Yandan Yang
|
Yandan Yang I'm an algorithm engineer at AMAP CV Lab in Beijing, China. My interests lie in computer vision and embodied intelligence. I used to work at BIGAI in 2023-2025 and Tencent in 2021-2023. Previously, I received my Bachelor's (2018) and Master's (2021) degrees from Beihang University, China, under the supervision of Prof. Xianbin Cao.Email / Scholar / Github / rednote 小红书 heart_check |

|
Research
|
|
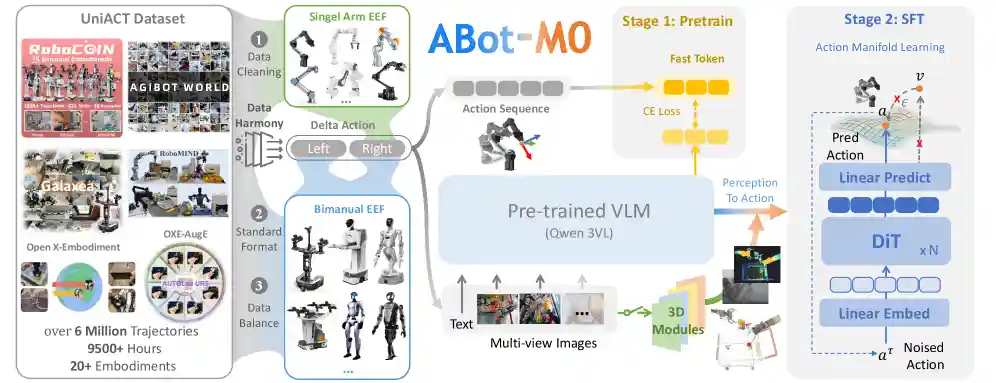
Abot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold LearningAMAP CV LabPaper / Project / Code |
|
|
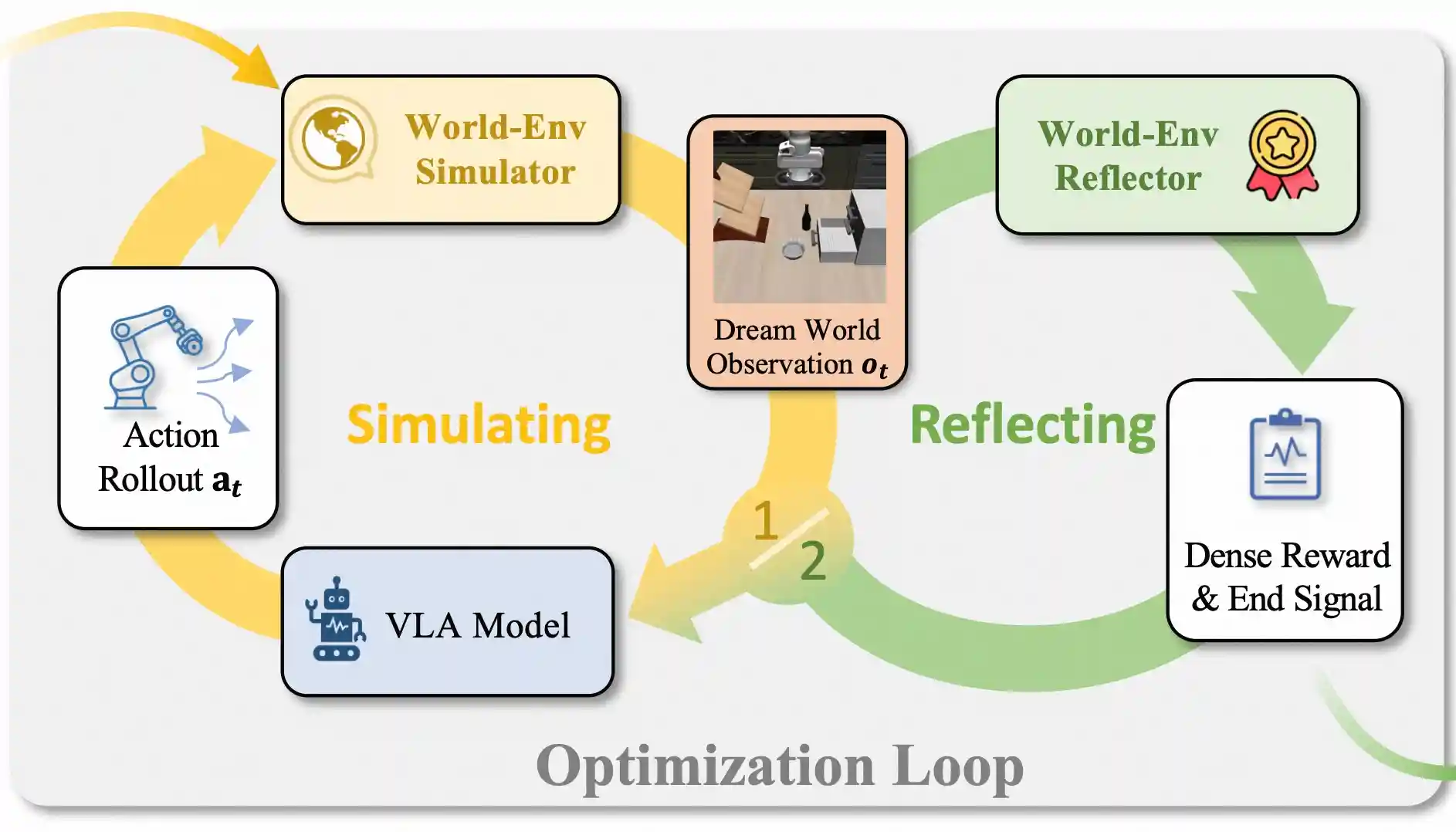
World-Env: Leveraging World Model as a Virtual Environment for VLA Post-TrainingJunjin Xiao, Yandan Yang, Xinyuan Chang, Ronghan Chen, Feng Xiong, Mu Xu, Wei-Shi Zheng, Qing Zhang,
Conference on Computer Vision and Pattern Recognition (CVPR) 2026
|
|
|
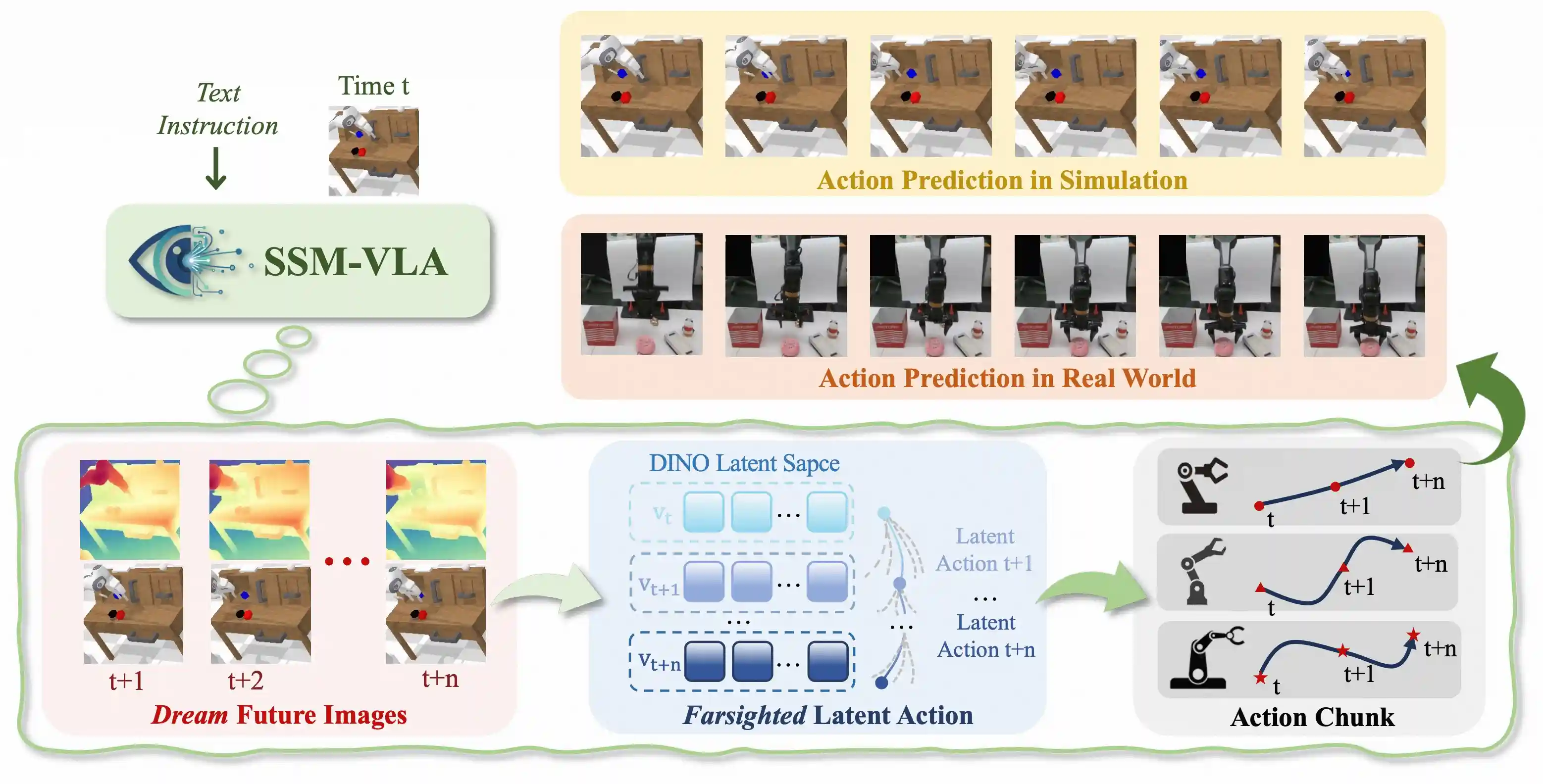
Seeing Space and Motion: Enhancing Latent Actions with Spatial and Dynamic Awareness for VLAZhejia Cai, Yandan Yang, Xinyuan Chang, Shiyi Liang, Ronghan Chen, Feng Xiong, Mu Xu, Ruqi Huang,
IEEE International Conference on Robotics & Automation (ICRA) 2026
|
|
|
SceneWeaver: All-in-One 3D Scene Synthesis with an Extensible and Self-Reflective AgentYandan Yang*, Baoxiong Jia*, Shujie Zhang, Siyuan Huang,
Advances in Neural Information Processing Systems (NeurIPS) 2025
|
|
|
MetaScenes: Towards Automated Replica Creation for Real-world 3D ScansHuangyue Yu*, Baoxiong Jia*, Yixin Chen*, Yandan Yang, Puhao Li, Rongpeng Su, Jiaxin Li, Qing Li, Wei Liang, Song-Chun Zhu, Tengyu Liu, Siyuan Huang,Conference on Computer Vision and Pattern Recognition (CVPR) 2025 AI3DG @ CVPR 2025 (* indicates equal contribution.) |
|
|
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AIYandan Yang*, Baoxiong Jia*, Peiyuan Zhi, Siyuan Huang,
Conference on Computer Vision and Pattern Recognition (CVPR) 2024
(Highlight)
|
|
|
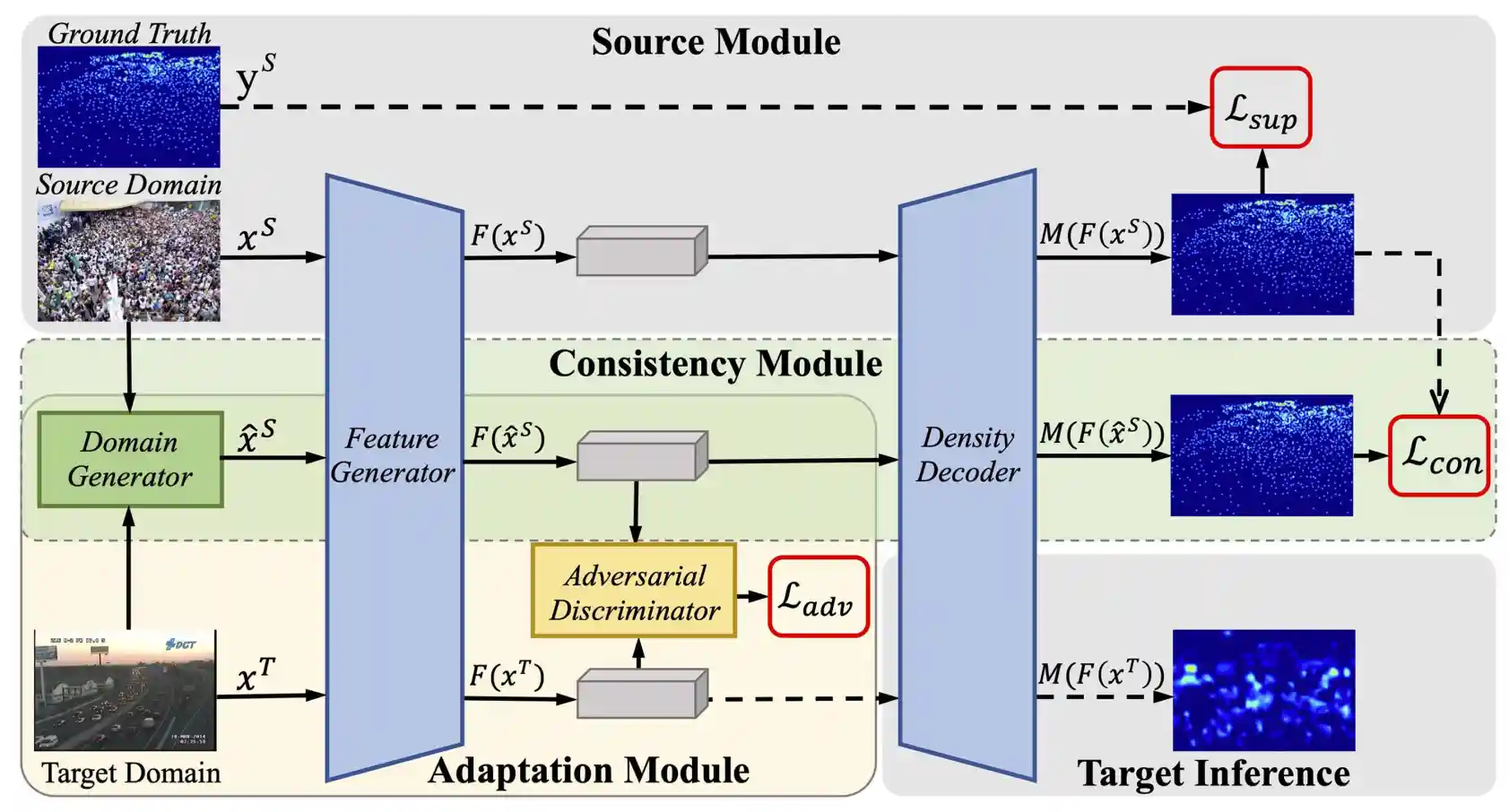
Latent Domain Generation for Unsupervised Domain Adaptation Object CountingAnran Zhang, Yandan Yang, Jun Xu, Xianbin Cao, Xiantong Zhen, Ling Shao,IEEE TRANSACTIONS ON MULTIMEDIA(TMM) 2023 |
|
|
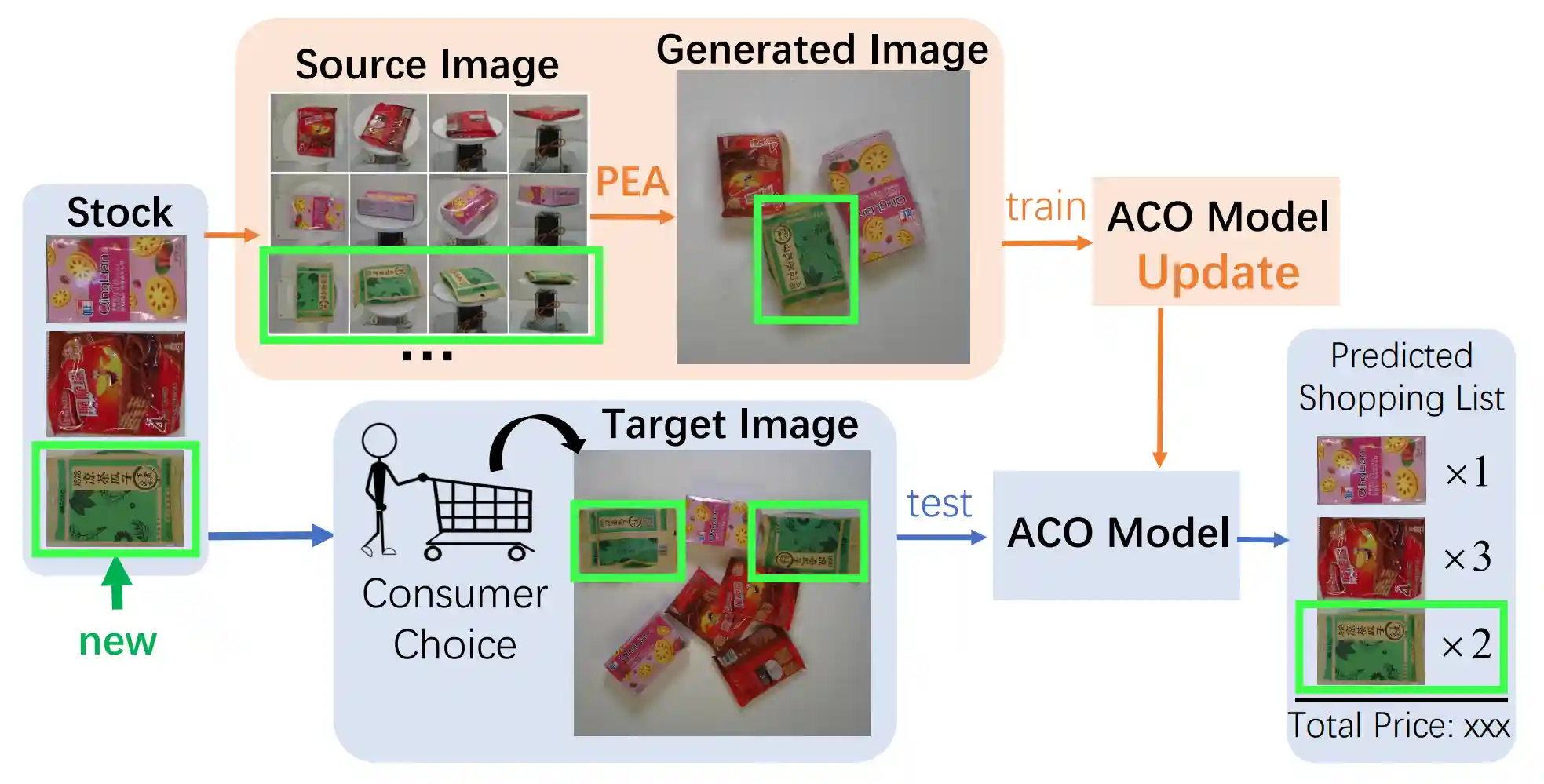
IncreACO: Incrementally Learned Automatic Check-out with Photorealistic Exemplar AugmentationYandan Yang, Lu Sheng, Xiaolong Jiang, Haochen Wang, Dong Xu, Xianbin Cao,WACV 2021 |
|
|
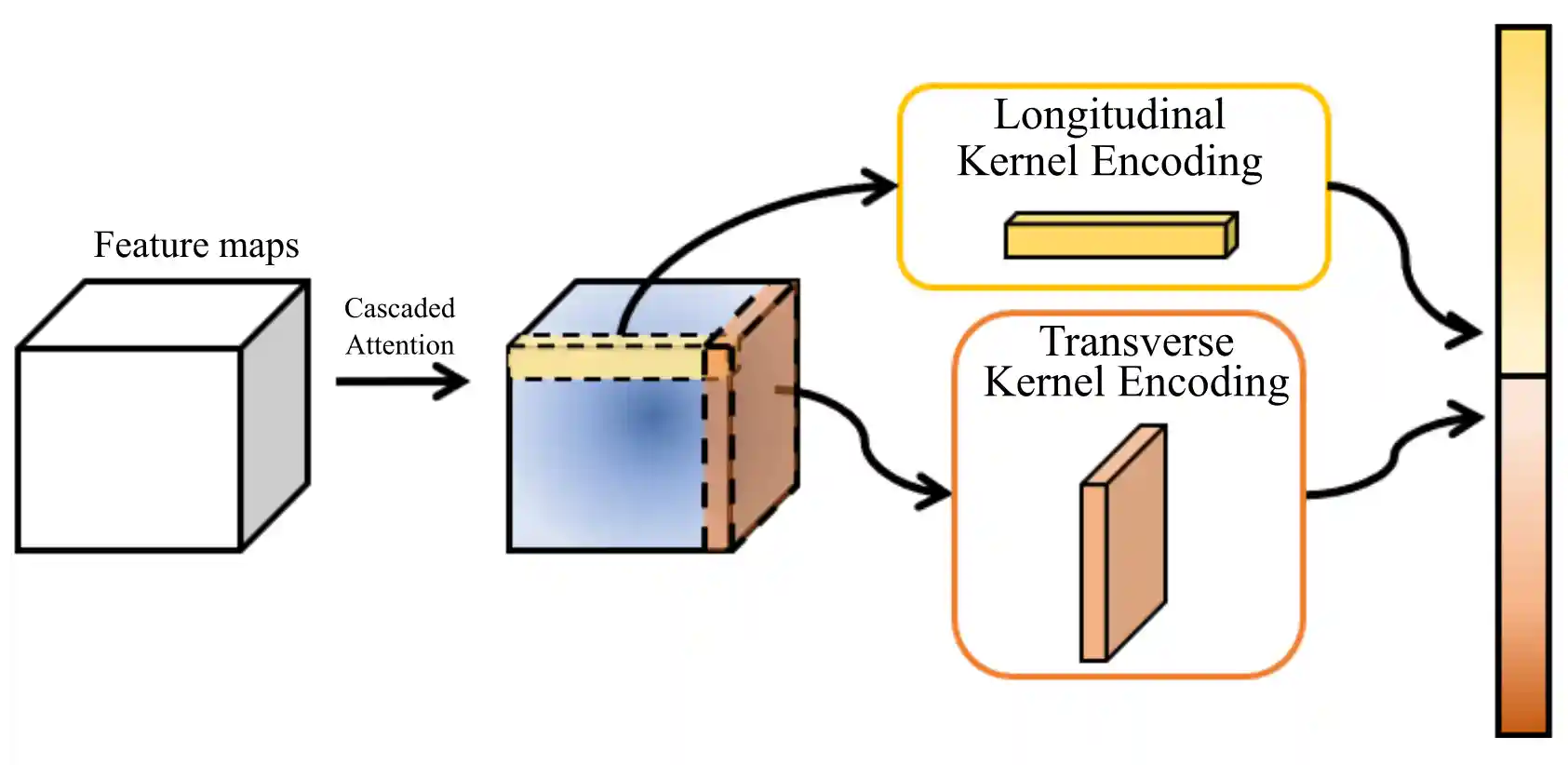
Attentional Kernel Encoding Networks for Fine-Grained Visual CategorizationYutao Hu, Yandan Yang, Jun Zhang, Xianbin Cao, Xiantong Zhen,IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY(IEEE TCSVT) 2021 |
|
|
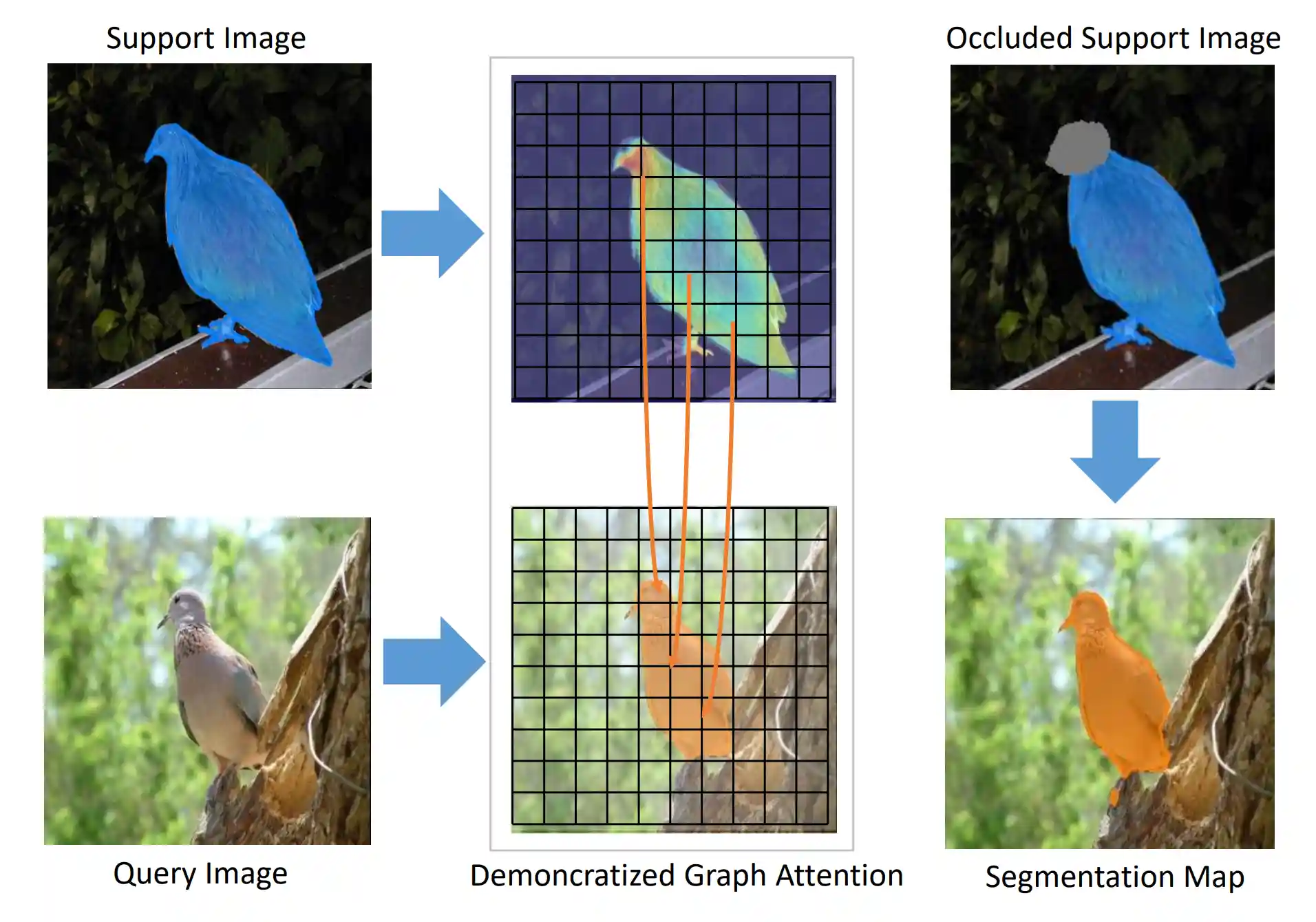
Few-shot semantic segmentation with democratic attention networksHaochen Wang*, Xudong Zhang*, Yutao Hu, Yandan Yang, Xianbin Cao, Xiantong Zhen,ECCV 2020 |