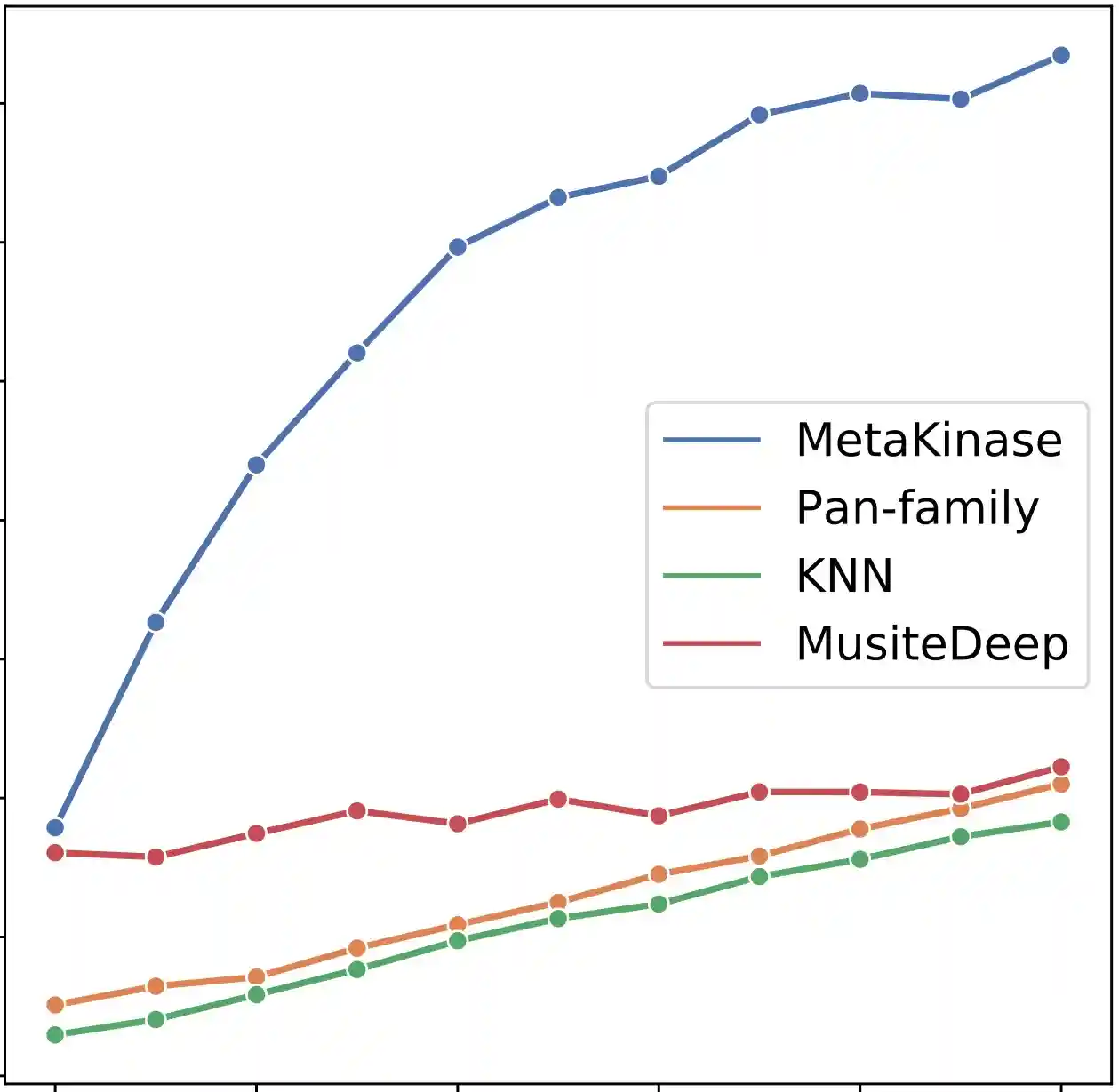
Yunan Luo*, Jianzhu Ma*, Xiaoming Zhao, Yufeng Su, Yang Liu, Trey Ideker, and Jian Peng
(* denotes equal contribution)
Research in Computational Molecular Biology (RECOMB), 2019
[Paper] [bibtex] Meta-learning and few-shot learning strategy can be utilized to mitigate the data scarcity issue in characterizing the specificity of less-studied kinases for protein-peptide binding prediction.
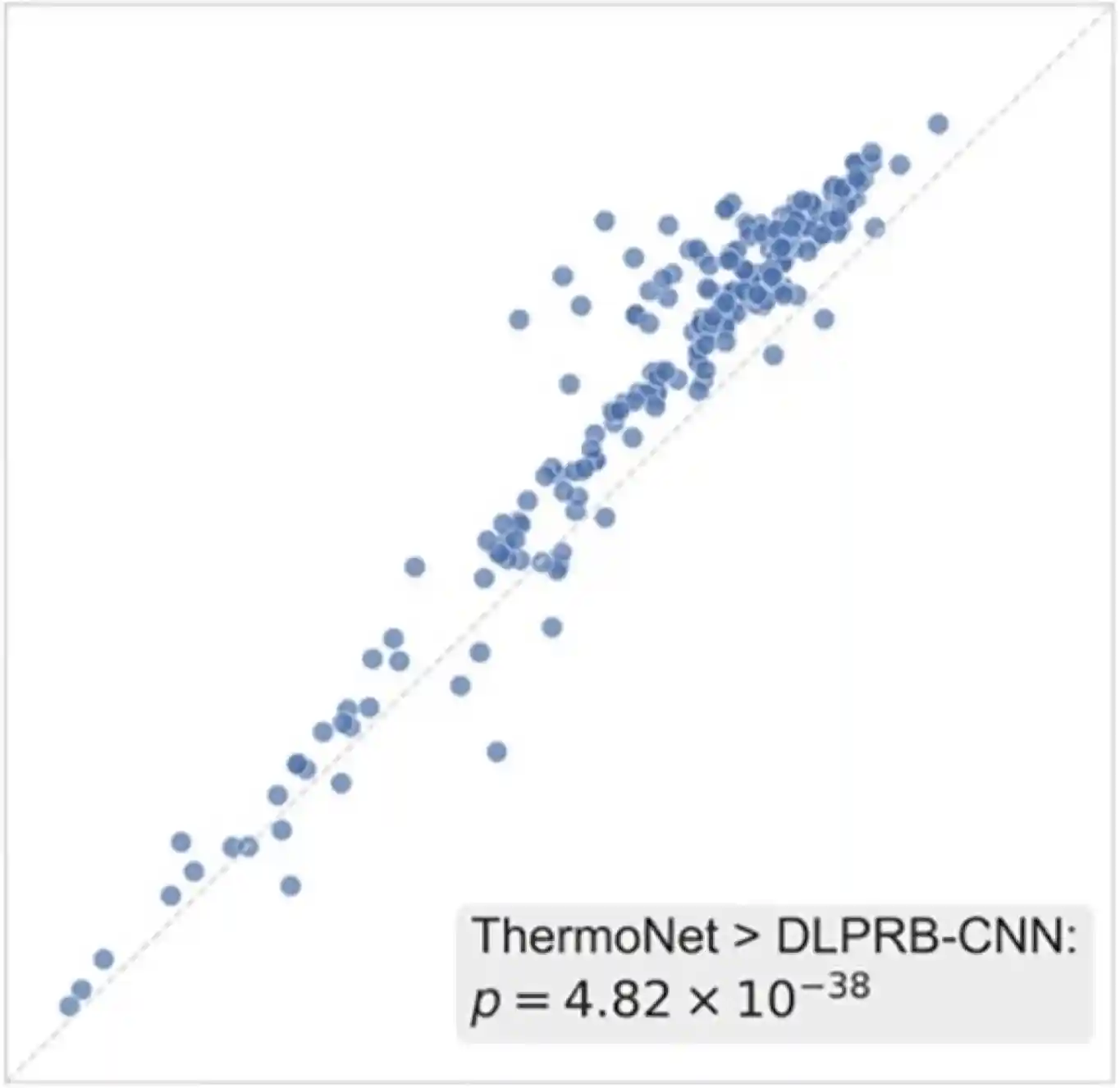
Yufeng Su, Yunan Luo, Xiaoming Zhao, Yang Liu, and Jian Peng
PLOS Computational Biology, 2019
[Paper] [Code] [bibtex] A deep learning-based thermodynamic model is introduced for protein-RNA binding prediction.
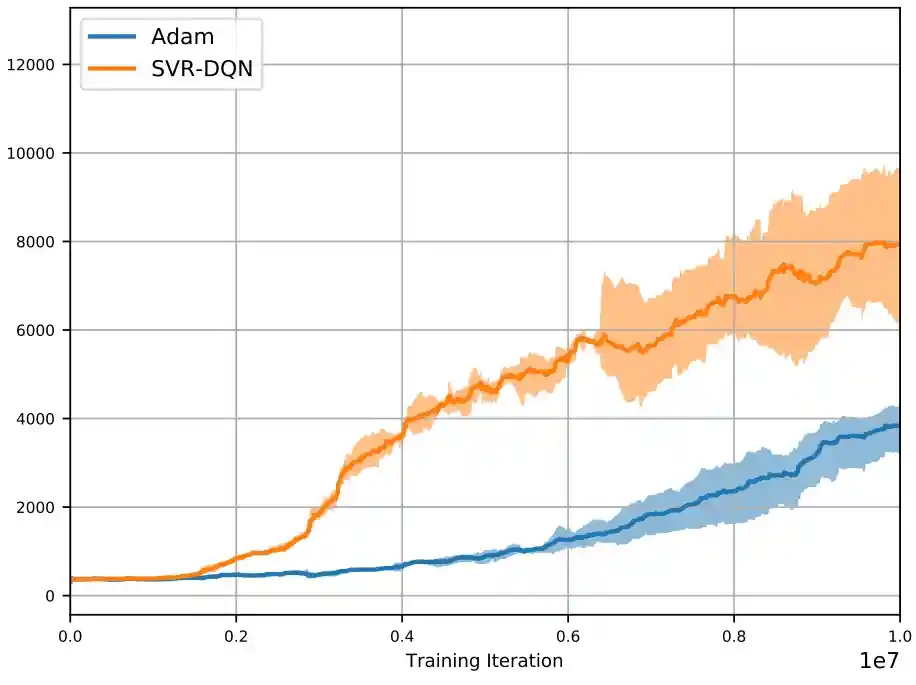
Wei-Ye Zhao, Xi-Ya Guan, Yang Liu, Xiaoming Zhao, and Jian Peng
arXiv, 2019
[Paper] [bibtex]